Logistics Giant Optimizes for Low Latency and Resiliency At Scale
April 3, 2024
A leading global transport and logistics company needed to improve the workload performance and resiliency of the electronic radio frequency (RF) system (consisting of an RF gun/scanner and an app) used in its warehouses. The system is crucial for tracking and maintaining control over every SKU in the company’s supply chain.
Data collected from the RF guns is transmitted to an authenticator application via the device’s menu system. The application relies on a low-latency read to a relational database to verify authorizations for every user click and then define the allowable action and subsequent screen display. Every scan is followed by a write operation to record the user’s action (for tracking and security purposes).
The company initially adopted Oracle, but later migrated to PostgreSQL due to Oracle’s high costs. However, PostgreSQL introduced significant latency issues, which affected user productivity and substantially increased the number of errors. While Oracle’s workload response time came in at 19.8 milliseconds, PostgreSQL’s performance was five times slower, at 102 milliseconds.
But as crucial as improving the app’s performance was, they also needed to improve resiliency and availability. The company had experienced data center failures in the past, and warehouse employees were unable to work until a manual failover transferred and copied data from backups to the remaining operational data center. This process took an entire day (or more) to complete. The goal was to keep all users up and running by easily switching users to a surviving data center until the failed data center was restored.
The company began the search for a PostgreSQL-compatible database that could accommodate a hybrid deployment model, enhance performance to match user speed, and run the existing application without an expensive rewrite. YugabyteDB, essentially a turbocharged distributed version of PostgreSQL, was chosen for this purpose.
Performance and Resiliency Requirements
Performance (Low Read and Write Latencies)
Rapid authentication is crucial, especially for the 10,000 US-based workers using the scanners. These workers are so familiar with the application that they navigate through it quickly, often without looking at the menu screen. PostgreSQL struggled with the constant stream of requests, which led to significant response time challenges. Users became frustrated with the delays.
Because the app records every user interaction, logging each click on the scanner’s menu, the architecture needed to achieve low read latencies and, more importantly, low write latencies to keep up with users.
Resilience and High Availability
The company operates a geographically distributed hybrid cloud deployment model spread over three geographical locations. There are two owned physical data centers — PDC (Region 1) and FDC (Region 2)— and a third “backup region” in the cloud which utilizes Azure (Region 3).
To optimize performance across these three regions, one of the data centers manages inputs from users on one side of the country, while the other data center manages inputs from users on the other side.
No Application Changes
Performance improvements, resilience, and high availability all had to be achieved without rewriting the application, which presented a significant challenge.
YugabyteDB Hybrid-Cloud Architecture
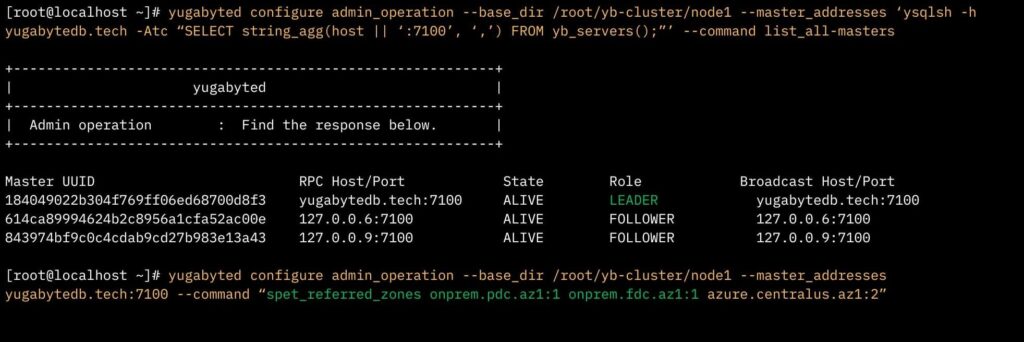
In collaboration with the Yugabyte technical team, the logistics company architected a stretch cluster across three regions: two on-prem data centers called PDC* (Region 1) and FDC* (Region 2) and the third cloud region on Azure (Central US—designated as Region 3). Both on-prem regions were set up as preferred regions.

Three nodes are deployed in each region, creating a nine-node, synchronous universe with a replication factor of three (RF=3). Each on-prem region hosts an application server, and application users are typically assigned to the server closest to their location.
A note about Azure: Although the Azure region is part of the stretch cluster and is “online,” the application was designed not to connect to it under normal operating conditions. The Azure region holds a copy of the data for the tables. Its presence ensures data redundancy and enhances the system’s overall resilience, ensuring everything remains up and running if one of the on-prem data centers fails.

NOTE: For illustration purposes, a single node was utilized, whereas for the actual use case, these are physical nodes.
