Seven Multi-Region Deployment Best Practices
May 3, 2023
Although public clouds have come a long way since the inception of AWS in 2006, region and zone outages are still fairly common, happening once or twice a year (cf. AWS Outages, Google Outages).
YugabyteDB is a distributed SQL database that can be deployed in a single-region, multi-zone configuration. Replicas are maintained across multiple fault zones to maintain high availability in case of zone outages. You can deploy YugabyteDB across different regions, so that applications can easily handle region outages without affecting your customers. However, having a cluster spread across geographically distant locations can have some downsides, such as increased latency.
In this blog, I’ll look at some best practices to reduce latencies and improve performance in a multi-region deployment. Or, if you like, watch one of our recent Friday Tech Talks where we cover the same subject.
Explore additional YugabyteDB Friday Tech Talks
Reducing Latency with Preferred Leaders
YugabyteDB splits table data into tablets. Each tablet is replicated across different fault zones and one instance is elected as the leader. This leader is responsible for handling reads and writes, and for replicating the data to its peer replicas.
Let’s consider a multi-region cluster where you have the cluster distributed across three regions: us-east, us-central, and us-west. Let’s say we have one table with three tablets. By default, the tablet leaders are placed across the three regions in a load-balanced manner like this.
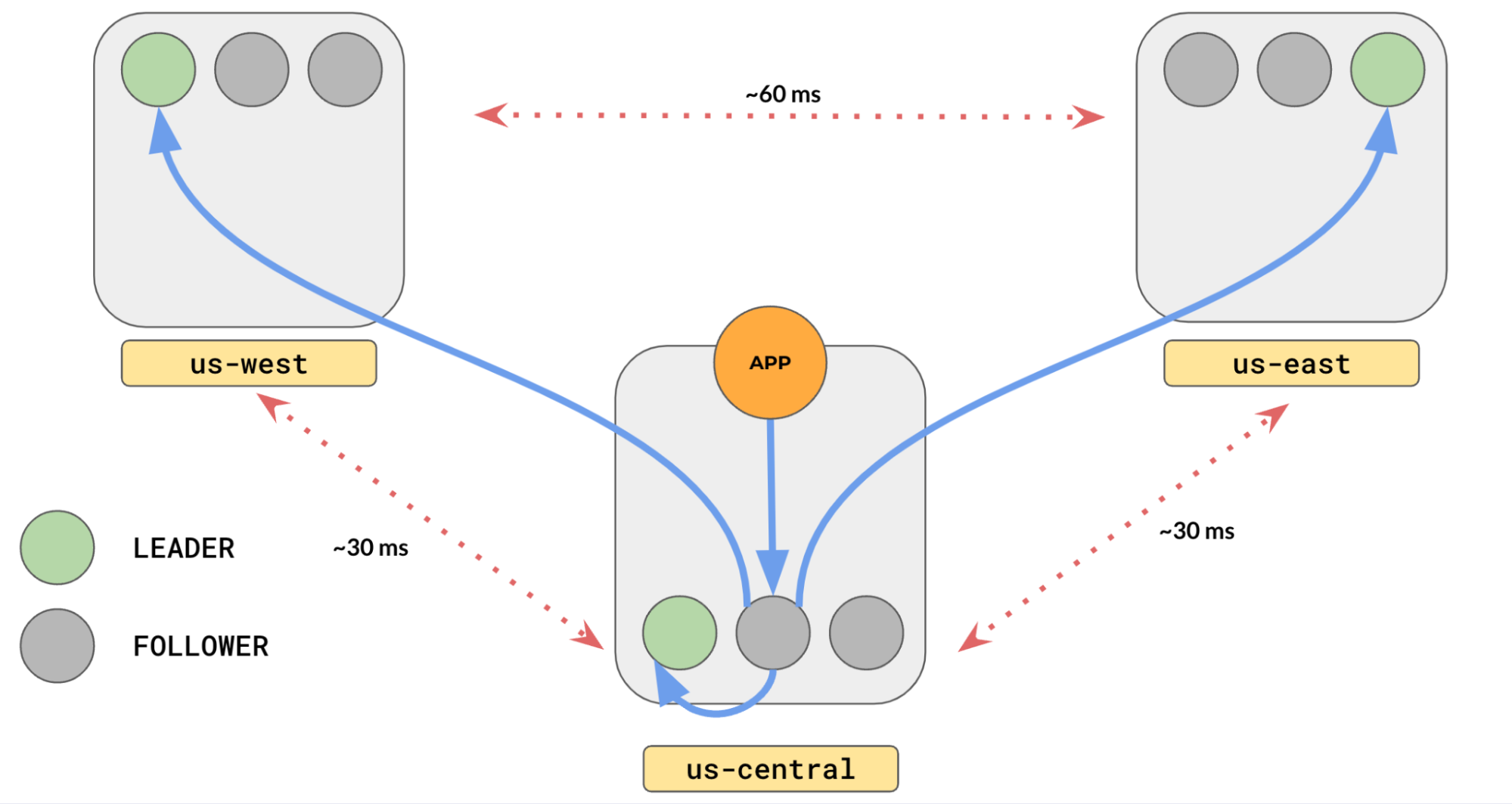
If you have an application running in us-central, it would have to reach out to leaders in the us-east and us-west to fetch the data these leaders are responsible for. Your queries would have to unnecessarily bear the latency to go from us-central to us-east or us-central to us-west.
Typically, inter-region latencies run in the order of tens of milliseconds (10-100ms). Wouldn’t it be great if all the leaders were in the us-central region?
