Exploring Multi-Region Database Deployment Options with a Slack-Like Corporate Messenger
July 20, 2022
This blog post explores the most popular multi-region database deployment options by designing a data layer for a Slack-like corporate messenger.
Distributed database deployments across multiple regions are becoming commonplace for a number of reasons. Firstly, more and more applications must comply with data residency requirements such as GDPR. Additionally, they must serve user requests as fast as possible from the data centers closest to the user and withstand cloud region-level outages.
Corporate Messenger Architecture
Our Slack-like corporate messenger is a cloud native application made up of several microservices. In this example, let’s suppose we’re working on the first version of the app, which includes the following services:
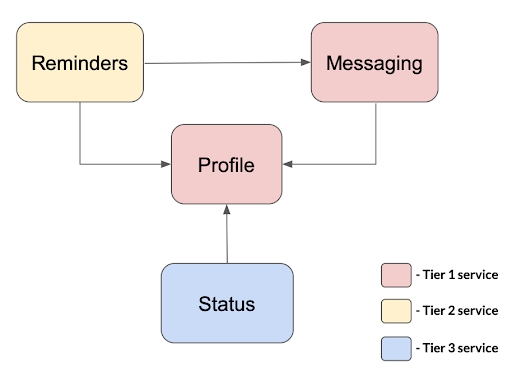
Each microservice belongs to one of these groups:
- Tier 1: A mission-critical service. Any downtime significantly impacts a company’s reputation and revenue. Consequently, service must be highly-available, strongly consistent, and restored immediately in the case of an outage.
- Tier 2: A service providing an important function. Its downtime impacts customer experience and can increase a customer churn rate. This means that service must be restored within two hours.
- Tier 3: A service providing a valuable capability. Its downtime impacts customer experience (though insignificantly). In this case, service must be restored within four hours.
The Profile microservice stores information about user profiles, such as name, email address, and profile picture URL. It belongs to the Tier 1 group because every other microservice depends on it.
The Messaging microservice provides an essential capability for every messenger app. This is the ability to exchange messages – so it is placed in the Tier 1 group. As a Slack-like corporate messenger, this microservice supports company-specific workspaces and channels within those workspaces.
Reminders and Status are the remaining microservices and improve the overall user experience. The Reminders service lets us forget a particular conversation for now. However, we can return to it later by scheduling a prompt like “Remind me about this message in a week at 9am”. The Status microservice allows us to let other people know what we are up to – ‘Active,’ ‘Busy,’ ‘Vacationing,’ or ‘Out Sick.’ These services are not mission-critical. Thus, we place them in the Tier 2 and 3 groups, respectively.
This messenger is designed as a geo-distributed application, spanning all continents, scaling horizontally, and tolerating even cloud region-level outages. While this design requires us to talk about the global deployment/orchestration of microservice instances and traffic routing through global load balancers, we’ll stay focused on the data layer in this article.
Multi-Region Database Deployment Options
The messenger’s data layer will be built on a transactional distributed database. So here, we need a strongly consistent database that scales up and out on commodity hardware and “speaks” SQL natively.
Why not start with a single-server database such as PostgreSQL or MySQL and then upgrade it with some form of sharding and replication?
Well, because it works to a certain extent. Here we can learn from the Slack engineering team. But, while the Slack team uses Vitess as a database clustering solution for MySQL, our corporate messenger will be built on YugabyteDB, a Postgres-compliant distributed database for geo-distributed apps.
The table below summarizes the different multi-region deployment options available in YugabyteDB. You can use this as a quick reference, but we’ll go ahead and explore all of these in the following sections.
