GO-JEK’s Performance Benchmarking of CockroachDB, TiDB & YugabyteDB on Kubernetes
June 20, 2019
Iqbal Farabi and Tara Baskara, Systems Engineers from GO-JEK Indonesia, recently presented the results of their benchmarking of cloud native databases on Kubernetes at KubeCon Europe in Barcelona. The three databases they benchmarked were CockroachDB, TiDB and YugabyteDB. This post brings their presentation (video recording) and slides (PDF) to the attention of our readers. It also highlights a few areas of collaboration between the GO-JEK team and YugabyteDB Engineering.
Selecting Cloud Native Databases to Benchmark
As we have previously described in “Docker, Kubernetes and the Rise of Cloud Native Databases”, cloud native databases are a new breed of databases that are horizontally scalable, can be run in dynamic cloud environments, can be deployed in containers (with Kubernetes as the orchestration engine), are highly resilient to failures and finally, are easy to observe and manage. On top these must-have characteristics, the GO-JEK team added the following qualification criteria.
- Open source
- Operational database
- ACID compliance
- Provides SQL-like API
The CNCF Landscape lists many databases and a few of them could qualify for the above criteria. The GO-JEK team selected the following three for their benchmarking exercise.

Yahoo! Cloud Serving Benchmark (YCSB)
Brian Cooper et. al from Yahoo! Research introduced their Yahoo! Cloud Serving Benchmark (YCSB) to the world in June 2010. Since then it has become the de-facto standard for benchmarking performance of databases that act as serving stores for “cloud OLTP” applications.
An Area of Collaboration
The YCSB paper notes the following four design tradeoffs in databases.
- Read performance versus write performance
- Latency versus durability
- Synchronous versus asynchronous replication
- Row versus column data partitioning
The GO-JEK team focused on the last three aspects in their presentation. However, they seem to have misinterpreted YugabyteDB’s replication architecture as asynchronous. We believe the Cassandra roots of the Yugabyte Cloud QL (YCQL) API may have led them to this conclusion. As highlighted in the next subsection, YugabyteDB uses synchronous replication that is inspired from Google Spanner and has no similarities with the asynchronous replication architecture of Cassandra. We would welcome the opportunity to collaborate with the GO-JEK team around better understanding of YugabyteDB architecture.
Synchronous vs. Asynchronous Replication in YugabyteDB
The YCSB paper defines this tradeoff in the following way.
Replication is used to improve system availability (by directing traffic to a replica after a failure), avoid data loss (by recovering lost data from a replica), and improve performance (by spreading load across multiple replicas and by making low-latency access available to users around the world). However, there are different approaches to replication. Synchronous replication ensures all copies are up to date, but potentially incurs high latency on updates. Furthermore, availability may be impacted if synchronously replicated updates cannot complete while some replicas are offline. Asynchronous replication avoids high write latency (in particular, making it suitable for wide area replication) but allows replicas to be stale. Furthermore, data loss may occur if an update is lost due to failure before it can be replicated.
For the primary cluster responsible for serving writes, YugabyteDB by default uses Raft-based synchronous replication to keep all the replicas of a shard in sync. It goes beyond the other two databases compared by also offering optional Read Replicas in faraway regions — these Read Replicas receive the data from the primary cluster using asynchronous replication. This approach is similar to Google Spanner’s notion of read-write replicas (for the primary cluster driven by synchronous replication) and read-only replicas (driven by asynchronous replication from the primary cluster).
Benchmarking Configuration
Dataset
The GO-JEK team customized the standard YCSB dataset to manage 1M records on a table with each workload running 1M operations and a variable number of threads. Details are listed in the slide below.