YugabyteDB lets you configure your cluster, so all the leaders can be placed in the region or subset of regions you choose. This is called Leader Preference. Let’s place our leaders in us-central as that is where our application runs via the set_preferred_zones command in yb-admin:
# yb-admin set_preferred_zones <cloud.region.zone>:<preference> % yb-admin set_preferred_zones aws.us-central.us-central-1a:1
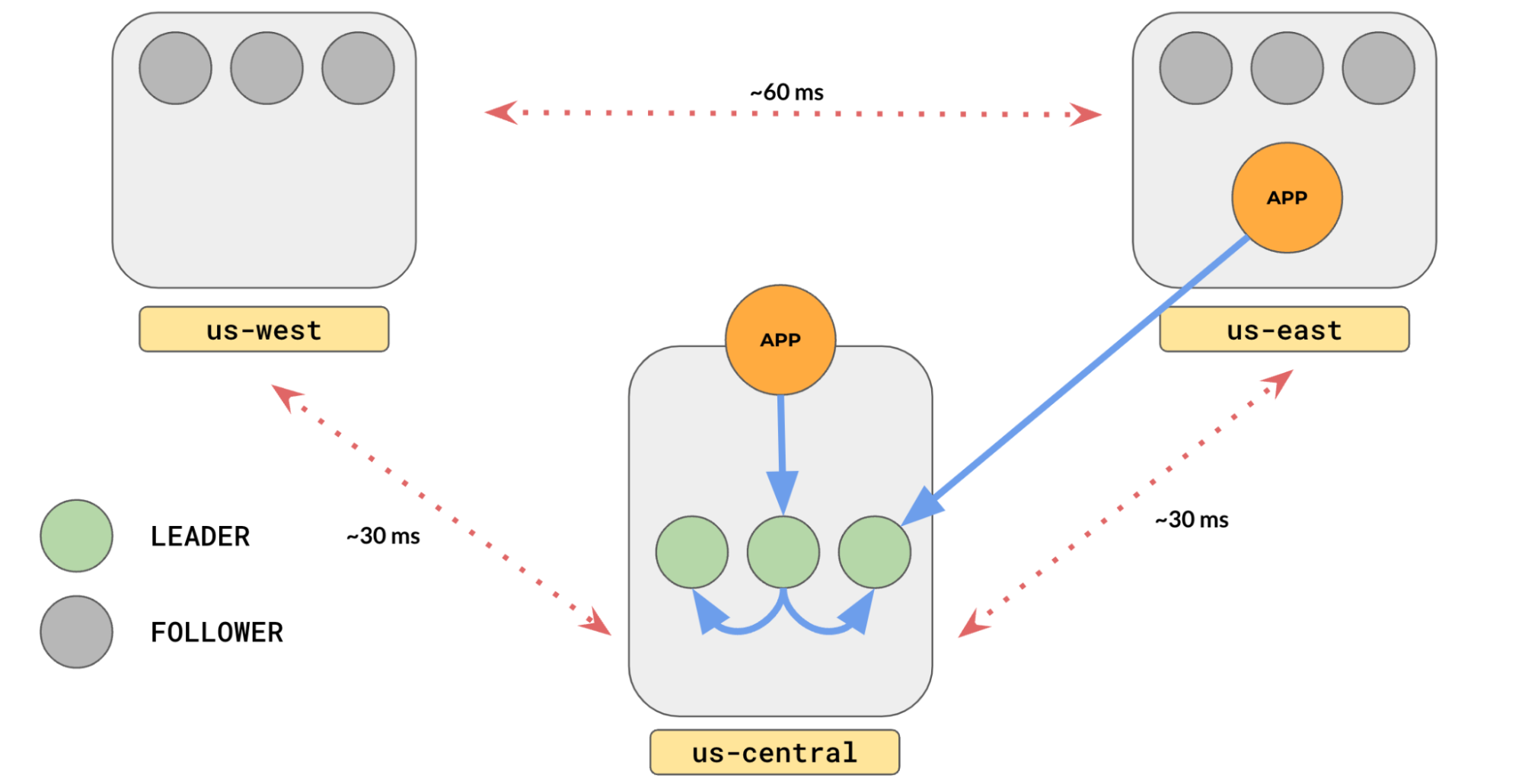
As you can see, all of the leaders are in the us-central. The latency between the application and the tablet leaders reduces to a few milliseconds (typically 1-2 ms). Now, the us-central serves all data, and the rest of the regions just serve as replicas.
If your applications are running in two regions, you might want to set up leader preference, so that the tablet leaders are split across just the two regions.
But, even in this scenario, setting the leader preference to a single region would be advantageous. The internal rpcs would be restricted to only one region because all the leaders would be in the same region. The application would have to incur the cross-region latency only once per query, and all the internally distributed queries would be automatically restricted to just one region!
Remember, setting leader preference at the cluster level (using the yb-admin command) cluster affects all databases and tables in that cluster. We will see in later sections how this can be set at a finer-grained level using the concept of tablespaces.
