Designing for Low-Latency Reads with Duplicate Covering Indexes
May 14, 2024
Let’s start this blog by considering a use case scenario that requires active-active application deployments across multiple regions supported by a YugabyteDB database cluster spanning three regions. While a multi-region YugabyteDB cluster provides region-level resiliency, how can you also ensure low-latency reads in this topology? Easy.
YugabyteDB features geographically located duplicate covering indexes that optimize for low-latency reads by ensuring they occur in the same region where an application is deployed. This is especially useful in a multi-region application and database deployment.
The design approach described below guarantees applications consistently experience low-latency, consistent reads while avoiding stale data reads. However, this design will have implications for write latency due to cross-region traffic and the need to write multiple copies across multiple regions.
What is a Duplicate Covering Index?
A duplicate covering index is a type of covering index where the schema of the index is the same as the table. A covering index is an index that includes all the columns required by a query, allowing you to perform index-only scans.
When you run applications from multiple regions, you can use duplicate indexes in conjunction with tablespaces in a multi-region cluster to greatly improve read latencies. The process involves creating different tablespaces with preferred leaders set to each region and creating duplicate indexes and attaching them to each of the tablespaces. This results in immediately consistent multiple duplicate indexes with local leaders.
Duplicate covering indexes are global. They have replicas in all regions of the cluster topology and each of them can have a preference of one region pinning the leaders to that region. This makes the index DR safe and resilient.
However, it is important to note that while reads are performant, there is a write latency impact due to additional index objects that need to be updated.
Duplicate Covering Indexes in a 3-Region YugabyteDB Cluster—An Example
Let us look at this design pattern using YugabyteDB as an example. As you can see in the image below, I have a YugabyteDB cluster in three regions —West, Central, East, and two preferred regions in Central and East with RF=3.
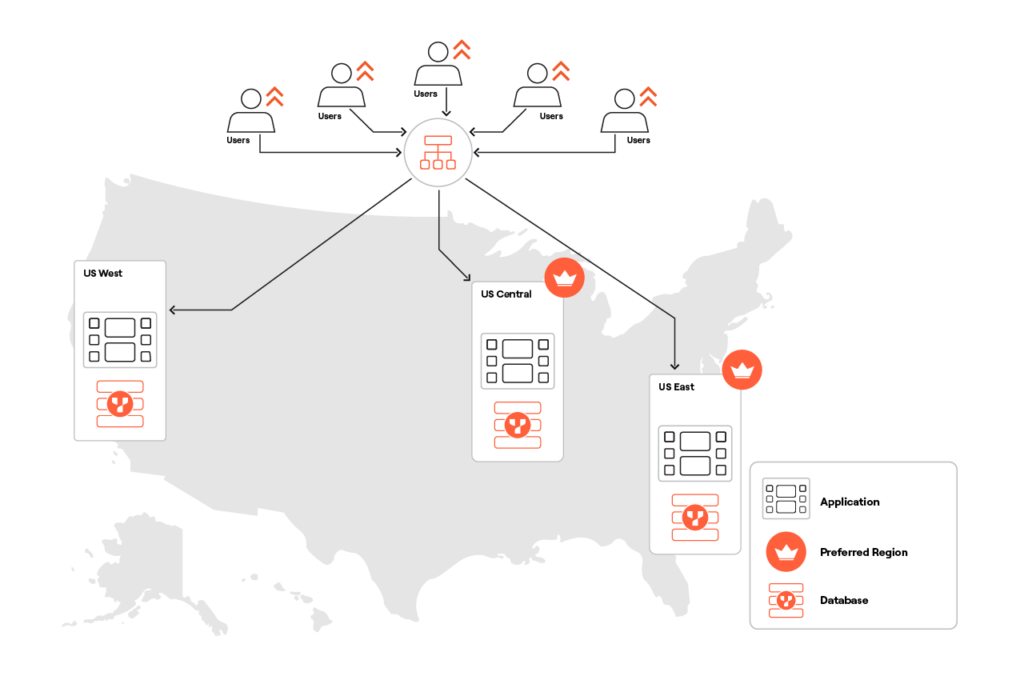
I created the table below and inserted 100 rows of data into it.
CREATE TABLE users( id int PRIMARY KEY, name text, email text, fedid int ); insert into users(id, name, email,fedid) select i, i::text, i::text || '@gmail.com', floor(random()*9001 + 100)::int from generate_series(100,200) i
Let’s assume that the queries used in the app are:
'SELECT name, email from users where id = some-value;'— querying by primary key'SELECT name, email from users where fedid = some-value;'— querying by secondary key
Without duplicate covering indexes, these queries can be routed to a database node that’s in a region other than the one where the application is deployed, but there is a cost in terms of latency. This is because of tablet leader placements within the cluster. In this example, the tablet leaders will be placed in Central and East which are the two preferred regions (see image above). An application deployed in West will send its queries to the leaders in East or Central, resulting in latencies > 30ms.
Now let’s look at how application reads from the West can be made more performant.
Lower Read Latency With Duplicate Covering Indexes
Reads can be made faster by defining duplicate covering indexes. A duplicate covering index can (well) duplicate a primary key index or a secondary key index. For duplicate covering indexes on the primary key, the index will have the same structure as the table and the index column the same as the primary key column. A duplicate covering index on secondary indexes will have an index column based on the application’s access patterns. These duplicate covering indexes will then be pinned to specific regions using the TABLESPACE feature in YugabyteDB.