| Single Stretched Cluster | Single Geo-Partitioned Cluster | Single Cluster With Read Replicas | Multiple Clusters With Async xCluster Replications | |
|---|---|---|---|---|
| Overview | The cluster is “stretched” across multiple regions. The regions can be located in relatively close proximity (e.g. US Midwest and East regions) or in distant locations (e.g. US East and Asia South regions). | The cluster is spread across multiple distant geographic locations (e.g. North America and Asia). Every geographic location has its own group of nodes deployed across one or more local regions in close proximity (e.g. US Midwest and East regions). Data is pinned to a specific group of nodes based on the value of a partitioning column. | The cluster is deployed in one geographic location (e.g. North America) and “stretched” across one or more local regions in relatively close proximity (e.g. US Midwest and East regions). Read replicas are usually placed in distant geographic locations (e.g. Europe and Asia). | Multiple standalone clusters are deployed in various regions. The regions can be located in relatively close proximity (e.g. US Midwest and East regions) or in distant locations (e.g. US East and Asia South regions). The changes are replicated asynchronously between the clusters. |
| Replication | All data is synchronously replicated across all regions. | Data is replicated synchronously and only within a group of nodes belonging to the same geographic location. | Synchronous within the cluster and asynchronous from the cluster to read replicas. | Asynchronous replication – unidirectional or bidirectional. |
| Consistency | Strong Consistency | Strong Consistency | Timeline consistency (updates arrive in original order) | Timeline consistency (updates arrive in original order) |
| Write latency | High latency (e.g., writes can go from a North America to European region) | Low latency (if written to a group of nodes from nearby geographic locations) | Low latency for writes within the primary cluster’s region. High latency for writes from distant geographic locations (e.g. locations with read replicas). | Low latency (if written to a cluster from a nearby geographic location) |
| Read latency | High latency (e.g., reads can go from a North America to European region) | Low latency (if queried from nearby geographic locations) | Low latency (if queried from nearby geographic locations with the usage of read replicas) | Low latency (if queried from a cluster from a nearby geographic location) |
| Data Loss on Region Outage | No data loss (if the cluster is “stretched” across multiple regions) | No data loss (if in every geographic location the nodes are spread across multiple local regions) | No data loss (if the primary cluster is “stretched” across multiple regions) | Partial data loss – if a cluster is deployed within a single region, and the region fails before changes replicated to other clusters. No data loss – if every standalone cluster is “stretched” across multiple local regions. |
Table 1. YugabyteDB Multi-Region Deployment Options
All our microservices belong to different service tiers and have various requirements. This allows us to explore how each of the above-mentioned multi-region deployment options come into play and under what circumstances.
We will experiment with the multi-region deployment options using a Gitpod sandbox that bootstraps clusters with the desired configuration, create schemas for our microservices, and provides sample instructions for data querying and management.
Profile and Messaging Services: A Single Geo-Partitioned Database
The Profile and Messaging microservices are always under high load. This is because users worldwide send and read thousands of messages per second, and user profile data being continuously requested by other dependent microservices.
As a result, both the Profile and Messaging microservices must perform at high speeds across the globe without interruption. Additionally, the services and their data layer must scale up and out easily within a geographic location. So, if the load increases, but only in Europe, then we want to scale up (or out) just in that region by adding more CPUs, storage, RAM, and nodes, leaving other regional infrastructure untouched.
These microservices must also comply with data residency requirements in specific geographies. For instance, if our corporate messenger wants to operate in Europe, it must comply with the GDPR policies. This means storing profiles, messages, and other personal data in European data centers.
But, if we push these requirements down to our data layer, what is the most suitable multi-region deployment option? Here, a single geo-partitioned cluster is the best way to go.
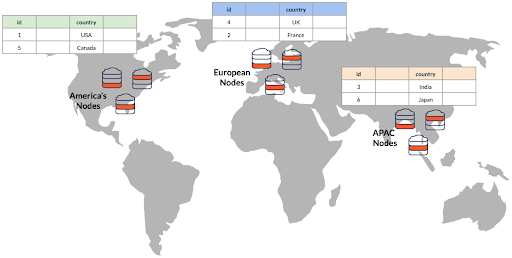
Our single database cluster is spread across multiple distant geographic locations – North America, Europe, and Asia-Pacific (APAC). Each geographic location has its own group of nodes that, for the sake of high availability, can span one or more local regions, such as the US Midwest, East, and South cloud regions in North America.
Data is pinned to a specific group of nodes based on the value of a partitioning column. In this case, the partitioning column is “country.” For instance, if country=France, a message is automatically stored in a European region. But if country=Japan, then the message is located in an APAC data center.
Let’s get down to code and see how this multi-region deployment type works in practice. Here we will use our Gitpod sandbox to bootstrap a sample YugabyteDB cluster in the geo-partitioned mode.