In this deployment model, latency was 20 milliseconds between the two on-prem data centers and approximately 72 milliseconds between the two centers and the Azure cloud region.
The Architecture’s Impact on Resiliency and High Availability
The synchronous stretch cluster eliminates the need for manual intervention when a data center fails. Data is automatically replicated to the other data center and to the Azure cloud. All that needs to happen is for the impacted application to be pointed to the remaining data center.
Achieving Low Latency by Ensuring Data Resides Locally
To lower latency and match the users’ pace of work, we mainly focused on localizing reads within the users’ assigned regions.
Tablespaces
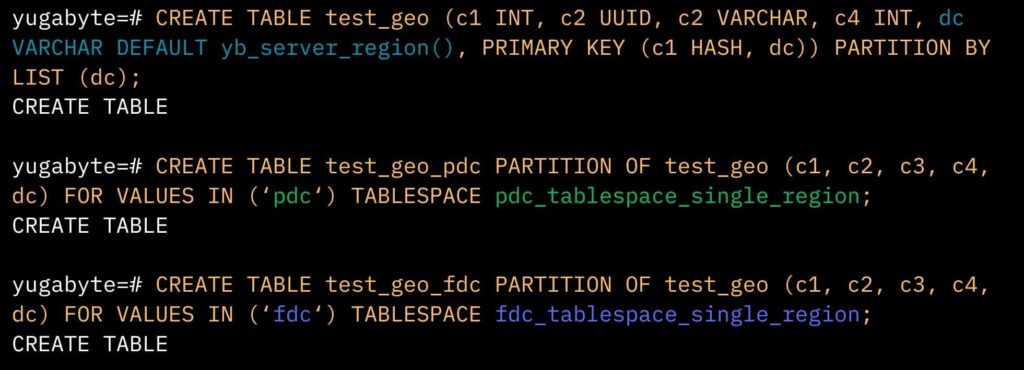
To eliminate the impact of cross-region latency, we utilized tablespaces to ensure that data resided locally in Region 1 and Region 2.

Creating cross-region and single-region tablespaces For example, in the PDC tablespace (above), the leader preference was configured with PDC as the primary, FDC as secondary, and the Azure central region as the tertiary option. Conversely, the FDC tablespace set FDC as the leader, followed by PDC, and again placed Azure as the third preference.
Locality-optimized workloads
Some tables, however, needed to be entirely localized. For these tables, all replicas were confined to a single region, for example, PDC.
This meant that any table created against this tablespace fully resided within the PDC region, ensuring fast reads and writes without cross-region latency. These tables were temporary, so their loss was acceptable if (for example) the PDC data center failed. A similar setup was established for FDC, aligning the data location with the application’s regional use.
Setting up locality-optimized workloads These temporary tables were intentionally not synchronized with the other preferred region. Since they were not critical for long-term storage, they also did not require backup to Azure.
No App Rewrites
Row-level geo-partitioning was implemented to further reduce latencies by keeping the most used data close to the user. To ensure no app changes were required, YugabyteDB introduced a powerful feature, locality-optimized geo-partitioning which merges PostgreSQL’s partitioning and tablespaces concepts to boost performance. This functionality allows for the addition of a new column to tables. In this case, that would be a ‘dc’ (data center) column, which automatically defaults to the user’s region.
Adding new columns (DC for “data center”) to tables (DC). Writes
For writes, the ‘dc’ column defaults to the value returned by the ‘yb_server_region’ function which dynamically identifies the region (FDC, PDC, or Azure) based on the cluster configuration defined in the cloud location parameter.
Queries
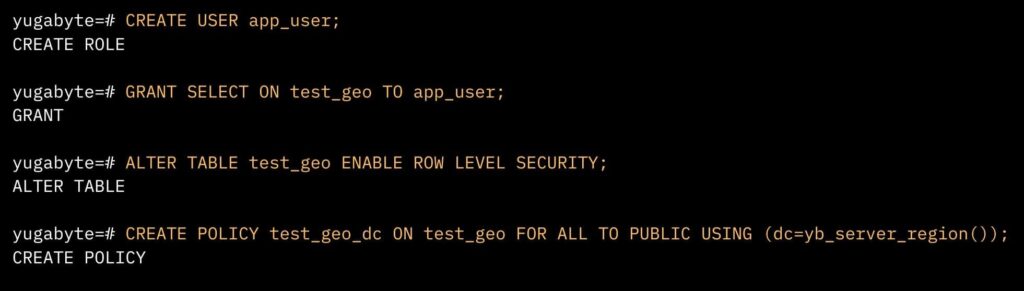
To maintain the current structure of the application’s queries without requiring modifications, row-level security (RLS) was adopted. This eliminates the need for each query to explicitly include a specific “WHERE” clause (for example, ‘WHERE dc=[region]’). It is automatically included based on the connected server’s region, boosting efficiency without altering the query structure.
