Distributed SQL Sharding: How Many Tablets and at What Size?
June 17, 2022
The first answer to this question is the usual “it depends“. The second answer, thanks to YugabyteDB’s auto-splitting feature and distributed SQL sharding principles, is “don’t worry, this is managed automatically.“
However, it’s still important to understand how sharding works, how to handle corner cases correctly, and how to split tablets to save resources. In this post, we’ll explore how sharding works in YugabyteDB by defining the initial quantity and size of tablets.
What is distributed SQL sharding?
Different databases use the term sharding: from manually isolating data into a few monolithic databases, to distributing little chunks of data across multiple servers. YugabyteDB distributes data by splitting the table rows and index entries into tablets.
In a distributed SQL database, sharding is automatic. You choose the sharding method: range or hash, depending on your access patterns. You can then define the initial number of tablets and split them manually later. Or just let the database auto-split them to follow the growth of data.
But, even in the fully automated case, you may want to tune the knobs that control the splitting algorithm. Or, at the very least, understand them so that your manual actions are not counterproductive. The default settings fit the general case. But even then databases may have a diversity of table number, size, and workload.
What is a tablet?
Before looking at those knobs, you should understand what they control: the number of tablets per server, and their size. It is easy to look at the numbers from YugabyteDB’s yb-master web console.
The /table endpoint shows the total size of the table:

The /tablet endpoint shows all tablets, with their state and their tablet peers (leaders and followers):
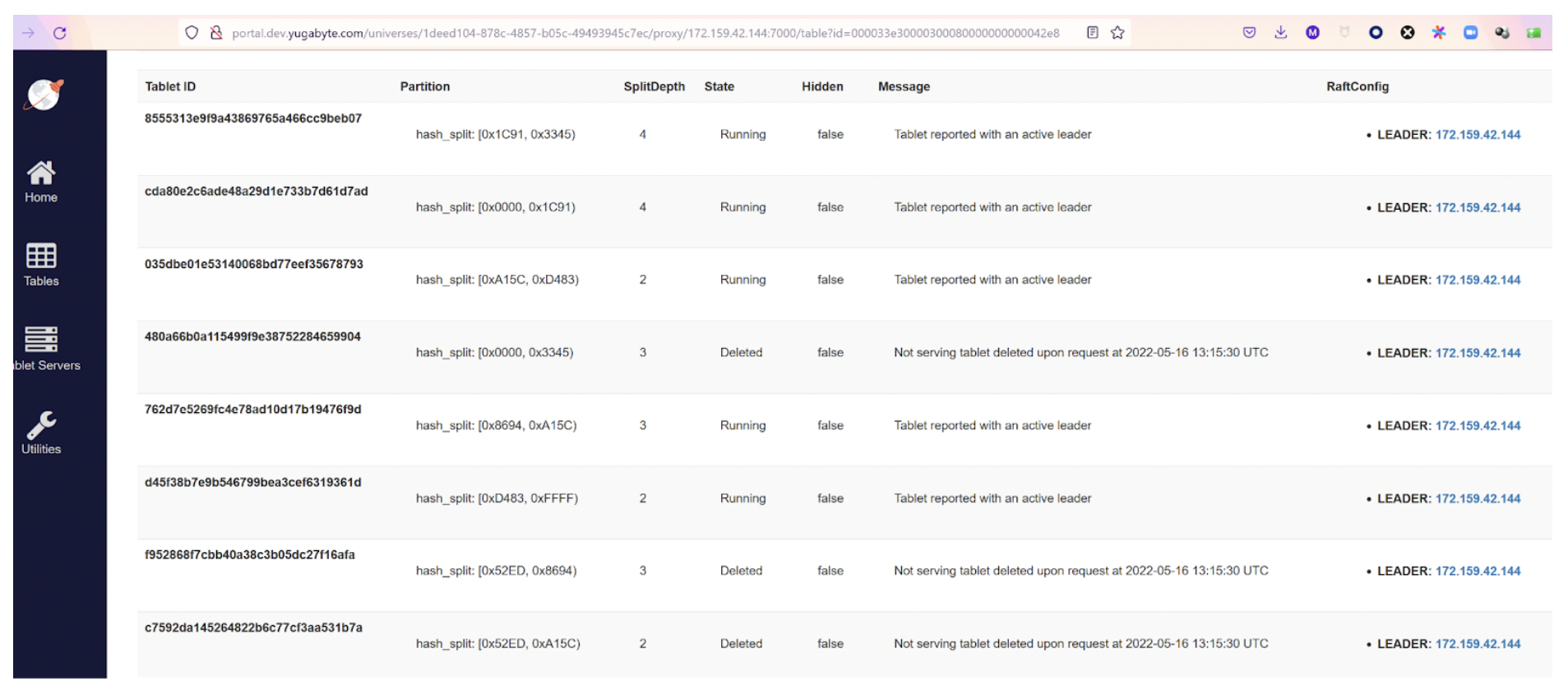
The above screenshots show a table with 35GB on a single node cluster (RF=1) where auto-split has created 8 tablets. They will grow to 10GB each in the “low phase” of auto-splitting. But this is before entering the “high phase” where autosplit is less aggressive.