Further Information:
Reducing Read Latency with “Follower Reads”
All reads in YugabyteDB, by default, are handled by the leader to ensure that the applications fetch the latest data, even though the data is replicated to the followers. Replication is fast, but not instantaneous. So, all followers may not have the latest data at the read time. There are a few scenarios where reading from the leader is not necessary.:
- The data does not change often (eg. movie database)
- The application does not need the latest data (eg. yesterday’s report)
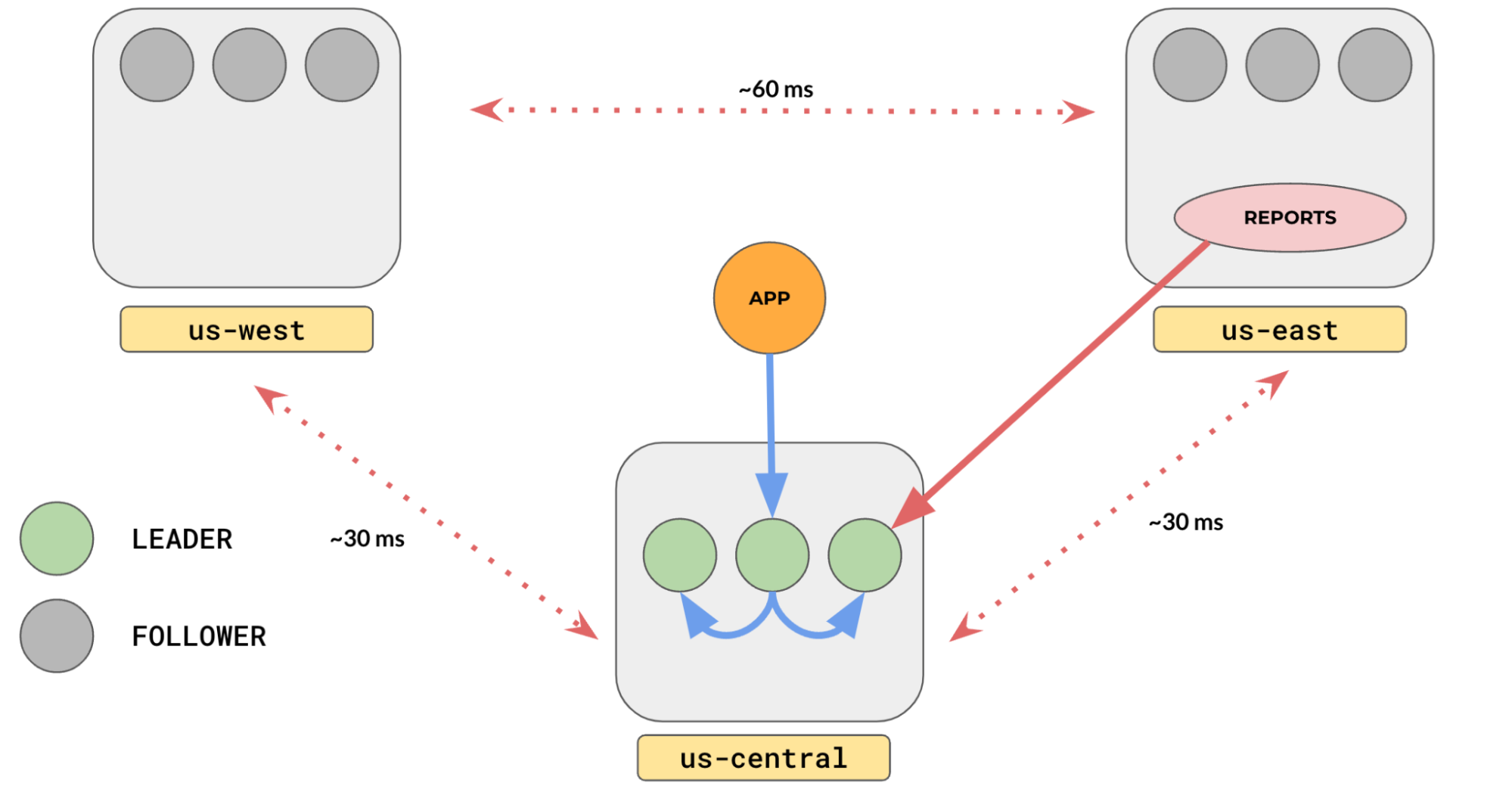
In such scenarios, you can enable follower reads in YugabyteDB to read from follower replicas instead of going to the leader, which could be far away in a different region. To enable this, all you have to do is set the transactions to be read-only and turn ON a session-level setting yb_read_from_followers like:
set session characteristics as transaction read only; SET yb_read_from_followers = true; -- Now, this select will go to the followers SELECT * FROM demo WHERE user='yugabyte'
This will read data from the closest follower or leader. As replicas may not be up-to-date with all updates, by design, this might return slightly stale data (default: 30s). This is the case even if the read goes to a leader. The staleness value can be changed using another setting—yb_follower_read_staleness_ms like:
SET yb_follower_read_staleness_ms = 10000; -- 10s
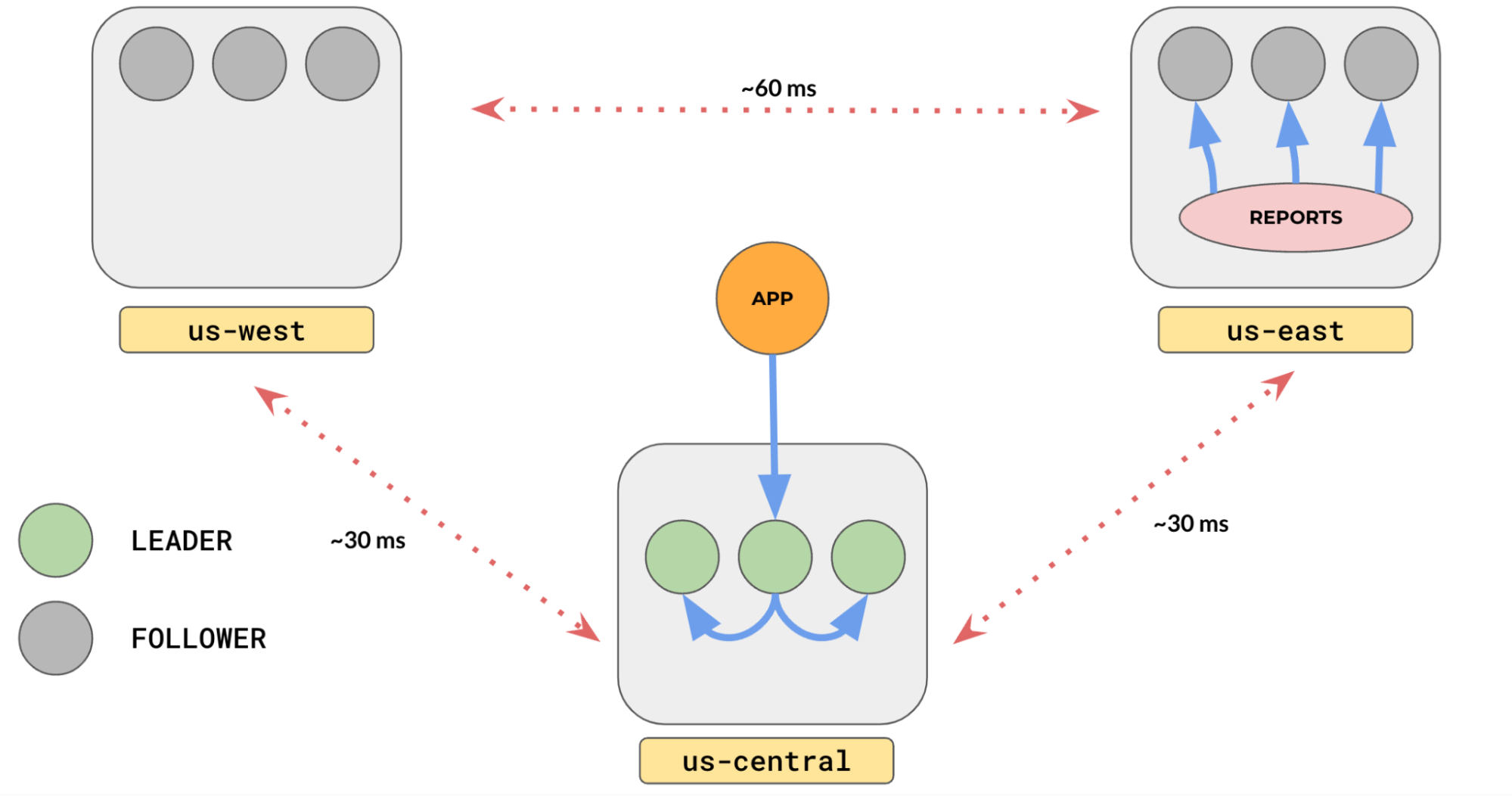
Depending on your cluster setup, this can hugely improve your read performance.
Note: This is only for reads. All writes still go to the leader.
Further Information:
Localizing Data with Tablespaces
By default, all tables are distributed across all fault zones defined for the cluster. There may be scenarios where you just want some tables to be located in specific regions/zones, or have a different replication factor, or different leader preferences.