Create a row-level security (RLS) policy to maintain query structure without having to rewrite the app. This approach not only simplifies writes but also ensures efficient and secure reads across multiple regions, demonstrating YugabyteDB’s ability to offer low-latency reads and writes with a locality-aware, application-transparent solution. The logistics company benefited from this solution, achieving streamlined operations without the need for any modifications to their existing applications.


 Dig a bit deeper into how this company gained low latency reads and writes for this authorization app without having to rewrite it. It is all in our companion blog- Gain Low Latency Reads and Writes Without Changing Your PostgreSQL Application.
Dig a bit deeper into how this company gained low latency reads and writes for this authorization app without having to rewrite it. It is all in our companion blog- Gain Low Latency Reads and Writes Without Changing Your PostgreSQL Application.Duplicate Covering Indexes and Follower Reads
To further lower read latencies we enabled follower reads from within the primary cluster’s stored procedures. But first, to ensure real-time consistent reads in each region, we set up duplicate (covering) indexes
Step one in this process was to create covering indexes. Although these indexes improved performance, they were just the first step.
Duplicate Covering Indexes
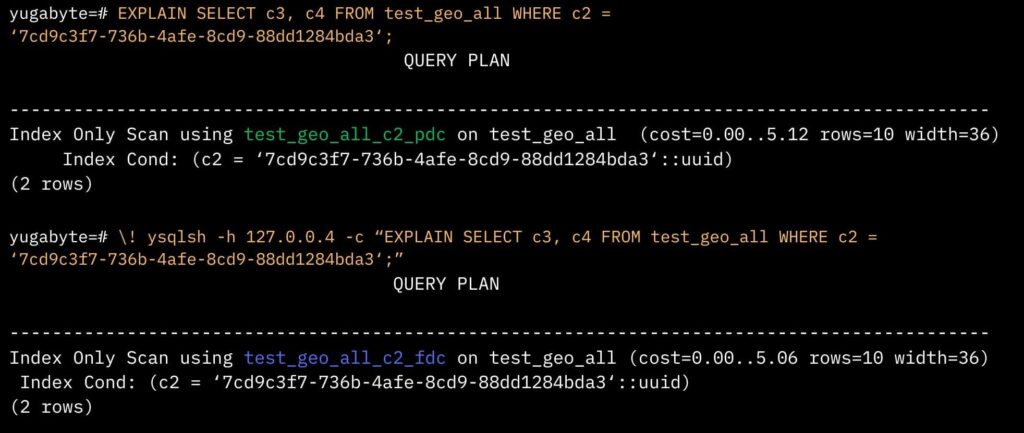
Then we created duplicate covering indexes (see above) that would be localized to each region. We accomplished this by creating indexes and localizing them through tablespaces.
NOTE: This approach leveraged features introduced in YugabyteDB 2.17.3, where the optimizer is designed to recognize and utilize these localized indexes intelligently. When running a query, the system selects the appropriate index, which is quite effective in enhancing performance. We acknowledge that having a lot of duplicate [covering] indexes will increase write latency. However, for this use case, only two or three columns were indexed, making the process manageable and effective.
This resulted in an index-only scan on the specifically created indexes for each region, which significantly improved response times for reads and brought YugabyteDB on par with Oracle’s performance.
Follower Reads
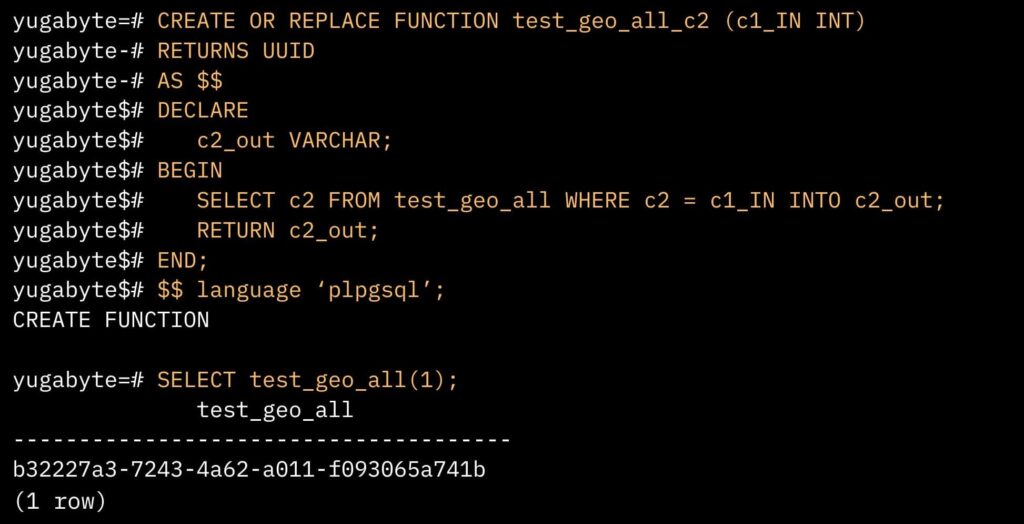
Because the company’s authenticator application used SELECT queries within functions rather than running them as standalone prepared statements, the follower reads needed to work effectively from within these encapsulated functions. Therefore, two key adjustments were necessary: setting a session parameter and ensuring it was read-only.