We didn’t display all of them and we can see some “Deleted” ones from the previous split. Each split increases the SplitDepth which is 1 for the tablets created with the table (or index, or partition) creation. A split is actually an online duplicate, with metadata marking the new bounds. Later, the compaction will clean up the out of bound data on each new tablet.
What do you think about this? What is the right number of tablets and their correct size? A tablet peer is a lightweight database—based on RocksDB—and updated through the tablet’s raft group. By “lightweight”, you can have hundreds of tablets per node, depending on the size of the compute instance, vCPU, RAM, and the storage attached to it. Of course, the activity on them also matters. Not all tables have constant activity even if avoiding hotspots is the goal.
Multiple tablets and elasticity
Having multiple tablets is a must for the elasticity of a distributed database in a cloud native environment. This is where tablets can be automatically relocated when adding new nodes. Limiting the size of tablets is important to avoid huge file transfers when bootstrapping a new peer.
However, each tablet is more than a little chunk of data. Even if they share some threads and memory, the tablets are independent, as they have their own raft group. They send their own heartbeats, and have their own WAL (Write Ahead Logging) protection. They also have their LSM-Tree datastore: a memtable, in RAM, and many SST Files on disk.
The storage for one tablet peer is actually a set of two enhanced RocksDB databases. First, the regular one, for committed data. And second, the intents one, to hold the provisional records and locks until the end of a multi-shard transaction. Each one has some memory allocated on a server. Additionally, the server also needs to keep a large amount of available memory for file buffers.
Finding an ideal tablet size
It’s critical to limit tablet size. But we don’t want too many tablets per server, either. This means that the answer to the ideal size is more than a single number. This is why the knobs to control auto-splitting are defining thresholds with number of tablets and maximum size. To give a rough idea, the ideal maximum tablet size is in tens to hundreds of gigabytes. And one node can hold tens of tablets per vCPU. This, of course, depends on the memory, and how all tablets are active. But before looking at this, it is important to get an idea of the number of tables—and their size—found in SQL databases.
When you build a new modern application, you will develop microservices with their own schema and limited number of tables. But YugabyteDB is PostgreSQL compatible and also used to migrate existing applications to cloud native infrastructure.
Legacy applications are full of extremes. I’ve seen schemas with 60,000 tables and tables—not partitioned—holding billions of rows and terabytes of data. I’ve also seen up to 30 indexes per table. However, there’s a common pattern. In a system of records, the tables break down into a few types: small static tables, medium slowly growing tables, and very large tables.
Small static tables in distributed SQL sharding
A relational schema has plenty of small tables rarely changed—and that do not grow. Those are lookup tables, or reference tables. They will become small dimensions in a data warehouse schema. Additionally, they are usually at the end of many-to-one relationships, sometimes in a multiple-level hierarchy. Some examples of tables in an order-entry application can be countries, cities, and currency rates.