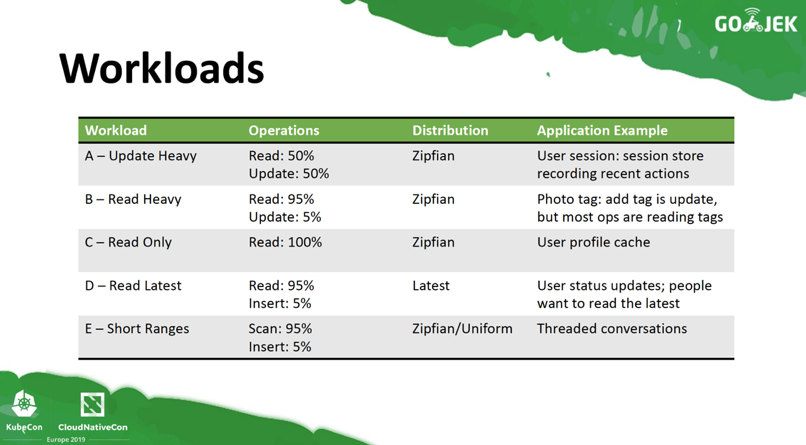
Workloads
There were 5 workloads used for the benchmarking — each workload is representative of a type of application as listed in the slide below.
Kubernetes
A 3 node GCE cluster with the following per-node specifications was used for benchmarking.
- n1-standard-16 machine type
- 1000 GB Local SSD
- 60 GB RAM
Since databases are modeled as StatefulSets in Kubernetes, the following were the resource settings for each StatefulSet:
- 14 vCPU request, 16 vCPU limit
- 30 GB RAM request, 60 GB RAM limit
- 500 GB SSD local persistent volume
Results
Workloads A-D
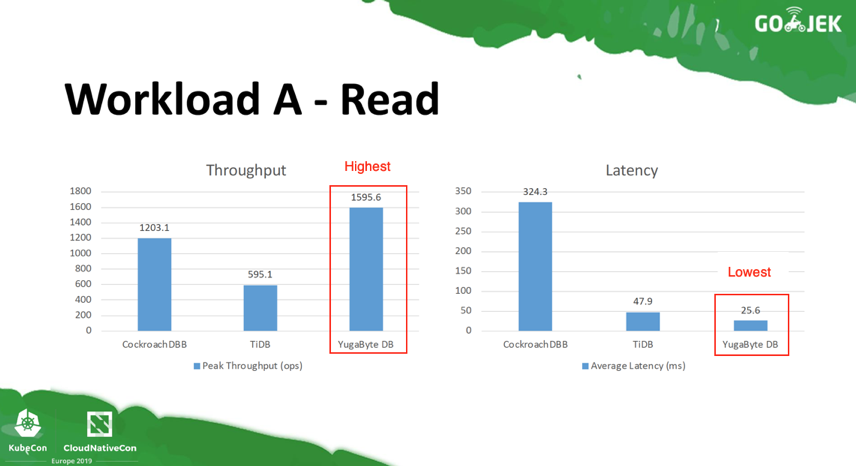
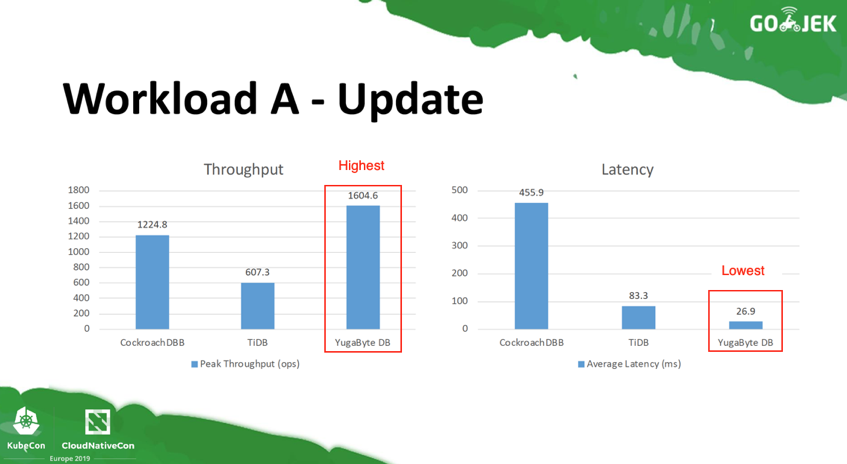
For Workload A with 50% Reads and 50% Writes, YugabyteDB comes out ahead of the other two databases in both throughput and latency.
