Accelerating YugabyteDB xCluster Adoption: A Leading Bank’s Rapid Assessment Journey
June 13, 2024
Uninterrupted operation is crucial for enterprise applications that handle sensitive data and underpin critical business functions. To safeguard data and guarantee business continuity, a robust disaster recovery (DR) and high availability (HA) plan is essential. In the event of disruption, this plan helps you minimize downtime and avoid data loss.
Yugabyte, the company behind open source PostgreSQL-compatible database YugabyteDB, provides asynchronous replication capability (xCluster), enabling businesses to implement a sound HA and DR strategy.
This blog post deep dives into YugabyteDB’s transactional xCluster capabilities, by exploring the recent experience of a large financial services institution that evaluated and adopted xCluster to achieve business continuity for its critical applications.
Synchronous Replication for Strong Consistency (Default)
A fault domain, in the context of distributed computing systems, is a group of hardware components or software processes that share a common point of failure.
By default, YugabyteDB replicates data across fault domains (which, depending on the deployment, could be nodes, data centers with on-prem deployment or availability zones/regions with cloud deployment).
It replicates data within a single YugabyteDB cluster (aka universe) spread across multiple (three or more) fault domains. This ensures the loss of one fault domain (e.g. data center) does not impact availability, durability, or strong consistency thanks to the Raft consensus algorithm.
However, there are some limitations when using synchronous replication across regions to handle region failure/DR scenarios:
- Increased Write Latency: Due to the consensus protocol involved, write operations may experience a higher latency compared to asynchronous approaches.
- Three Data Center Minimum: The consensus algorithm requires an odd number of data centers to break ties. This necessitates a minimum deployment of three data centers, which adds additional cost.
Asynchronous Replication with xCluster for effective DR
Besides synchronous replication data across fault domains, YugabyteDB offers xCluster – a cross-cluster deployment that provides asynchronous replication across two fault domains (such as data centers or cloud regions).
This approach replicates data between entirely separate universes (essentially, distinct data centers). While data consistency is eventually guaranteed, it may not be reflected instantaneously on the target cluster due to the asynchronous nature. The benefits of this method are:
- Reduced Write Latency: Each cluster uses consensus-based synchronous replication internally for dealing with node or zone failures. However, replication between clusters is asynchronous and doesn’t use/need consensus across potentially distant regions/data centers. This approach has the benefit of lower write latency compared to synchronous replication between distant regions.
- Two Data Center Option: xCluster can function with only two data centers, offering better alignment with a two data center deployment model.
Recommended Deployment Architecture in a Traditional Two Data Center Environment
The Characteristics of Transactional xCluster
Role:
The xCluster role is a property with values ACTIVE or STANDBY that determines and identifies the Primary (source) and Standby (target) universes. Transactional xCluster utilizes two universe roles that can be swapped during failovers:
- Active (Primary): This universe handles both reads and writes. Data is always up-to-date and reflects the latest committed transactions based on chosen isolation levels.
- Standby (Secondary): This universe is read-only, offering access to data at a specific point in time (xCluster safe time). xCluster safe time is the transactionally consistent time across all tables in a given database when Reads are served.
Guarantees:
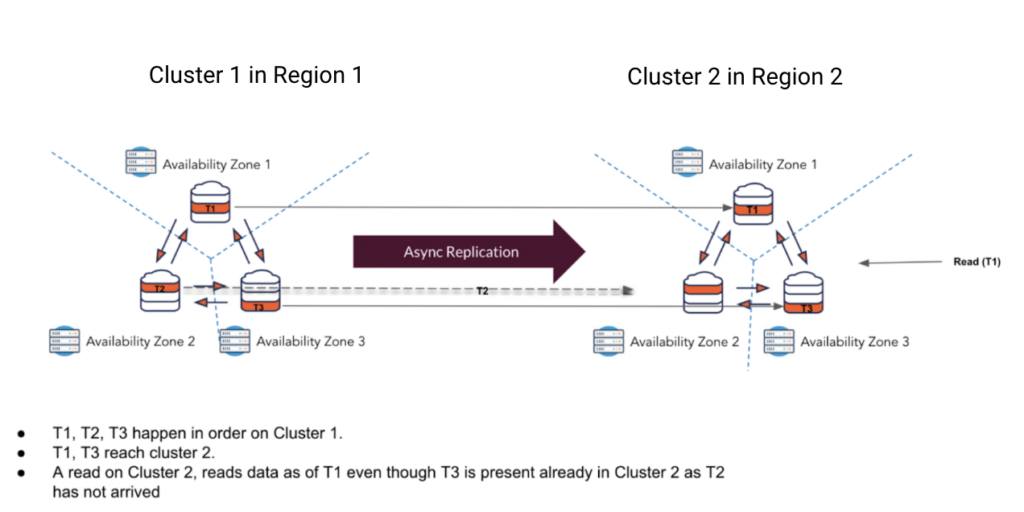
- Transactional Atomicity: A transaction spanning tablets A and B will either be fully readable or not readable on the target universe. A and B can be tablets in the same table, OR a table and an index, OR different tables.