Being small doesn’t mean that you don’t want to distribute them, because they are frequently accessed with joins and you don’t want all queries reading from the same node. However, because they are rarely updated, it is preferable to broadcast them rather than split them. For this, you will probably store the table in one tablet only, and, staying below all auto-split thresholds, they will stay as one tablet covering the whole range of values. But to distribute them, you will create duplicate covering indexes.
Covering means that the index stores all columns, either in the index key or the “include” list, so that the table is never read. Duplicate means that you will create the same index in each region, zone, or data center, through tablespace placement, to get low latency from any connection. The writes will have to update all indexes, but this is fine for infrequent small changes. You still have the advantage of strong consistency and being fully transactional when updated.
In the auto-splitting default configuration (I’m writing this on version 2.13.3) those tables have all their tablet leaders below the tablet_split_low_phase_size_threshold_byte. This is set by default at 512MB and never split into more tablets, even with enable_automatic_tablet_splitting set to true, which is the default in this preview version.
Medium slowly growing tables in distributed SQL sharding
Some tables have frequent read and write activity, but start at a medium size and grow slowly. Those are usually the tables in gigabytes to tens of gigabytes, where sizing needs some consideration. But they usually don’t deserve the complexity of partitioning in a monolithic database. In an order entry application example, you can find the customer and product tables in this category. You’ll want them distributed for added scalability, even if they are not huge.
Entering a “low phase” in auto-splitting
This is when we enter a “low phase” in auto-splitting for tables and indexes with a tablet going over tablet_split_low_phase_size_threshold_byte, which is set by default at 512MB, and measured by the size of SST files in the leader tablet peer. The goal is to aggressively distribute for scalability, especially during initial load, even when they are far from the maximum tablet size desired. However, we don’t want too many tablets either, so this stops for tables reaching the tablet_split_low_phase_shard_count_per_node. This defaults to 8 tablets per server, on average, for one table.
A table, index, or partition, will stay in this “low phase”, with 8 tablets per server on average (calculated as the total number of tablets divided by the number of servers housing tablets). Those tablets will grow until they reach tablet_split_high_phase_size_threshold_bytes, for which the default is 10GB. This will switch the table to the “high phase”. This means that the table will probably reach around 8x10GB=80GB per node before being auto-split again. On a RF=3, with 3 nodes, this means that this table (or index or partition) will take 240GB of space on each node disk for its SST files when we include the followers of the leaders that are in the other nodes.
So, finally, still the low phase for a table taking 720GB in the cluster. On a larger cluster, this size will balance to more nodes, and the table will grow more before reaching the limit of tablets per node. You can see that what I call a “medium” table, staying in the low phase of auto-splitting, can be a large one on a cluster with many nodes. This is why we’ll call the next category “very large table”. But before that, let me explain what a “table” is at the storage level.
Table, index or partition in distributed SQL sharding
Let me clarify what I mean by “table”. A “table” in DocDB, the distributed transaction and storage layer in YugabyteDB that stores the tablet, can be any persistent “relation” from YSQL – the PostgreSQL interface:
- Non-partitioned table
- Non-partitioned index
- Partition (as created by PostgreSQL declarative partitioning) of a table
- The local index of a partitioned table
- A materialized view
If you ever used an Oracle database, you called this a “segment” – the storage part of a persistent database object. But YugabyteDB distributes nodes to scale out on shared-nothing infrastructure.
YugabyteDB uses sharding to distribute data from tables and secondary indexes. Above it, PostgreSQL declarative partitioning—by range or list—controls this distribution. For example, you can limit the distribution of a partition to a local region, for latency or legal purposes. On this topic of auto-splitting and tablet size, we’re talking about distribution, or the tablets in DocDB. Here, non-partitioned tables and indexes or table and index partitions are similar: split, by hash or range, on the primary key for tables or indexed columns for secondary indexes.