The authenticator app uses functions for all reads, so the question became how to enable follower reads in a function.
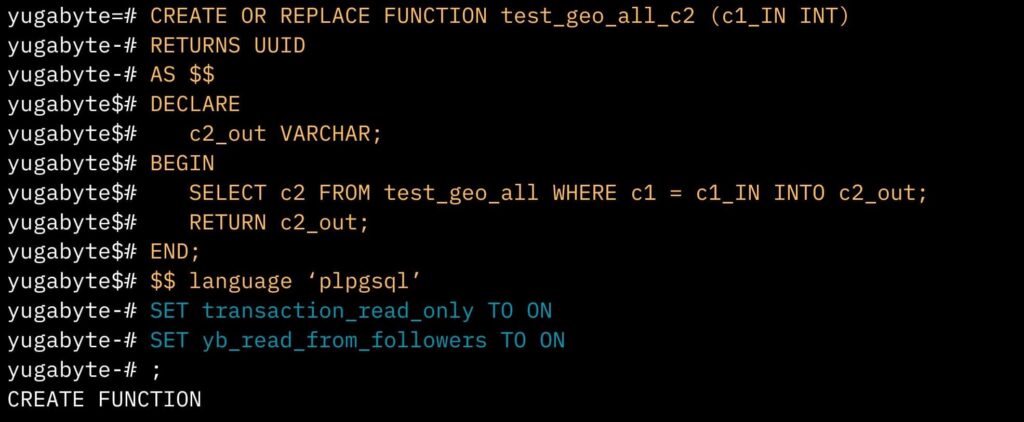
The commands within the function were rearranged, and a specific SET command (highlighted in blue) was added to all functions where follower reads were applicable because a lot of the data in the tables were static LOOKUP tables. By incorporating this change in LOOKUP table functions, we ensured efficient reads from follower nodes, regardless of which node (in the region) they were connected to.
A Very Short Demo to Show YugabyteDB Follower Reads >>>>>>
This was crucial since each region had three nodes. Even if the user was not connected to a node with a tablet leader, they needed to be able to read from the follower on the node they were connected to.
This modification significantly improved read operations, especially in scenarios like three-way JOINs on a table, where YugabyteDB might have previously had to retrieve data from a leader on a different node. This adjustment ensured all required data could be accessed from a single node.
NOTE: Initially, we included these settings in the function’s BEGIN statement. This method worked for JDBC, where parameters can be set before SELECT queries, but failed with ODBC. Because the application used ODBC to connect to YugabyteDB, we had to create a solution tailored to ODBC-compatible functions.


Lowering Latency — The Results

Let’s examine the results. The chart above shows our targeted workload, which is essentially the sequence of steps triggered by user interactions with the RF gun/scanner.
As mentioned at the beginning, the response time for this workload in PostgreSQL was 102 milliseconds, and in Oracle, it was 19.8 milliseconds.
YugabyteDB achieved a workload runtime of 43.7 milliseconds, surpassing Postgres and achieving performance levels nearly equivalent to Oracle but running in a distributed database architecture.
The client’s objective was to transition off of Oracle, but their ultimate goal was to adopt YugabyteDB distributed architecture and capitalize on its superior resiliency. While Postgres was a viable option, developing resilient/low-latency solutions was extremely complex and time-consuming. The Yugabyte database was a clear winner, providing the required resilience while also delivering significantly better response times than PostgreSQL.
Additional Resources:
Tablespaces (YugabyteDB documentation)
Locality-Optimized Geo-Partitioning (YuabyteDB documentation)
Row-Level Security (YugabyteDB documentation)
Duplicate Indexes (YugabyteDB documentation)
Geo-Distribution in YugabyteDB: Engineering Around the Physics of Latency