In these cases, tablespaces come to the rescue. In YugabyteDB, the notion of PostgreSQL tablespaces is extended to help define data placement of tables for a geo-distributed deployment. This allows users to specify the number of replicas for a table or index, control placement, and get better performance. Replicating and pinning tables in specific regions can lower read latency and achieve compliance with data residency laws.
Let’s consider a scenario where you have two tables, with one table containing data for users in Europe, and the other containing data for users in the US.
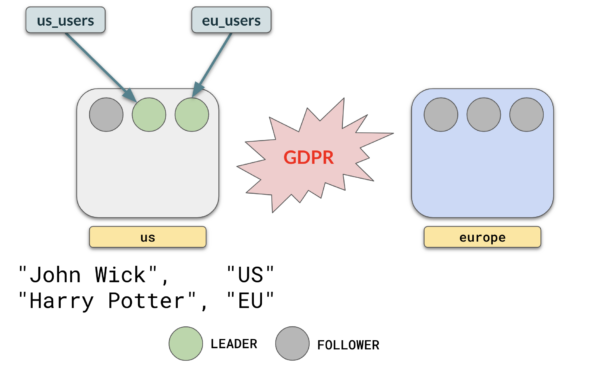
With tablespaces, you can have table us_users in the US and eu_users just in Europe by creating appropriate table spaces and attaching tables like this.
CREATE TABLESPACE europe WITH (
replica_placement= '{
"placement_blocks" : [
{"cloud":"aws","region":"eu-west", "zone":"eu-west-1a"},
{"cloud":"aws","region":"eu-east", "zone":"eu-east-1b"},
{"cloud":"aws","region":"eu-central","zone":"eu-central-1c"}
]}');
CREATE TABLESPACE us WITH (
replica_placement= '{
"placement_blocks" : [
{"cloud":"aws","region":"us-west", "zone":"us-west-1a"},
{"cloud":"aws","region":"us-east", "zone":"us-east-1b"},
{"cloud":"aws","region":"us-central","zone":"us-central-1c"}
]}');
CREATE TABLE eu_users(...) TABLESPACE europe;
CREATE TABLE us_users(...) TABLESPACE us;This would enforce the tables to be distributed as follows:
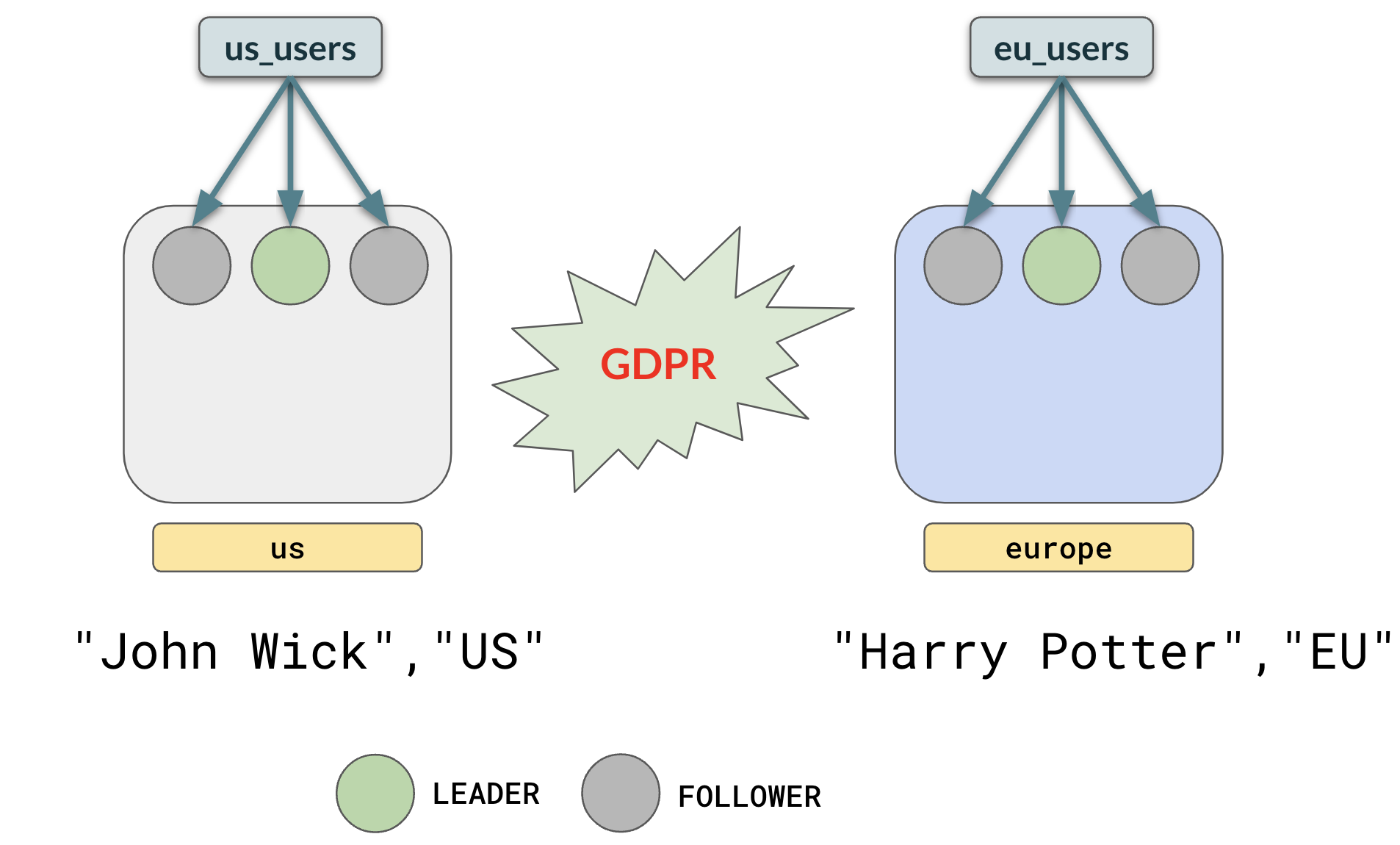
Note: Tablespaces also work with indexes and not just tables.
Further Information:
Row Placement with Geo-Partitioning
In the tablespaces section, we placed a table with all the European users in Europe. This may not be an acceptable schema for all applications. You might want to have data of users from different countries (eg. US/Germany/India) in the same table, but just store the rows in their regions to comply with the country’s data-protection laws (eg. GDPR), or to reduce latency for the users in those countries.