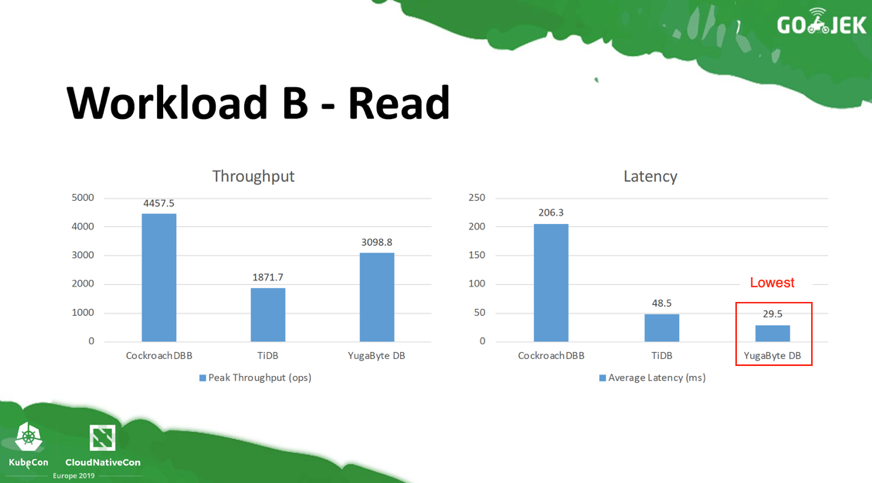
For Workload B with 95% Reads and 5% Writes, YugabyteDB is the leader for low latency operations and 2nd best when it comes to throughput.

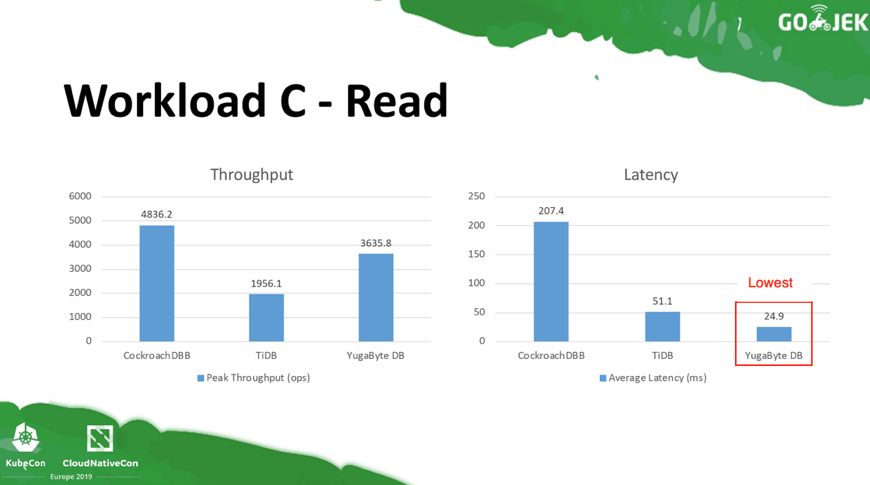
For Workload C with 100% Read operations, YugabyteDB shows characteristics similar to Workload B. It is the leader for low latency operations and the 2nd best for throughput.
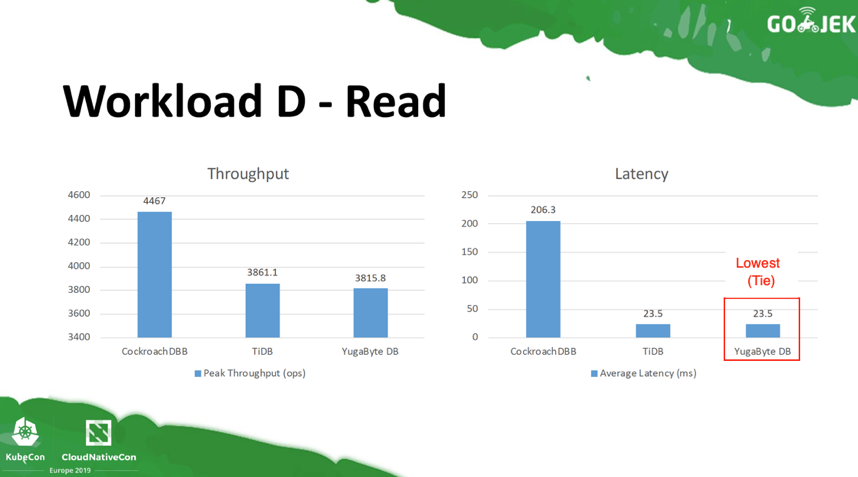
For Workload D with Read Latest operations (95% Read and 5% Write), YugabyteDB again comes out as the lowest latency database and throughput quite close to that of TiDB.