First, we need to configure our YugabyteDB nodes and microservices schemas:
- Upon startup, cluster nodes are placed in one of the cloud regions that belong to a specific geographic location: us-west-1 for North America, eu-west-1 for Europe, and ap-south-1 for APAC (see the Deployment#1 (Geo-Distributed) task for details):
“placement_cloud=aws,placement_region=us-west-1,placement_zone=us-west-1a”
“placement_cloud=aws,placement_region=eu-west-1,placement_zone=eu-west-1a”
“placement_cloud=aws,placement_region=ap-south-1,placement_zone=ap-south-1a” - Region-specific tablespaces are created and match the placement regions of our cluster nodes:
CREATE TABLESPACE americas_tablespace WITH ( replica_placement='{"num_replicas": 1, "placement_blocks": [{"cloud":"aws","region":"us-west-1","zone":"us-west-1a","min_num_replicas":1}]}' ); CREATE TABLESPACE europe_tablespace WITH ( replica_placement='{"num_replicas": 1, "placement_blocks": [{"cloud":"aws","region":"eu-west-1","zone":"eu-west-1a","min_num_replicas":1}]}' ); CREATE TABLESPACE asia_tablespace WITH ( replica_placement='{"num_replicas": 1, "placement_blocks": [{"cloud":"aws","region":"ap-south-1","zone":"ap-south-1a","min_num_replicas":1}]}' ); - All tables from the Profile and Messaging schemas get partitioned across those tablespaces using the country column. This what DDL statements look like for the Message table:
CREATE TABLE Message( id integer NOT NULL DEFAULT nextval('message_id_seq'), channel_id integer, sender_id integer NOT NULL, message text NOT NULL, sent_at TIMESTAMP(0) DEFAULT NOW(), country text NOT NULL, PRIMARY KEY(id, country) ) PARTITION BY LIST(country); CREATE TABLE Message_Americas PARTITION OF Message FOR VALUES IN ('USA', 'Canada', 'Mexico') TABLESPACE americas_tablespace; CREATE TABLE Message_Europe PARTITION OF Message FOR VALUES IN ('United Kingdom', 'France', 'Germany', 'Spain') TABLESPACE europe_tablespace; CREATE TABLE Message_Asia PARTITION OF Message FOR VALUES IN ('India', 'China', 'Japan', 'Australia') TABLESPACE asia_tablespace;Next, once the cluster is configured and schema is created, we can try it out:
- Exchange a few messages within the APAC region (country=India):
INSERT INTO Message (channel_id, sender_id, message, country) VALUES (8, 9, 'Prachi, the customer has a production outage. Could you join the line?', 'India'); INSERT INTO Message (channel_id, sender_id, message, country) VALUES (8, 10, 'Sure, give me a minute!', 'India');
- Confirm the messages were stored in the APAC location by querying the shadow table Messages_Asia directly:
SELECT c.name, p.full_name, m.message FROM Message_Asia as m JOIN Channel_Asia as c ON m.channel_id = c.id JOIN Profile_Asia as p ON m.sender_id = p.id WHERE c.id = 8;
name | full_name | message --------------------------+---------------+------------------------------------------------------------------------ on_call_customer_support | Venkat Sharma | Prachi, the customer has a production outage. Could you join the line? on_call_customer_support | Prachi Garg | Sure, give me a minute! (2 rows)
- Double check the messages are not copied to the North America location by querying the Message_Americas table:
SELECT c.name, p.full_name, m.message FROM Message_Americas as m JOIN Channel_Americas as c ON m.channel_id = c.id JOIN Profile_Americas as p ON m.sender_id = p.id WHERE c.id = 8;
name | full_name | message -----+-----------+--------- (0 rows)
That’s it. Simple!
But, some of you might be bothered by one unanswered question. If all the data is stored in predefined geographic locations, why don’t we deploy multiple independent clusters in each location?
Well, with the single geo-partitioned cluster, we can do cross-region queries using a single connection endpoint to the database.
There are use cases for this. Check out our Gitpod sandbox to learn more about the cross-region queries and the geo-partitioned deployment option.