For this, YugabyteDB supports row-level geo-partitioning. This combines two well-known PostgreSQL concepts, partitioning, and tablespaces. The idea is to partition your table according to the geo-locality, then attach each partition to a different tablespace to store the partition in a specific location.
Let’s say we have a table of users, which has user data from the US and Germany. We want the data of all German users to be in Europe, and the data of all US users to be located in the US.
- Create the Tablespaces:
-- tablespace for europe data CREATE TABLESPACE eu WITH ( replica_placement='{"num_replicas": 3, "placement_blocks":[ {"cloud":"aws","region":"eu-west","zone":"eu-west-1a","min_num_replicas":1}, {"cloud":"aws","region":"eu-east","zone":"eu-east-1b","min_num_replicas":1}, {"cloud":"aws","region":"eu-central","zone":"eu-central-1c","min_num_replicas":1} ]}' ); -- tablespace for us data CREATE TABLESPACE us WITH ( replica_placement='{"num_replicas": 3, "placement_blocks":[ {"cloud":"aws","region":"us-east","zone":"us-east-1b","min_num_replicas":1}, {"cloud":"aws","region":"us-west","zone":"us-west-1a","min_num_replicas":1}, {"cloud":"aws","region":"us-central","zone":"us-central-1c","min_num_replicas":1} ]}' ); - Create the parent table with a partition clause:
CREATE TABLE users ( id INTEGER NOT NULL, geo VARCHAR, ) PARTITION BY LIST (geo);
- Create child tables for each of the geos in the respective tablespaces:
-- US partition table CREATE TABLE us_users PARTITION OF users ( id, geo, PRIMARY KEY (id HASH, geo)) ) FOR VALUES IN ('US') TABLESPACE us; -- EUROPE partition table CREATE TABLE eu_users PARTITION OF users ( id, geo, PRIMARY KEY (id HASH, geo)) ) FOR VALUES IN ('EU') TABLESPACE eu;
Now, the user data will be placed in the different regions like this:
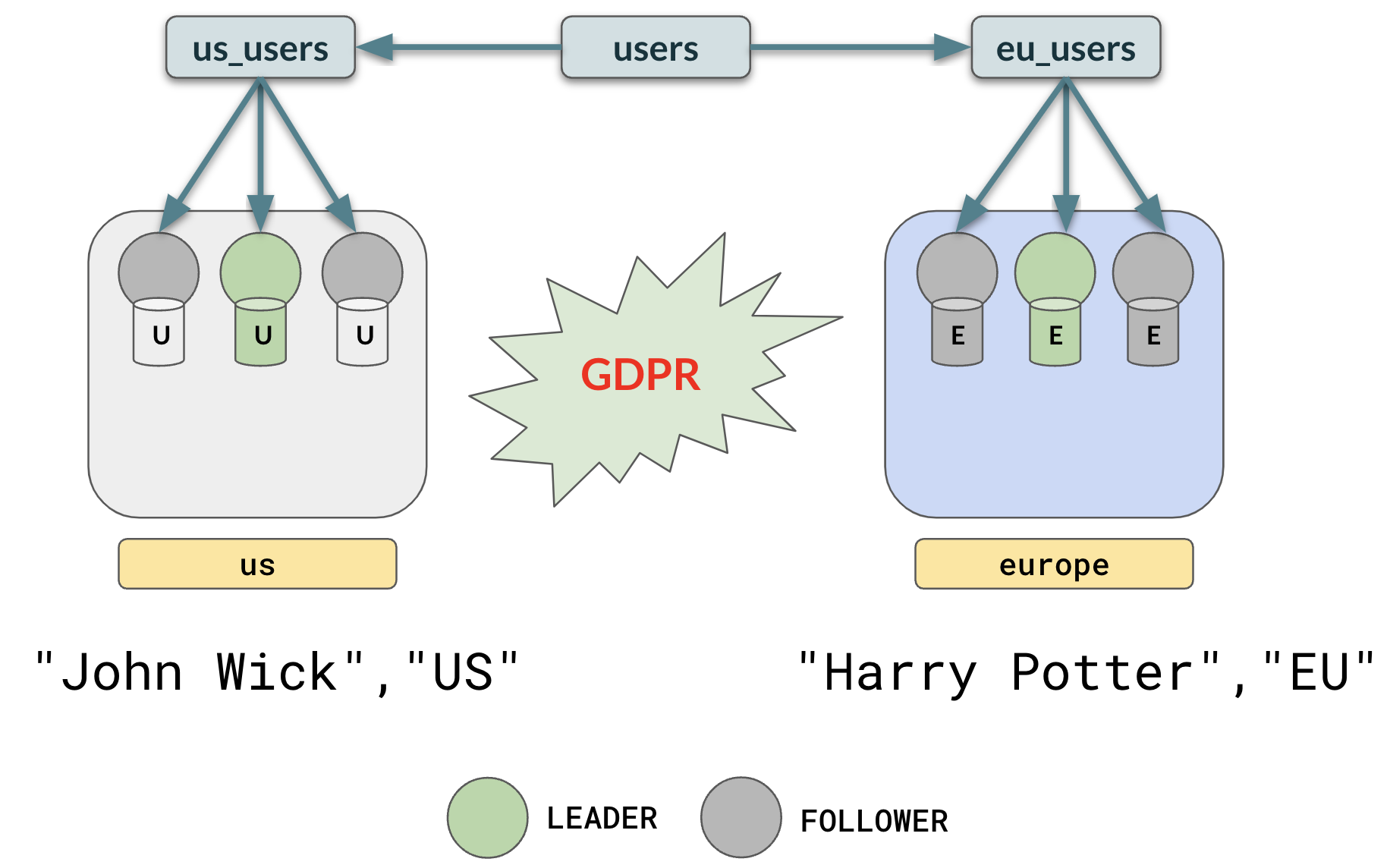
To find the geo of a user