Workload E – Another Area for Collaboration
During their presentation, the GO-JEK team noted that they were not able to run Workload E (focused on Short Range Scans) on YugabyteDB. Needless to say, it was disappointing for us to hear. We would love to work with the GO-JEK team to fix the issue and have results published even for this workload. That would also give us an opportunity to understand why throughput is lower than our expectations for workload B-D.
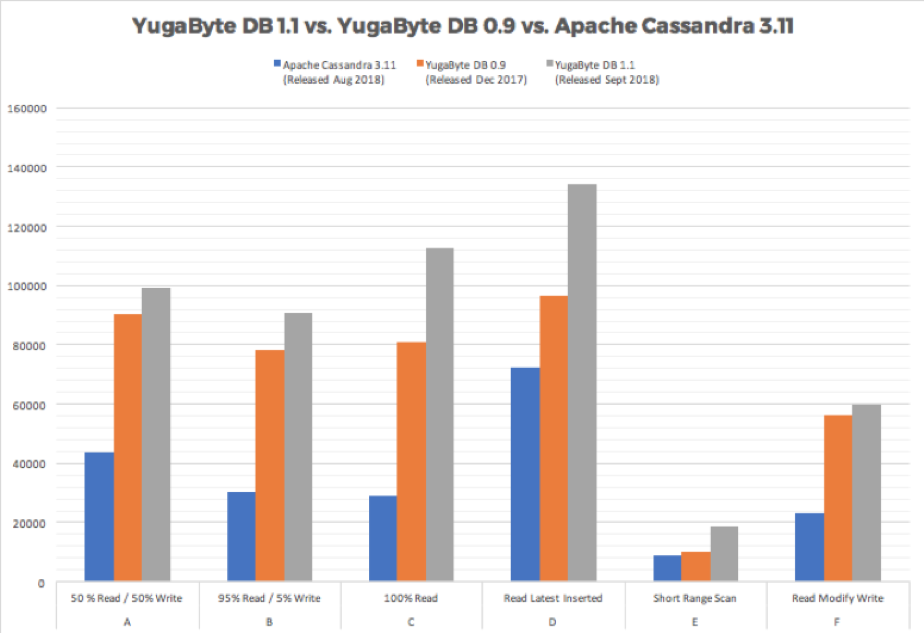
We have run YCSB using the YCQL API multiple times over the last couple years. “Technical Deep Dive into YugabyteDB 1.1” from September 2018 lists the results of our last run with results for even Workload E. The figure below summarizes those results for Throughput observed. Since our YCSB tests were performed on VM-based clusters and not Kubernetes-based clusters, we believe the error observed by GO-JEK team could be related to Kubernetes configuration and hence easily addressed.
Summary
GO-JEK team’s efforts to benchmark three cloud native, distributed SQL databases on Kubernetes are commendable. Given that our users frequently ask us for such benchmarks, we have been exploring this effort ourselves. We are very happy to see an established Kubernetes end-user such as GO-JEK take on this initiative and publish benchmarks as a neutral 3rd-party. We look forward to working with the GO-JEK team to not only correct the misinterpretations but also fix the benchmarking-related issues observed. Updated results from GO-JEK will certainly help more end-users like them make informed choices.
What’s Next?
- Compare YugabyteDB in depth to databases like CockroachDB, Google Cloud Spanner and Amazon Aurora.
- Get started with YugabyteDB on the cloud or container of your choice.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.



{kind=link}