How to: PostgreSQL Fuzzy String Matching In YugabyteDB
October 15, 2019
Before analyzing a large dataset that contains textual information, it’s important to scrub it and eliminate duplicates when necessary. To remove duplicates, you may need to compare strings referring to the same thing, but that may be written slightly different, have typos or were misspelled. Alternatively, you might need to join two tables on a column (let’s say on company name), and these can appear slightly different in both tables.
Fuzzy String Matching (or Approximate String Matching) is the process of finding strings that approximately match a pattern. Fuzzy string matching has several real-life use-cases including spell-checking, DNA analysis and detection, and spam detection. Fuzzy string matching enables a user to quickly filter down a large dataset to only those rows that match the fuzzy criteria.
In this blog we will show how PostgreSQL’s Fuzzy String matching works in YugabyteDB using the northwind dataset (download).
What’s Yugabyte DB? It is an open source, high-performance distributed SQL database built on a scalable and fault-tolerant design inspired by Google Spanner. Yugabyte’s SQL API (YSQL) and drivers are PostgreSQL wire compatible.
Prerequisites
Before we begin, please ensure that you have YugabyteDB installed and have loaded the northwind dataset onto the cluster. For a step-by-step guide on how to accomplish this, please visit: “How-to: The Northwind PostgreSQL Sample Database Running on a Distributed SQL Database”.
Using PostgreSQL Extensions in YugabyteDB
With YugabyteDB 2.0, many PostgreSQL extensions are now supported. Extensions package multiple SQL objects that can be added or removed as a single unit. One such extension that we are going to use for fuzzy string matching is called fuzzystrmatch.
CREATE EXTENSION fuzzystrmatch;
There are various algorithms that can do some form of fuzzy string matching, and in this blog we will go over the 3 most popular ones.
Soundex
The soundex algorithm matches similar-sounding names by converting them to the same soundex code. Every soundex code consists of a letter and three numbers, such as W252. The difference function takes 2 string parameters, and converts the two strings to their soundex codes. It then reports the number of matching code positions. Because soundex codes have four characters, the result ranges from zero to four, with zero being no match and four being an exact match.
Below is an example query using the difference function in YugabyteDB.
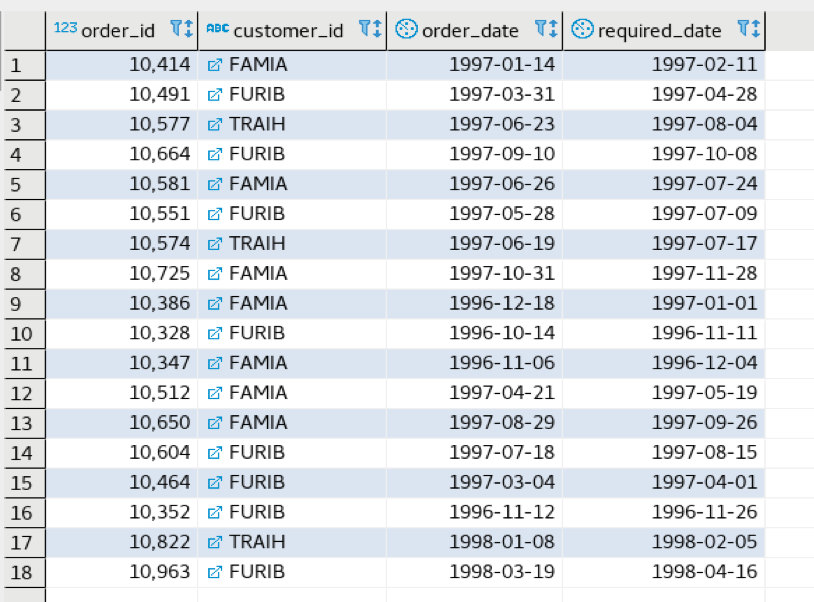
SELECT order_id,customer_id,order_date,required_date FROM orders WHERE difference(customer_id, 'FRA') > 2;
With the above query we will be getting rows that have the customer_id partially matching with ‘FRA’ using soundex.
Metaphone
Metaphone is similar to soundex. Metaphone algorithms are designed to produce an approximate phonetic representation, in ASCII, of regular “dictionary” words and names in English and some Latin-based languages. With metaphone, you can index words by their English pronunciation rather than how it is spelled. For example:
SELECT supplier_id,company_name,contact_title,contact_name
FROM suppliers
WHERE metaphone(contact_name,1) = metaphone('John',1)
Levenshtein
The Levenshtein distance between two words is the minimum number of single-character changes (i.e. insertions, deletions, or substitutions) required to change one word into the other. Thus, the smaller the number of edits to transform one word to the other, the closer the words are to each other.
Below is an example query using the levenshtein function in YugabyteDB.
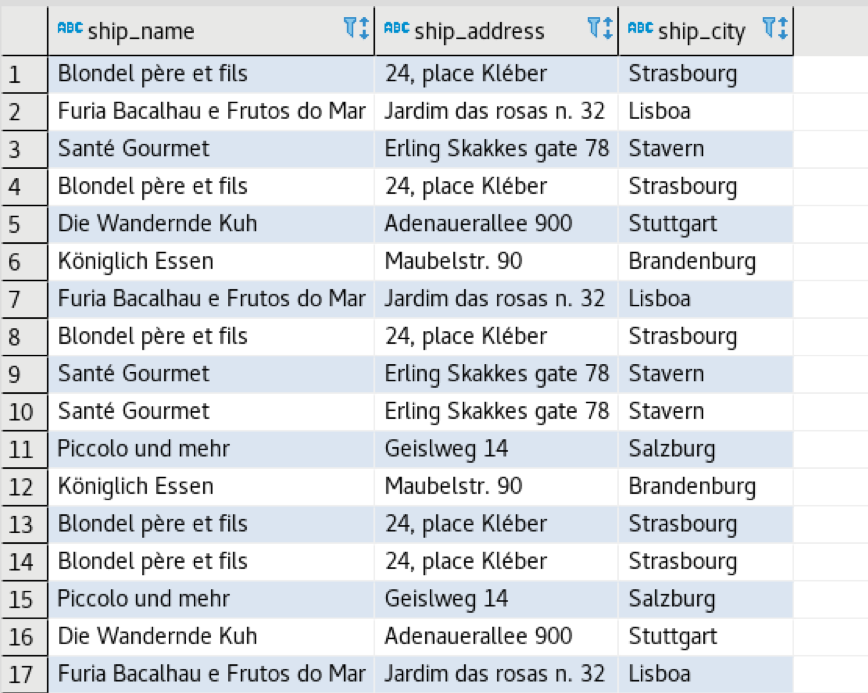
SELECT ship_name, ship_address,ship_city FROM orders WHERE levenshtein(ship_city, 'Strasbourg') < 8;
The above query will give us a list of 64 cities slightly matching “Strasbourg.”
Conclusion
That’s it! As you can see, it is staright-forward to start using PostgreSQL’s fuzzy matching extension inside of YugabyteDB without any modifications. If you are interested in checking additional extensions that YugabyteDB supports, check out the Doc page on extensions.
What’s Next?
- Compare Yugabyte DB in depth to databases like CockroachDB, Google Cloud Spanner and MongoDB.
- Get started with Yugabyte DB on macOS, Linux, Docker, and Kubernetes.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.

")