(Very) large tables in distributed SQL sharding
The “low phase” of auto-splitting distributes tables in hundreds of gigabytes, depending on the size of the cluster, up to 8 tablets per node, in order to benefit from all CPU power. But, for larger tables, those tablets will grow and split when reaching a size that would be too large for easy data movement. This is where the “high phase” will split again, but on a higher threshold: tablet_split_high_phase_size_threshold_bytes for which the default is 10GB.
And this high phase stops when reaching tablet_split_high_phase_shard_count_per_node which defaults to 24 per node. Again, this “shard count” threshold, to determine the end of the high phase, compares to the number of tablets for the table, divided by the number of servers housing the leaders. And the “size threshold” to determine which tablet to split compares to the sum of SST files (for the regular RocksDB) of the leader.
Controlling auto-splitting for large tables
This phase controls auto-splitting for large tables as they can go to 24x10GB=240GB per node on average, which may be terabytes in a large cluster, and more with replication. Doesn’t sound very large? Don’t forget partitioning. Those very large tables are probably partitioned and the size mentioned here is per-partition.
The tables in this category are the ones that are constantly growing in your system, like the orders and order items in an order entry system. To give an idea, those will become fact tables in a data warehouse. But even in OLTP, if they are not list-partitioned for legal reasons (e.g., by country), they are probably range-partitioned on a date. Because a system of record retains cold data that is less frequently used, you partition by months or years to keep local indexes small. And one day you’ll want to archive or purge the old data and you do that efficiently by dropping the old partitions.Then, the terabytes mentioned above are per partition, for tables in hundreds of terabytes.
Huge tables in distributed SQL sharding
We don’t want tablets to grow indefinitely so that they become too large for operations like bootstrapping on a new node. For this reason, there’s still some split activity after the “high phase” has reached 24 tablets per table per node. But this limit is high: tablet_force_split_threshold_bytes, which is set by default to 100GB.
For databases in hundreds of terabytes, you should take time to think about it and check your system to see the consequences of a high number of tablets. Do you want to continue splitting beyond 24 tablets per server? Or, probably the most relevant for a growing system: will you scale out the cluster? This will rebalance the tablets, reduce the number of tablets per table per server, and then allow auto-split to continue in the high phase. This also depends on the whole schema: how many tables do you have in this huge table category? Will they be all active, or do you have cold data in the old partitions? Did you partition them?
Don’t forget that those thresholds are per database node, so they are still good for large clusters. And they are per table, which means that there will be many more tablets on each node. When you scale-out by adding new nodes, the tablets that were reaching low or high phase thresholds will rebalance and split again.
Conclusion
When porting a legacy application to YugabyteDB with distributed SQL sharding, it is a good idea to qualify the tables and their indexes by the following categories:
- Many small tables with no need to distribute: Create them with a single tablet, or, if there are many of them in a small cluster, think about co-located or table groups
- Small reference tables frequently read, infrequently updated: Broadcast them with duplicate covering indexes, single tablet again
- Medium and large tables, slowly growing: Define hash or range sharding and let auto-split distribute them, as soon as you load them, so that there’s enough tablets to maximize the cluster resources usage
- Very large table growing with business activity: Think about partitioning, with the goal of future archiving or purging, and each partition will follow the large table recommendation
The default thresholds can be changed. However, archiving old data or scaling the cluster is the right approach. When you already know the future capacity, you will save time and resources by defining the initial number of tablets in the CREATE statement. Now that you know when auto-split kicks-in and stops, you know how to reach the “high phase” directly. This is done by multiplying the number of servers by tablet_split_high_phase_shard_count_per_node and defining the number of tablets.
When you have many small tables that are not co-located or in a tablegroup, do not create many tablets for them. This is achieved by SPLIT INTO 1 TABLETS or setting the cluster flag ysql_num_tablets=1 as the default, or simply by enabling auto-splitting as, without a split clause, they start at 1.
All databases are different, so please don’t hesitate to reach out if you need recommendations for your context. Feedback from the community helps adapt to the diversity of use cases.
Got questions? Join our vibrant Community Slack channel to chat with over 5,500 developers, engineers, and architects.

")
