DSS Europe 2023 Recap: An Event to Remember (Mark Your Calendar for Next Year!)
May 31, 2023
This year, we co-located one of our Distributed SQL Summit (DSS) Europe events at KubeCon + CloudNativeCon Europe in Amsterdam. Given the large crowds, we condensed our event into two half day sessions to accommodate everyone who wanted to attend!
To ensure we addressed everyone’s interest and concerns, we enrolled our audience into a poll highlighting the challenges identified by YugabyteDB users and evaluators. Here are the percentages of participants who recognized these challenges in their roles.

Knowing that our audience would primarily consist of KubeCon delegates immersed in building modern microservices, we tailored our event to align with their perspective. Recognizing their focus is on the value delivered by the database, we centered our discussions and demonstrations around how our distributed SQL database effectively addresses their key challenges (see questions above). But, I have to admit that I got a bit carried away with our polling app and added a quiz at the end of each of the six demonstrations. The result was two very engaging and interactive sessions.
How many fault zones are needed for a resilient YugabyteDB Universe?
In the first session, we asked “Why should I care about distributed SQL?” 57% of attendees could relate to that, and that set the scene.
And why should you care? Because without it you have to compromise your data layer. Do you give up transactions and hope that eventual consistency is enough (non-relational)? Should you have to give up cloud native scale-out and in-built resiliency (legacy relational)? Or, do you lock yourself in the walled garden of your CSP (cloud DB)?
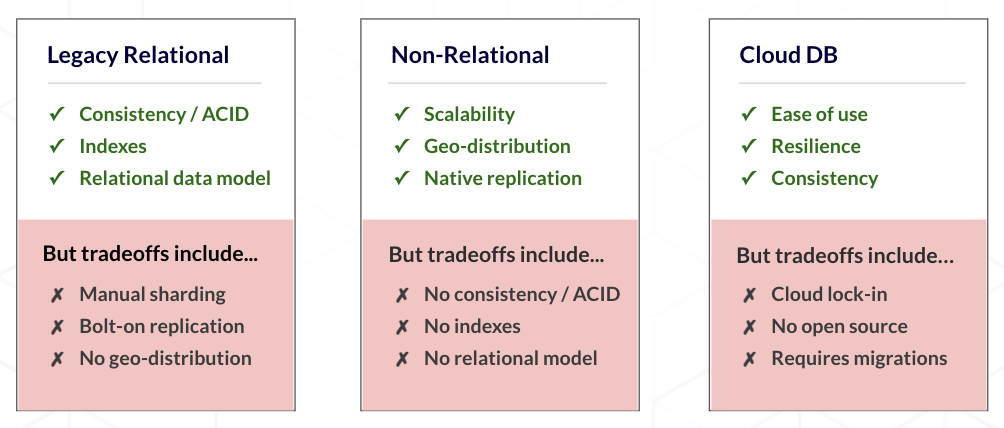
If you don’t want to compromise, you embrace YugabyteDB distributed SQL (elastic scale-out, built-in automatic replication to deliver resiliency, and run-anywhere open source deployment).
No compromise and how many fault zones? Three. If you lose any single replica of any part of the data, the database just keeps running, while it repairs itself.
What is the uplift in throughput when a YugabyteDB Universe is doubled?
Next up was Yugabyte EMEA Field CTO David Walker. David dug deep into how YugabyteDB eliminates the data layer compromise. Then Dave Roberts and Wierd van der Haar (two heavy-hitting Yugabyte Customer Solution Architects) ran through several demos:
| 1. Define and start a new cluster |
| 2. Run the TPCC benchmark app against the cluster |
| 3. Scale it vertically (switch out each of the three 8-core nodes, in turn, to replace them with 16-core nodes) |
| 4. Scale it out horizontally (add three more 16-core nodes) |
| 5. Scale it back down |
| 6. Go behind the scenes to the underlying AWS account and knock over a node and watch the database just keep going |
We watched the transaction rate of the benchmark app, which gave me my quiz question: What’s the uplift?
Turns out it’s a pretty linear 90%+. David then underlined that point with some customer throughput and scaling numbers from a variety of real-world workloads.
Which database does YugabyteDB Voyager not support as a source for migrating to YugabyteDB: PostgreSQL, Oracle, or DB2?
After a coffee break, it was back to more demos! And more quizzes (and prizes).
We knew our audience would not tolerate death-by-powerpoint, so the session continued with Dave and Wierd on keyboards and David on vocals (well, commentary, but it doesn’t sound quite as rock and roll that way).
David made a very powerful point that no matter how cool your shiny new database is, if you can’t migrate your existing apps and their data to it, it’s going to end up on the shelf.
That was the cue to introduce YugabyteDB Voyager—our recently-released database migration solution. YugabyteDB Voyager is an acknowledgement that we succeed when our customers succeed. If they’ve got a portfolio of hundreds of databases, we’d better be prepared to make the migration journey as swift, sure, and painless as possible.
But, YugabyteDB Voyager isn’t just a push-the-button-and-hope tool. It defines a disciplined approach and explicitly includes the inevitable manual tweaks needed to map a 25-year-old schema from an idiosyncratic SQL dialect into PostgreSQL (for example)—and we know many of our customers have plenty of those!

The first release of Voyager supports PostgreSQL, Oracle (many versions), MySQL, and multiple CSP databases. Those are the ones we meet most in our customer base. We’re not stopping with that list – we just haven’t got to “Big Blue” (i.e. DB2) quite yet.
Which data stores does YugabyteDB support? Relational? Wide Column? JSON Document?
Of course, migrating the data is only part of the program. The apps on the database are often a much bigger challenge. David talked a lot about the merits of simple lift-and-shift of monolithic apps versus refactoring them into a more cloud-friendly microservices architecture.
As David pointed out, lift-and-shift is really only a stop-gap at best. It doesn’t deliver all the benefits and can increase the risk. So, when it came to demo time, Dave picked up an existing microservices app. The app he chose was a standard Springboot app from the MongoDB website that they helpfully publish the Github repository.
PostgreSQL has support for JSON column types and YugabyteDB adds additional layers for features like native document field indexing. So, this wasn’t the challenge to data storage that you might have expected.
Dave had to change the drivers and the connection definitions in the source code, but that was all. The highlight for our developer audience was the code comparison between the before and after. I was surprised it was so easy and Dave finished by running the app successfully (of course!).
In fact, all the demos were a success. No hotel wifi failed, no one kicked out a mains lead, and most importantly the product just stood up and did what it says on the tin.
Actually for me, as a veteran of a million stage demos over more decades than I care to admit to, the most important factor was complete invisibility. It was the skill, effort, and focus that David, Dave, Weird, and the entire Yugabyte team brought to the event. These guys are the EMEA Yugabyte customer tech team and bring that level of commitment to every engagement.
Everyone knows that our commitment to PostgreSQL and our Cassandra CQL support has been critical to some of our biggest customers. The document-store app migration was a deliberate choice that gave the clue to my final quiz answer. YugabyteDB does support Relational Tables, Wide Column and JSON data stores!
Both audience sets, morning and afternoon, seemed pleased with our efforts. Over the next two days at our [KubeCon + CloudNativeCon Europe] booth, we had follow-up conversations with many of the DSS attendees and had new conversations with people they connected us with. It was a great show for us and more solid evidence of the relevance and importance of distributed SQL for the fast-moving and demanding world of operational microservices applications. So if you already have plans to attend KubeCon in 2024, check out our DSS sessions. You will be glad you did.


