How Xignite Delivers Financial Data at Scale
July 16, 2021
At Distributed SQL Summit Asia, Qin Yu – VP, Engineering, Xignite – presented a talk on how Xignite uses YugabyteDB to power its technology infrastructure to meet the current and future data needs of its financial services and fintech customers.
Xignite – A pioneer in market data innovation
Xignite is on a mission of “making market data easy.” It does this by offering a cloud-based Market Data Management Solution that aggregates and manages market data in the cloud, and distributes this data from the cloud. Xignite provides this data to businesses through cloud APIs and licenses the technology as microservices to customers who want to deliver the data in their own platforms. Xignite serves over 750+ global customers, including financial services (finserv) organizations such as TIAA, Bank of Montreal, BlackRock, Stifel, Schwab and fintech companies such as NICE, Robinhood, SoFi, Betterment, Square, and StockCharts.
Use cases and pain points
Xignite has over 500 APIs that serve over 140 billion data points, processing over 10 billion inbound messages from 150+ global data sources while serving 12 billion API hits a day, translating to over 3 trillion hits a year, i.e. 9 million API requests a minute. Below is a great illustration of what happens in an Internet Minute:

Xignite classifies the data that it gathers into 4 distinct “shapes” – (1) Real-time data – very fast snapshots of data like stock bid and ask price, daily highs and lows, (2) Historical and intraday time series data – summarized data that are used to draw interactive charts, (3) Fundamental data – less frequently changing company information like industry, CEO name, cash flow, income statements, P/E ratios, etc., and lastly (4) Security master and corporate action data – complex data sets that cover corporate actions like splits and dividends, spinoffs, mergers and acquisitions, exchange listings, etc. Xignite needs to optimize its data engine for each type of data. The DSS Asia talk focused on historical and time series data, and corporate action data.
Time series data engine requirements
Figure: Time series data in Robinhood
Xignite customers are looking for time series data to be delivered in a mobile app or a website. As this is an interactive chart, Xignite customers can zoom in or out, creating a need to provide granularity of the data points while also offering a wider array of data points from both an intraday or historical perspective. This requires a scalable database that can handle many TBs of data while also handling massive requests (30,000 per second on average). Customers interact with this data and expect responsiveness, hence latency is critical (sub second latency for 1000+ bars (avg <0.1 sec) from a performance perspective. With Xignite powering 750+ customer applications with data feeds, there is a higher need for this system to be highly reliable and available with low risk of downtime. In addition Xignite needs to meet business requirements of keeping low infrastructure and operational costs.
Challenges faced by using legacy relational databases
Xignite used Microsoft SQL Server and MySQL to store time series data. Rapid growth in data size and usage presented scaling challenges. The scale-up architecture of these monolithic RDBMSs imposed challenges due to the limits of disk size and CPU/memory. To overcome these challenges, the Xignite team implemented data sharding and distribution in the application layer to allow the database to scale out. The team created shards based on the exchange that the data came from. However, different loads from different exchanges led to unbalanced distribution. In addition, applications need to be aware of which database the shard is located on in order to reduce latency, further increasing brittleness and complexity. This application-level sharding also imposed a burden on the operations team to ensure scaling without any downtime. For example, the team needed to stop writes and making the database read-only, move the shards to the new database, update read applications, update write applications, and then re-enable writes – while ensuring this process is done meticulously to avoid any loss of critical data.
Why Xignite chose YugabyteDB for time series data
Xignite chose YugabyteDB as the solution for their time series data engine use case for several reasons:
- YugabyteDB offers better sharding with a hash of the full security identifier
- The application can use the same endpoint to access all shards. This significantly simplifies applications
- It is easy to scale out simply by adding nodes to a YugabyteDB cluster, especially as the data set grows. YugabyteDB takes care of sharding, distributing, and rebalancing data as the cluster grows and shrinks.
- Upgrades, scaling, and rebalancing can be done with zero downtime
- YugabyteDB offers high performance reads and writes for a large volume of data (more on this later)
- YugabyteDB’s scan-resistant Least Recently Used (LRU) cache prevents large scans from affecting low-latency queries
YugabyteDB was able meet Xignite requirements of a highly scalable database, provide better latency, be highly available in addition to providing lower infrastructure and operational costs.
YugabyteDB for Security Master data
Qin also noted that with the successful deployment of YugabyteDB on the Time Series data engine use case, other teams at Xignite that worked on the Security Master data engine got interested in YugabyteDB as a solution. They were also using monolithic RDBMSs (MS SQL Server and MySQL). The workload is characterized by a complex schema with multiple entity levels, multiple asset classes, etc. The database was challenging to scale as additional fields could not be added to support new use cases.