- Global Ordering: Transactions are applied on the standby universe in the same order they were committed on the active universe to maintain data integrity.
Recovery Considerations:
While xCluster offers high availability, it’s asynchronous. This means there is the potential for some data loss (Recovery Point Objective – RPO) during a source universe outage. This loss depends on the time it takes to replicate data (replication lag), which is influenced by network speed between regions.
However, the recovery time objective (RTO) is minimal. Applications simply need to switch their connections to the standby universe, a process that can be optimized for speed.
Technical Requirements
A top bank outlined several key technical requirements for their next-gen solution:
Data Consistency:
- Transactional Atomicity Guarantee
- Global Ordering Guarantee
High Availability:
- Zero Downtime for Maintenance: The system should allow for regular maintenance activities (software upgrades, OS patching) with zero or minimal downtime, adhering to established service level agreements (SLAs).
- Fast Recovery from Failures: The system should recover automatically from node or zone failures within the active data center, meeting the specified SLAs.
Disaster Recovery:
- Rapid Recovery from Data Center Outages: The system should be able to recover from an entire data center failure within the defined SLAs, ensuring business continuity.
Evaluation Process
To gain a deeper understanding of the technical aspects of YugabyteDB, the bank participated in a series of live “Show & Tell” sessions with the Yugabyte team.
These sessions provided valuable insights and addressed their technical questions. The Yugabyte team also supplied them with a best practice playbook, which served as a comprehensive guide for their evaluation process.
Predefined Testing Cases and Success Criteria: Before starting the evaluation, both teams defined clear testing cases with corresponding success criteria:
- Test Scenario #1: Global Ordering Verification
- Objective: Validate that transactions are processed by the DR cluster in the exact order they were committed on the source.
- Success Criteria: Transactions are consistently replicated and reflected on the DR cluster in the same sequence as the source.
- Test Scenario #2: Transactional Atomicity Demonstration
- Objective: Showcase that all steps within a transaction are applied as a single unit on the DR cluster, or not reflected at all if incomplete.
- Success Criteria: Data consistency is maintained. Transactions either fully replicate or appear entirely absent on the DR cluster.
- Test Scenario #3: Switchover Functionality
- Objective: Demonstrate seamless failover from the primary universe (active read-write) to the DR universe (standby read-only) without data loss.
- Success Criteria: Transition to the DR universe occurs smoothly, applications can access data, and no data inconsistencies are detected.
- Test Scenario #4: Failback Process
- Objective: Demonstrate the ability to “fail back” to the primary cluster from the promoted standby universe (Scenario #3).
- Success Criteria: Successful switchover back to the primary universe with applications resuming normal operations and data integrity maintained.
- Test Scenario #5: High Availability Testing
- Objective: Assess the system’s response to various high-availability scenarios, including:
- Sudden node loss or fault domain outage
- Operating system patching
- Database upgrades
- Success Criteria: The system automatically recovers from these events without significant downtime or data loss. Applications should continue functioning with minimal disruption.
