What Every Application Developer Needs to Know About Geo-Distributed Databases
April 5, 2022
I’ve been working with distributed systems, platforms, and databases for the last seven years. Back in 2015, many architects began using distributed databases to scale beyond the boundaries of a single machine or server. They selected such a database for its horizontal scalability, even if its performance remained comparable to a conventional single-server database.
Now, with the rise of cloud native applications and serverless architecture, distributed databases need to do more than provide horizontal scalability. Architects require databases that can stay available during major cloud region outages, enable hybrid cloud deployments, and serve data close to customers and end users. This is where geo-distributed databases come into play.
But as a Java developer, two questions jump out at me:
- How much effort should I put in creating applications for cloud native, geo-distributed databases?
- Will it be just a quick refactoring of my existing application or a complete redesign/rewrite?
Effort varies from use case to use case. However, even then, you can learn a lot from the “getting started” experience when building a simple application. In this post, I’ll share key insights when creating a Java application using YugabyteDB as the geo-distributed database. You can find my complete source code on GitHub. Now let’s dive in!
Database Deployment in Geo-Distributed Databases
YugabyteDB provides a fully-managed cloud version that supports AWS and GCE, similar to other cloud native databases. This is a big deal for me as a developer. I want nothing more than to get an instance running so I can focus on my application logic.
Eventually, it took me a few minutes to spin up a free instance on AWS and copy the connectivity details for my application. As expected, the experience was smooth and quick. Gone are the days when I had to download, install, and configure databases before writing a single line of code.
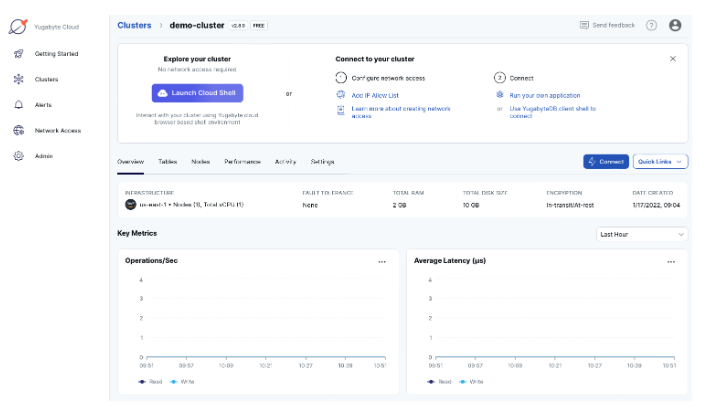
YugabyteDB Cloud Panel with my running instance.
Database Connectivity in Geo-Distributed Databases
As a backend developer, I’m grateful for a database that speaks SQL natively. This shortens the learning curve and lets me reuse existing logic. Even if I use Spring Data or Micronaut, I still write and execute direct SQL queries.
As long as YugabyteDB speaks in Postgres dialect, I wanted my simple Java application to connect to my running database instance through a good-old JDBC interface. With YugabyteDB, you can pick from the standard PostgreSQL JDBC driver or native Yugabyte JDBC driver that comes with some performance perks. I selected the latter.
In a few minutes, I added my laptop’s IP address to the IP allow list in YugabyteDB. I also compiled and launched my sample application with a successful connection to the cloud instance. The JDBC connectivity logic was no different than what MySQL, PostgreSQL, and other relational databases require me to follow. This was a very good sign.
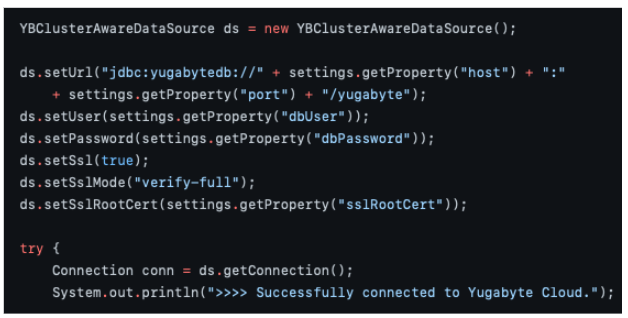
What’s even better is even though I used a free single-node instance for my tests, the connectivity logic remains the same even if my database counts 60 nodes spanning across several continents. For application developers, YugabyteDB is a single logical instance with all the complexity related to data partitioning, inter-node communication, and query routing happening transparently behind the scenes.
Basic CRUD Operations in Geo-Distributed Databases
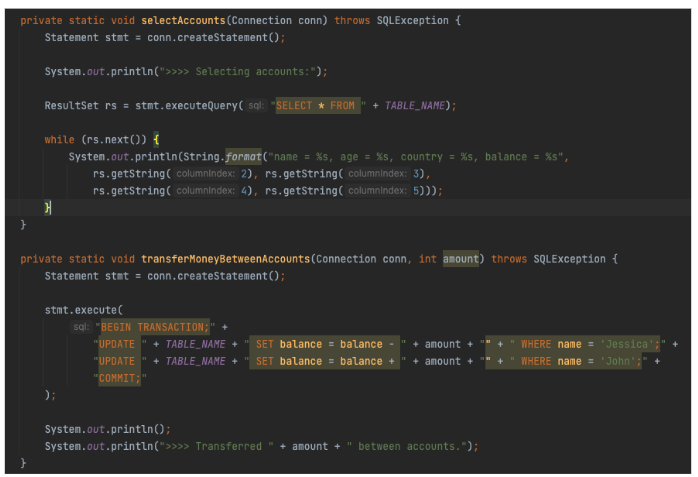
Once the connectivity logic was put in place, I introduced a few methods to create a sample table and then query and update its records through the JDBC connection. This meant my simple Java application had to be as primitive as possible. As a result, I picked a pretty basic use case: money transfer between two accounts.
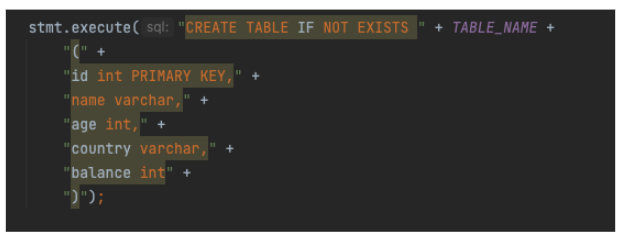
The sample table was created with the standard CREATE TABLE command:
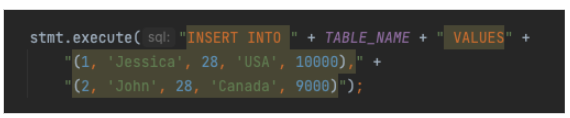
And populated with exactly two records (enough to assess the getting started experience):
Finally, SQL queries that would query and update a similar table in Postgres or MySQL worked the same way in my geo-distributed database. Below is a complete implementation of two methods: the first selects your distributed records, and the second updates the records consistently with distributed transactions:
Closing Thoughts
The creators of contemporary geo-distributed databases shield me (the application developer) from most complexities related to distributed systems. I started a distributed database instance in a minute, connected to it as a single logical instance, and queried the database through familiar SQL and JDBC interfaces. I do acknowledge my simple Java application is far from a real-world solution containing low-level, database-specific optimizations. However, getting started was as easy as a single-server database, which is a big deal.
You can explore my complete application on GitHub. I encourage you to try and run it yourself.


")