Reminders Service: Single Database With Read Replicas
The Reminders microservice has more relaxed requirements than the Profile and Messaging microservices. Unlike those, the Reminders service doesn’t experience thousands of requests per second, or need to comply with data residency regulations.
As a result, we can consider another multi-region deployment option: the single cluster with read replicas.
We deploy a single database cluster in one geographic location: North America. The microservice needs to tolerate cloud region-level outages, so, the cluster is “stretched” across several regions in relative close proximity (e.g., US Midwest, East, and South). We can define one of the regions as the preferred zone to remain highly performant, with the selected multi-region deployment configuration (we’ll talk more about this later in the next section).
Next, we deploy read replica nodes in distant geographic locations – one in Europe and one in Asia. The primary cluster synchronizes data to the read replicas asynchronously, which is acceptable for the Reminders.
In a data layer configuration like this, writes always go to the primary cluster. Even if a user based in Singapore creates a reminder like “Remind me about this discussion in 1 hour,” the reminder will still be sent and stored in our North American cluster.
However, we don’t need to connect to the primary cluster’s endpoint to send the reminder. In this case, the user’s browser/application will be connected to the read replica, therefore the replica will automatically forward the write to the primary cluster for us!
Read replicas enable fast reads across all geographic locations. For instance, our microservice has a background task that wakes up every minute, pulls all reminders from the database that has just expired, and sends notifications to the users.
Instances of such tasks run in every distant geographic location – one in North America, one in Europe, and one in APAC. North America’s instance pulls America-specific reminders from the primary cluster while European and APAC instances read the reminders (belonging to the users from their regions) from read replica nodes. This is how read replicas can help to reduce network traffic across distant locations.
Now, let’s use our Gitpod sandbox to experiment with this type of multi-region database deployment. The sandbox starts a single-node primary cluster and two read replicas (see the Deployment#2 (Read Replicas) task for details).
Once the deployment is ready:
- We create a schema for the Reminders microservice:
CREATE TABLE Reminder( id integer NOT NULL DEFAULT nextval('reminder_id_seq'), profile_id integer, message_id integer NOT NULL, notify_at TIMESTAMP(0) NOT NULL DEFAULT NOW(), PRIMARY KEY(id) ); - Then add the first reminder to our primary cluster:
ysqlsh -h 127.0.0.4 (connecting to the primary cluster’s endpoint) INSERT INTO Reminder (profile_id, message_id, notify_at) VALUES (5, 1, now() + interval '1 day');
- Finally, we can connect to an APAC read replica node and confirm the reminder was replicated there:
ysqlsh -h 127.0.0.6 (connecting to the APAC replica’s endpoint) SELECT * FROM Reminder;
id | profile_id | message_id | notify_at ---+------------+------------+--------------------- 1 | 5 | 1 | 2022-04-02 18:55:02 (1 row)
To learn more, check out the Gitpod sandbox that has a Reminders-specific tutorial.
Status Service: Multiple Databases With Async Replication
The Status microservice has similar requirements to the Reminders one. In this case it must be highly available and scalable, but it doesn’t need to comply with data residency requirements. However, we estimate that users will change their statuses (‘Active’, ‘Busy’, ‘In a Meeting’, ‘Vacationing’, ‘Out Sick’) much more frequently than they schedule reminders. Thus, we need both fast reads and writes.
With our truly global user base, we can’t expect fast writes to the read replica clusters. That’s why the Status service will use another multi-region deployment option: multiple clusters with async xCluster replication.
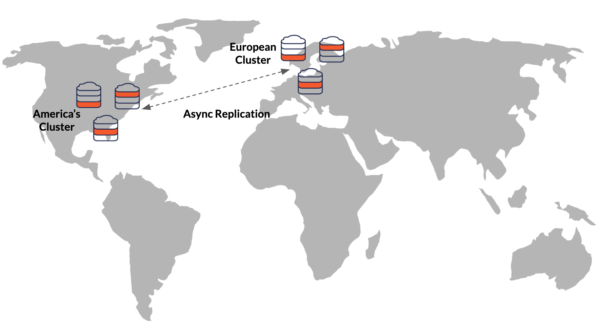
A multi-node standalone cluster is deployed in every distant location such as North America and Europe. Changes are replicated synchronously within each cluster and asynchronously between the clusters. We relax high availability requirements for this microservice by stretching each cluster across multiple availability zones within a cluster’s region.