That team selected YugabyteDB as their database solution for a slightly different set of reasons:
- They are using YugabyteDB somewhat like a document database with a generic/flexible schema – generic entities, generic events, lookup tables
- They have a mix of standard fields and jsonb fields
- It is easy to support new data sets without changing the schema
- Unlike other popular document DBs, YugabyteDB offers secondary indexes that enable lookup by entity group, timelineId, etc.
- Again, high performance reads and writes with a large amount of data are essential for all their APIs
YugabyteDB performance at Xignite
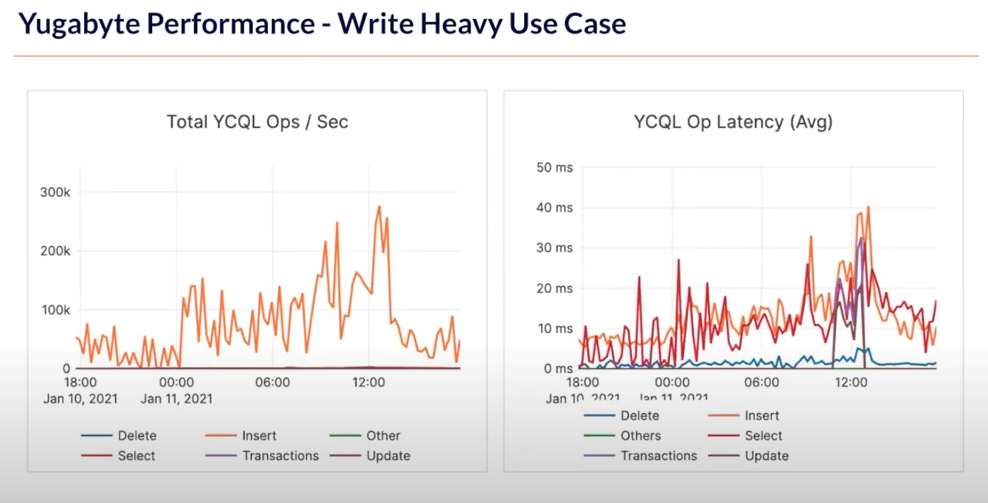
Below is a capture from Xignite’s production system for a write-heavy use case of time series data. At critical points, the database had over 200,000 writes per second, which YugabyteDB was able to deliver with low latency.
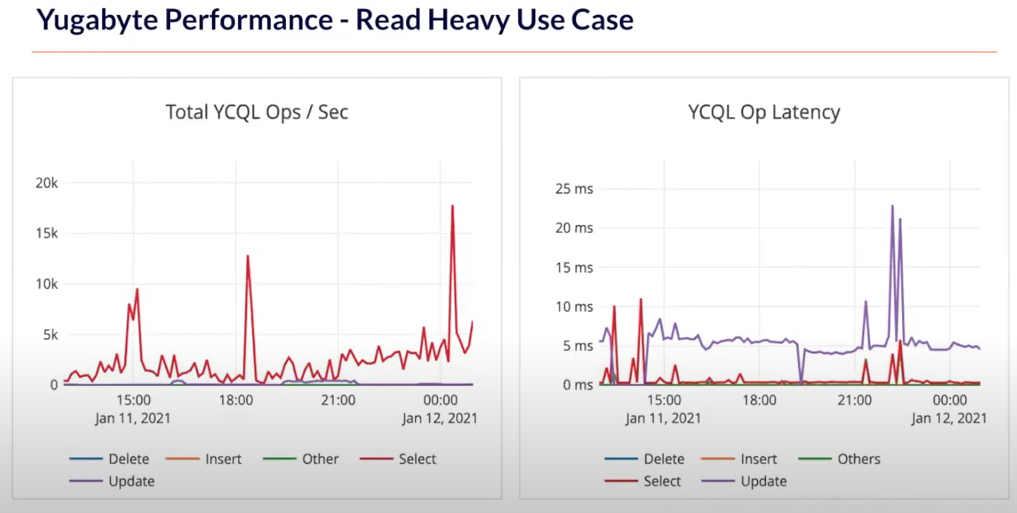
Below is a capture from Xignite’s production system for a “read” heavy use case. Xignite has a Redis cache layer in front of the master data, so the amount of load on the database is not as high compared to the API requests. The database still saw up to 20,000 requests per second, which YugabyteDB handled with average latency well below one millisecond.
Summary
Xignite has been using YugabyteDB for over 2 years. They have fully managed clusters with enterprise support for over 240 cores and over 11 TB of data. Overall, Xignite was able to achieve about 50% cost savings compared to SQL server implementation which allowed the team to explore new cases. With a cost effective solution, Xignite is able to store more data and scale faster.
Want to see more?
Check out all the talks from this year’s Distributed SQL Summit Asia including Walmart, Manetu, Softtech, and more on our Vimeo channel.