-- To get the geo of an id: Will search all partitions SELECT geo FROM users WHERE id = 10; -- optimal way: search local partition first and then try others. SELECT geo FROM users WHERE id = 10 and yb_is_local_table(tableoid) UNION ALL SELECT geo FROM users WHERE id = 10 LIMIT 1;
Once you have the geo, you can restrict queries to that geo by adding a geo condition like:
-- To get the geo of an id: Will search all partitions SELECT * FROM users WHERE id = 10 AND geo='EU';
Instead of explicitly specifying values like EU/US for geo, it would be easier to use the yb_server_region built-in function to get the local region information and set it as the geo column.
Further Information:
Avoid Trips to the Table with Covering Indexes
When an index is created on some columns of a table, those columns will be a part of the index. Any lookup involving just those columns will skip the trip to the table for further data fetch. But, if the look-up involves other columns not part of the index, the query executor has to go to the actual table to fetch the columns. Consider the following example:
-- Users table CREATE TABLE users ( id INTEGER NOT NULL, name VARCHAR, city VARCHAR, PRIMARY KEY(id); ); CREATE INDEX idx_name ON users (name); -- index scan + table lookup SELECT id, city FROM users WHERE name='John Wick'; | 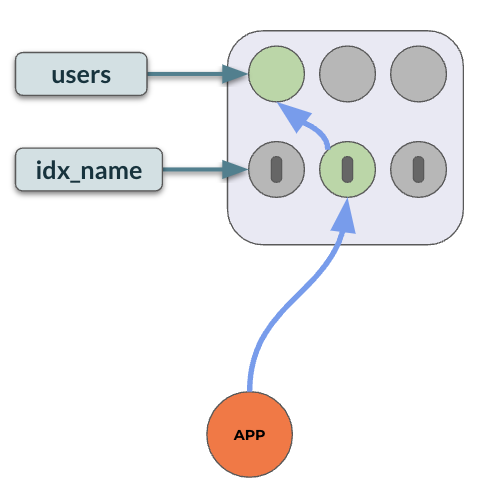 |
This trip could become expensive depending on the latency needs of your application. You can avoid this by creating a covering index that includes all the necessary columns in the index itself. This will result in an index-only scan.
-- To get the geo of an id : Will search all partitions CREATE INDEX idx_name ON users (name) INCLUDE (id, city); -- index only scan SELECT id, city FROM users WHERE name='John Wick'; | 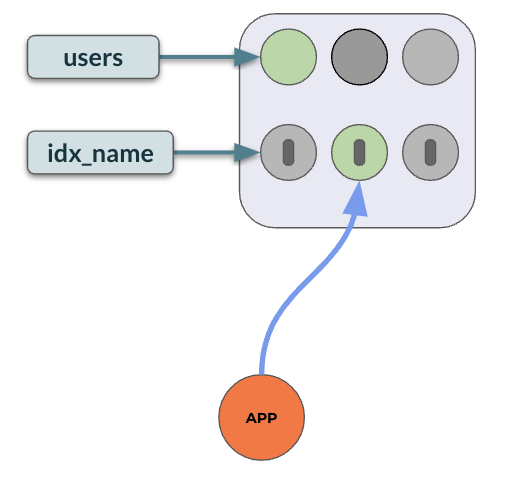 |
With the covering index, the lookups are restricted just to the index. A trip to the table is not required as the index has all the needed data.