>>>>Control the Placement of Data with Tablespaces>>>
Here are the steps –
- Create a Tablespace in the region which is not set as the preferred region. In my example, the tablespace is called west and will have leader preference in West.
CREATE TABLESPACE west WITH ( replica_placement= '{ "num_replicas" : 3, "placement_blocks" : [ {"cloud":"gcp","region":"us-west1","zone":"us-west1-a","leader_preference":1,"min_num_replicas":1}, {"cloud":"gcp","region":"us-east1","zone":"us-east1-b","min_num_replicas":1}, {"cloud":"gcp","region":"us-central1","zone":"us-central1-a","min_num_replicas":1} ]}'); - Create a duplicate index with the same structure as the table, index column same as the primary key of the table. Duplicate indexes for a unique or primary key must all be declared unique since it is used not only to enforce the constraint but also for the query planner estimations. Pin the index to the appropriate tablespace.
CREATE UNIQUE INDEX idx_users_west on users(id) include (name,email) tablespace west;
- Since there is a query using
fedidcolumn, repeat step 2 for secondary index onfedidcolumnCREATE INDEX idx_users_fedid_west on users(fedid) include(id, name, email) tablespace west;- Table description using
\d+ usersinysqlshwill look like this:Table "public.users" Column | Type | Collation | Nullable | Default | Storage | Stats target | Description --------+---------+-----------+----------+---------+----------+--------------+------------- id | integer | | not null | | plain | | name | text | | | | extended | | email | text | | | | extended | | fedid | integer | | | | plain | | Indexes: "users_pkey" PRIMARY KEY, lsm (id HASH) "idx_users_west" UNIQUE, lsm (id HASH) INCLUDE (name, email), tablespace "west" "idx_users_fedid_west" lsm (fedid HASH) INCLUDE (id, name, email), tablespace "west" - With this setup, a query from an application deployed in the East that uses an indexed column in the filter will automatically be routed to its geo-local copy of the duplicate covering index. This can be examined and confirmed by running
Explain (analyze, dist)on the queries.yugabyte=# explain (analyze, dist) select name,email from users where id =144; QUERY PLAN ---------------------------------------------------------------------------------------------------------------------------- Index Only Scan using idx_users_west on users (cost=0.00..4.11 rows=1 width=64) (actual time=0.725..0.727 rows=1 loops=1) Index Cond: (id = 144) Heap Fetches: 0 Storage Index Read Requests: 1 Storage Index Read Execution Time: 0.617 ms Planning Time: 0.069 ms Execution Time: 0.765 ms Storage Read Requests: 1 Storage Read Execution Time: 0.617 ms Storage Write Requests: 0 Catalog Read Requests: 0 Catalog Write Requests: 0 Storage Flush Requests: 0 Storage Execution Time: 0.617 ms Peak Memory Usage: 24 kB (15 rows) Time: 1.457 ms yugabyte=# explain (analyze, dist) select name,email from users where fedid =4443; QUERY PLAN ----------------------------------------------------------------------------------------------------------------------------------- Index Only Scan using idx_users_fedid_west on users (cost=0.00..5.06 rows=10 width=64) (actual time=0.699..0.701 rows=1 loops=1) Index Cond: (fedid = 4443) Heap Fetches: 0 Storage Index Read Requests: 1 Storage Index Read Execution Time: 0.589 ms Planning Time: 0.065 ms Execution Time: 0.740 ms Storage Read Requests: 1 Storage Read Execution Time: 0.589 ms Storage Write Requests: 0 Catalog Read Requests: 0 Catalog Write Requests: 0 Storage Flush Requests: 0 Storage Execution Time: 0.589 ms Peak Memory Usage: 24 kB (15 rows) Time: 1.389 ms
- Table description using
In Summary…
As you can see, for applications that need to be deployed across multiple regions, you can enable low latency reads on the latest data by using Duplicate Covering Indexes in YugabyteDB. However, it is important to remember the tradeoff of them is that writes are expensive, due to synchronous writes to additional index objects in the strongly consistent YugabyteDB database.
There are also other design patterns like follower reads and read replicas that will serve low latency reads and can be used where a certain level of data staleness in reads is tolerable. Understanding your application’s requirements plays a crucial role in choosing the right design pattern and the duplicate covering index approach provides strong consistency with latest data and local read performance at a cost to writes.
This solution is the best one for fairly static tables like reference tables that need strongly consistent reads when updated. For other tables the tradeoff of low latency reads and higher latency writes needs to be evaluated on a case-by-case basis and the appropriate design pattern adopted.
Additional Resources
Duplicate Indexes: Enhance the Performance of Global Applications
Ready to experience the power and simplicity of YugabyteDB for yourself?
Sign up for our free cloud DBaaS offering today at cloud.yugabyte.com. No credit card required, just pure database innovation waiting to be unleashed!
 Ready to experience the power and simplicity of YugabyteDB for yourself?Sign up for our free cloud DBaaS offering today at cloud.yugabyte.com. No credit card required, just pure database innovation waiting to be unleashed!
Ready to experience the power and simplicity of YugabyteDB for yourself?Sign up for our free cloud DBaaS offering today at cloud.yugabyte.com. No credit card required, just pure database innovation waiting to be unleashed!