This means that if the cluster’s region goes down, so does the cluster. So, some recent status changes might not be fully replicated to other clusters. However, missed recent status changes are not mission-critical information and we are willing to lose those updates in favor of faster performance while all the clusters operate normally.
Let’s use the same Gitpod sandbox to see this type of deployment in action. Note, that at the time of writing, bidirectional replication between more than two clusters has not yet been supported. As a result, our sandbox provisions two clusters (see the Deployment#3 (xCluster Replication) task).
Once the clusters are ready:
- We create the Status service schema in each cluster:
CREATE TYPE profile_status AS ENUM ('Active', 'Busy', 'In a Meeting', 'Vacationing', 'Out Sick'); CREATE TABLE Status ( profile_id integer PRIMARY KEY, status profile_status NOT NULL DEFAULT 'Active', set_at TIMESTAMP(0) NOT NULL DEFAULT NOW() ); - Then finish the setup of the bidirectional replication.
- Next, a user from the USA changes his status. His status is then updated in the cluster closest to the user:
ysqlsh -h 127.0.0.7 (connecting to the North America cluster’s endpoint) UPDATE Status SET status = 'Active' WHERE profile_id = 3;
- Finally, the update is replicated to the European cluster. This means that the relations of the user from Europe can read the status from the European cluster:
ysqlsh -h 127.0.0.8 (connecting to the European cluster’s endpoint) SELECT * FROM Status;
profile_id | status | set_at
-----------+--------+---------------------
3 | Active | 2022-03-30 15:10:26You can review this section of our Gitpod tutorial to learn more about the xCluster-based replication setup.
Single “Stretched” Cluster Option
In the beginning, we provided a reference table with the four most widely-used multi-region deployment options. We used a single geo-partitioned cluster for the Profile and Messaging microservice, the read replica cluster for the Reminders service, and multiple clusters with async replication for the Status microservice. But, what’s missing from the list? The answer is the single “stretched” cluster.
Due to high latencies between distant geographic locations (i.e., North America, Europe, APAC), the single “stretched” cluster across those faraway regions is not a suitable option for our microservices. This is because read and write latencies for cross-region queries can be prohibitively high. That’s why our services built up their data layers on other multi-region deployment options.
However, if you pay attention to details, you would oppose this and say that, in fact, the single “stretched” cluster option was used by our microservices. And you would be right! We did use that multi-region deployment option, but only for regions in relative close proximity.
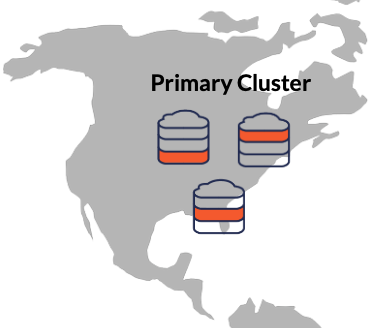
For example, the primary cluster of the read replica deployment option (that we used for the Reminders service) spans three regions in close proximity: US Midwest, East, and South. Using this configuration, ensures our service is tolerant to region-level outages, without incurring a significant performance penalty. We’ll remain highly performant by setting a preferred region with the set_preferred_zones setting. For example, if the US Midwest is the preferred region it will host the primary master process and all tablet leaders that will minimize network roundtrips across multiple regions.
Conclusion
As we discovered, multi-region database deployment options exist for good reason. We don’t need to just pick one option and then use it for all use cases. By breaking down the Slack-like messenger into microservices, we can see that it’s up to each microservice to decide how to architect its multi-region data layer. As before, you can try out these options on your personal laptop using the Gitpod sandbox.
This concludes our deep dive into the data layer of a Slack-like corporate messenger.
If you’re curious about the design and architecture of the messenger’s upper layer (i.e., deployment and coordination of microservices across multiple regions, multi-region APIs layer, and usage of global load balancers), then leave a comment below!
Got questions? Join the YugabyteDB community Slack channel for a deeper discussion with nearly 6,000 developers, engineers, and architects.

")