- Objective: Assess the system’s response to various high-availability scenarios, including:
Preparing a Dedicated Testing Environment: Provisioned on-premise infrastructure:
- YugabyteDB Cluster configuration: 6-node cluster for both primary and secondary clusters with each node: 16 vCPU / 64 GB RAM
- Yugabyte Anywhere servers: 2 servers to set up high availability with each server: 8 vCPU / 32 GB RAM / 250GB disk space
- Two application servers with each server: 8 vCPU / 32 GB RAM
- Common shared storage of 10TB: Both clusters need to be able to access it
Efficient Test Case Execution: The evaluation team executed the test cases effectively, following these key steps:
- Rapid xCluster Setup: They leveraged Yugabyte’s best practice runbook to set up xCluster replication within an hour. To simulate real-world conditions, they pre-populated the primary database with a 200GB dataset, mirroring the size and complexity of their tier-one application’s data.
- Monitoring and Alerting: They defined metrics and thresholds for monitoring replication performance. This included CPU, memory, disk space usage, replication lag, node status, and more. This allowed them to proactively identify any potential issues.
- Data Manipulation and Consistency Checks: Using a pre-selected JDBC application, they performed various data manipulations (insert, update, delete) and implemented automated consistency checks between the primary and secondary databases. This ensured data accuracy and consistency throughout the testing process.
- High Availability Testing: To assess the primary database’s resilience, they simulated node failures (server crashes, node removal/reinsertion). They observed automatic recovery without impacting ongoing workloads or replication.
- Failover Testing: Following the runbook, they conducted switchover and failover drills. This showcased xCluster’s key characteristics:
- Low RTO (Recovery Time Objective): Minimal downtime during switchover.
- Zero Data Loss (Switchover): Data integrity maintained during switchover.
- Non-Zero RPO (Recovery Point Objective) with Unplanned Failover: Potential for some data loss during unplanned outages due to asynchronous replication. However, data consistency is restored upon resynchronization.
- Load and Stress Testing: They ran concurrent large batch loads (totaling 800GB) while monitoring disk space usage and replication performance. This demonstrated the system’s ability to handle heavy workloads while maintaining a low replication lag (around 300-500ms).
- Comprehensive Documentation: Throughout the testing process, the team meticulously documented results, execution steps, and any artifacts generated. This detailed record provided valuable insights for future reference.
Evaluation Outcome: YugabyteDB Exceeded Expectations
The bank’s meticulous analysis of test results, measured against predefined objectives and benchmarks, confirmed that YugabyteDB not only met but exceeded their expectations.
This comprehensive evaluation led them to select YugabyteDB as their strategic solution to ensure enhanced business continuity and growth.
Several key factors influenced their decision:
- Scalability for Future Data Growth: YugabyteDB’s distributed architecture effectively addressed the institution’s projected data volume increase.
- Superior Customer Experience: YugabyteDB’s high availability and disaster recovery capabilities promised to minimize downtime and disruptions, ensuring a seamless customer experience – a critical concern after past technical issues.
- YugabyteDB’s Feature Alignment: The combination of distributed architecture, high availability features, and xCluster replication across two data centers perfectly aligned with the institution’s needs for scalability, reliability, and an improved customer experience.
YugabyteDB’s robust feature set provided a clear path for the financial institution to achieve their business goals and deliver a superior customer experience.
Lessons Learned and Best Practices
The bank’s successful two-week evaluation of YugabyteDB xCluster provides valuable insight for others considering this solution. The key takeaways are:
- Start with Clear Goals: Define your expectations upfront. This includes factors like:
- Effectiveness of setting up and managing xCluster
- Application testing framework and transactional consistency requirements
- Estimated size of initial data loading and ongoing data replication volume
- Acceptable lag tolerance range
- Monitoring and alerting parameters
- Peak load and transactions per second (TPS)
- Targeted Testing: Develop specific testing objectives. This could involve:
- Verifying transactional consistency for distributed transactions and global ordering
- Evaluating failover procedures and effectiveness
- Assessing performance under load conditions
- Rigorous Test Design: Create well-defined test cases with clear success criteria.
- Dedicated Testing Environment: Set up a dedicated environment specifically for testing.
- Follow Best Practices: Utilize the Yugabyte team’s runbook for effective test case execution.
By following these recommendations, organizations can expedite and harden their evaluation process for YugabyteDB xCluster, and gain a clear understanding of whether it meets their specific needs.
Additional Resources
- Create your own evaluation process using The Yugabyte xCluster Playbook
- Watch this step-by-step guide, which discusses how you can use the xCluster DR (Anywhere) with two cloud regions in Azure.