Further Information:
Duplicate Covering Indexes
All reads go to the leader by default in YugabyteDB. So, even though the replicas are available in other regions, applications will have to incur cross-region latency if leaders are distributed across regions.
We saw in an earlier section how we could circumvent the issue by having all leaders in one region. But, what if your app needs to be deployed in multiple regions and provide low latency, strongly consistent reads for all your users? To handle such situations, it’s advisable to generate several identical covering indexes and store them in tablespaces that span the same set of regions but only differ in which region is the “preferred leader” region.
Let’s consider the following scenario, where you have a users table present in three regions and your applications deployed in these three regions.
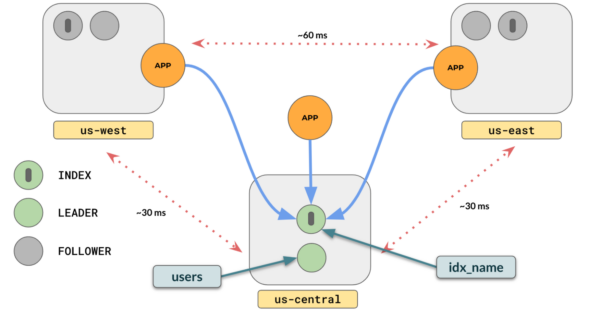
To make the index data available in multiple regions (say us-west, us-central, us-west) for consistent reads, follow these steps.
- Create multiple tablespaces (one for every region you want your index leader to be located in) and set leader preference to that region: Note: even though the leader_preference is set to a region, you should place the replicas in other regions for outage scenarios, depending on your application setup.
-- tablespace for west data CREATE TABLESPACE west WITH ( replica_placement= '{ "num_replicas" : 3, "placement_blocks" : [ {"cloud":"aws","region":"us-west","zone":"us-west-1a","leader_preference": "1"} {"cloud":"aws","region":"us-east","zone":"us-east-1a"} {"cloud":"aws","region":"us-central","zone":"us-central-1a"} ]}'); -- tablespace for central data CREATE TABLESPACE central WITH ( replica_placement= '{ "num_replicas" : 3, "placement_blocks" : [ {"cloud":"aws","region":"us-west","zone":"us-west-1a"} {"cloud":"aws","region":"us-east","zone":"us-east-1a",} {"cloud":"aws","region":"us-central","zone":"us-central-1a","leader_preference": "1"} ]}'); -- tablespace for east data CREATE TABLESPACE east WITH ( replica_placement= '{ "num_replicas" : 3, "placement_blocks" : [ {"cloud":"aws","region":"us-west","zone":"us-west-1a"} {"cloud":"aws","region":"us-east","zone":"us-east-1a","leader_preference": "1" {"cloud":"aws","region":"us-central","zone":"us-central-1a"} ]}'); - Create multiple covering indexes and attach them to region-level tablespaces.
CREATE INDEX idx_west ON users (name) INCLUDE (id, city) TABLESPACE west; CREATE INDEX idx_east ON users (name) INCLUDE (id, city) TABLESPACE east; CREATE INDEX idx_central ON users (name) INCLUDE (id, city) TABLESPACE central;
This will create three clones of the covering index, with leaders in different regions and at the same time replicated in the other regions. You will get a setup similar to this:
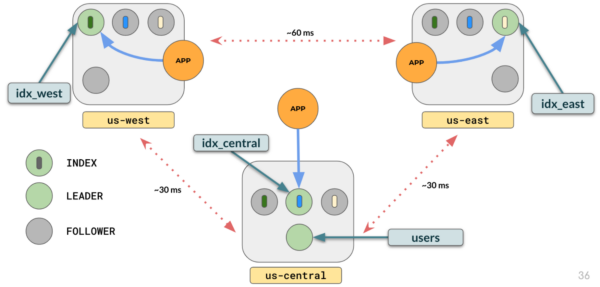
The query planner will use the index whose leaders are local to the region when querying. (Note: The query planner optimizations related to picking the right index by taking into consideration the leader preference of the tablespace in which the index lives is available from 2.17.3+ releases).
As you have added all of the columns needed for your queries as part of the covering index, the query executor will not have to go to the tablet leader (in a different region) to fetch the data. One important thing to note is, having multiple indexes across regions will increase write latency, as every write would have to add data into each of the indexes across regions. So, this technique is useful for lookup tables where data does not change much.
Further Information:
- Maintain a Duplicate Covering Index in a Region (Article)
- Covering Indexes in YugabyteDB—Documentation
Load Balancing with Smart Driver
YugabyteDB’s Smart Driver for YSQL provides advanced cluster-aware load-balancing capabilities that can greatly simplify your application and infrastructure. Typically, to load balance across a set of nodes you would need a separate load balancer through which all requests have to be routed.
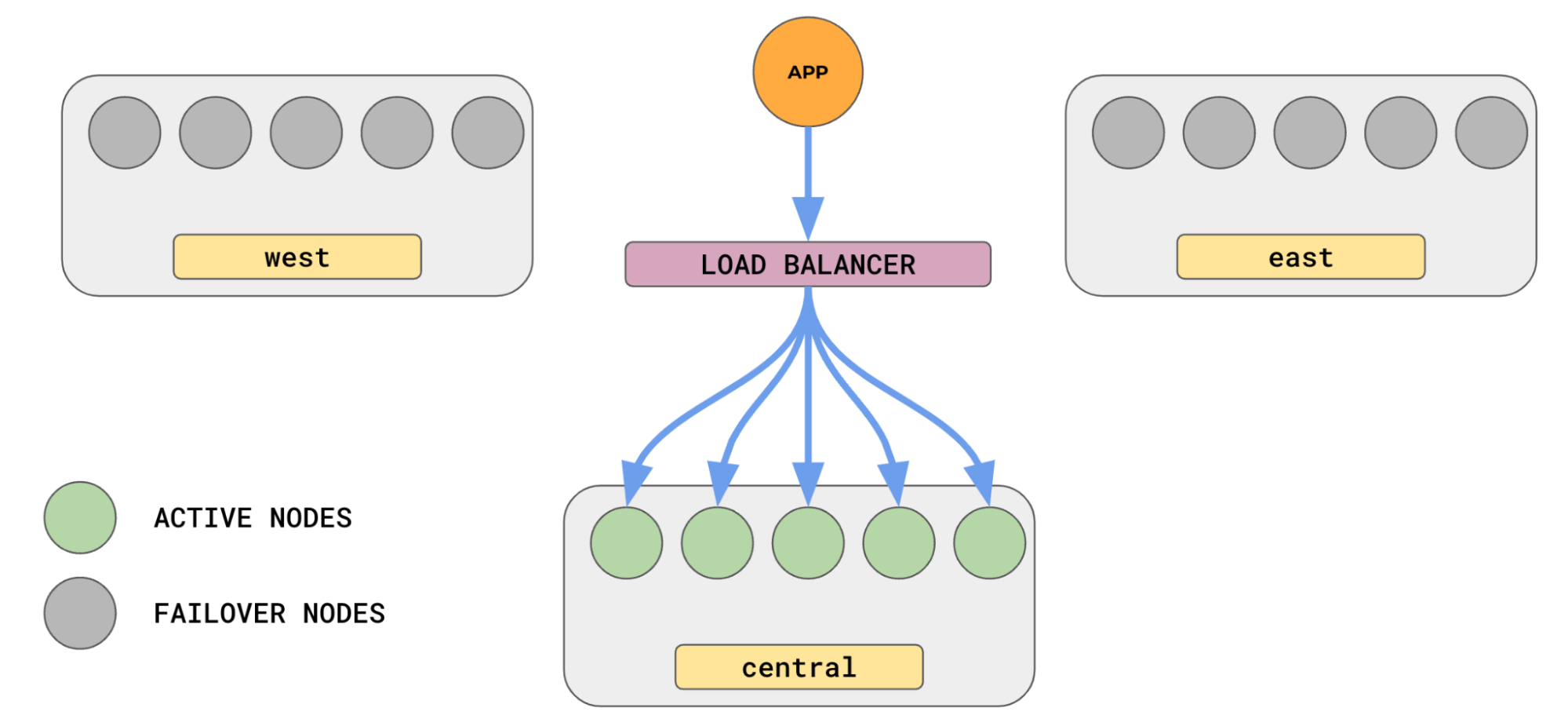
With YugabyteDB YSQL Smart Drivers, available in multiple languages, you do not need a separate load balancer service. The smart driver needs the IP/hostname of just one node in the cluster
Note: It is a good idea to pass in a few more nodes from different zones/regions to handle a single-node/zone/region failure). It automatically fetches the complete node list from the cluster and spreads the connections from your applications to various nodes in the cluster. It also refreshes the node list regularly (default: 5 minutes). This can be activated by passing the load_balance option in your connection string like
postgres://username:password@<node-ip>:5433/database_name?load_balance=true
If you’ve set preferred leaders, you can use the topology_keys option to send connections only to nodes in that region. For example, if you had set us-central as your preferred region, then adding the following topology_keys would make sure the client connects only to the nodes in us-central.
load_balance=true&topology_keys=aws.us-central.us-central-1a
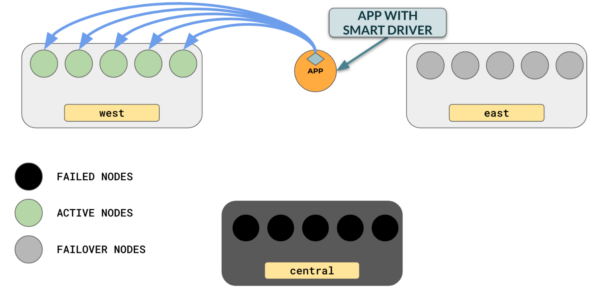
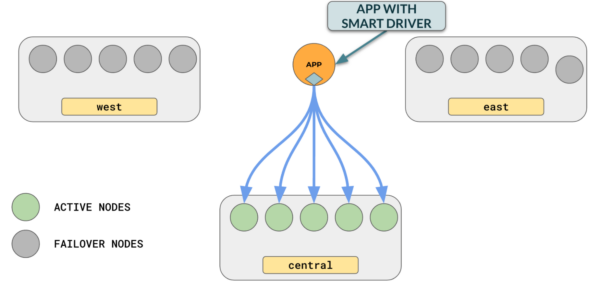 You can also set a fallback hierarchy by assigning priority to ensure that connections are made to the region with the highest priority, and then fall back to the region with the next priority in case the high-priority region fails. For example:
You can also set a fallback hierarchy by assigning priority to ensure that connections are made to the region with the highest priority, and then fall back to the region with the next priority in case the high-priority region fails. For example:
This ensures that connections are made to us-central.. In case us-central fails, only then will connections will be automatically made to us-west.
Further Information:
Conclusion
To provide a highly available service to your users, it is important that you distribute your data across multiple regions. Following some of the simple tips and strategies discussed in this article can help you reduce latency, and speed up the performance of your application in multi-region deployment configurations.
 Scenarios and the Multi-Tenancy Options That Support Them")

