Benchmarking an 18 Terabyte YugabyteDB Cluster with High Density Data Nodes
August 14, 2018
For ever-growing data workloads such as time series metrics and IoT sensor events, running a highly dense database cluster where each node stores terabytes of data makes perfect sense from a cost efficiency standpoint. If we are spinning up new data nodes only to get more storage-per-node, then there is a significant wastage of expensive compute resources. However, running multi-terabyte data nodes with Apache Cassandra as well as other Cassandra-compatible databases (such as DataStax Enterprise) is not an option. As DataStax Enterprise documentation notes:
To avoid problems, DataStax recommends keeping data per node near or below 1 TB. Exceeding this value has the following effects:
- Extremely long times (days) for bootstrapping new nodes.
- Impacts maintenance (day-to-day operations), such as recovering, adding, and replacing nodes.
- Reduces efficiency when running repairs.
- Significantly extends the time it takes to expand datacenters.
- Substantially increases compactions per node.
YugabyteDB is also a Cassandra-compatible database but is powered by a radically different replication and storage architecture. Replication is strongly consistent and is based on the Raft Consensus protocol. Storage engine, known as DocDB, is a Log Structured Merge (LSM) engine derived from Facebook’s RocksDB project. As highlighted in “How Does the Raft Consensus-Based Replication Protocol Work in YugabyteDB?”, bootstrapping of new nodes and removal of existing nodes are much simpler and more resilient operations when compared to the eventually consistent Cassandra-compatible databases.

Additionally, there are no background read repair and anti-entropy operations to worry about. This is because the write path is always strongly consistent based on synchronous replication. There is nothing to repair at read time (or in the background) and reads can be served correctly without using any quorum. These architectural differences mean that YugabyteDB can theoretically support much higher data density per node while remaining high throughput and low latency. Question is how much higher? This post aims to answer this question based on our internal testing.
Results
We had previously tested YugabyteDB with a maximum of 1.5 TB data per node. We are happy to share that we have now successfully tested a maximum of 4.5 TB data per node (for a total of 18 TB) on a four-node cluster. An interesting aspect of the testing is around the type of hardware used. Previously, we had tested on i3.2xlarge AWS instance types, which have the higher-end, direct-attached, 1.9TB NVMe SSDs as well as large RAM. However, this time around we used more basic, general purpose SSDs (gp2 EBS volumes) on c4.4xlarge machines with lesser RAM.
Note: An i3.2xlarge gives 400K random-read IOPS or 180K write IOPS, whereas gp2 EBS volumes max out at about 10K IOPS (and in practice much lesser).
Cluster Configuration
Nodes
- Cluster Size: 4 nodes in AWS
- Node Type: c4.4xlarge (16-vcpus, 30 GB RAM, 1 x 6000 TB gp2 EBS SSD)
- Replication Factor: 3
Data Size: 18 TB Total (4.5 TB Per Node)
- Number of KV records: 20 Billion
- Key + Value Size: ~300 Bytes
- Key size: 50 Bytes
- Value size: 256 Bytes (deliberately chosen to be not very compressible)
- Logical Data Set Size: 20 Billion keys * 300 Bytes = 6000 GB
- Raw Data including Replication: 6000 GB * 3 = 18 TB
- Per Node: 18TB / 4 = 4.5 TB
Initial Data Load Phase
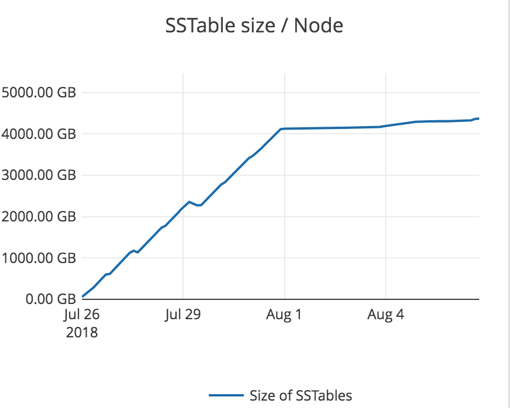
The data was loaded at a steady rate over about 6 days using the DataStax Enterprise documentation notes: CassandraKeyValue sample application. The graph below shows the steady growth in SSTables size at a node from July 26 to Aug 1, beyond which it stabilizes at 4.5 TB.
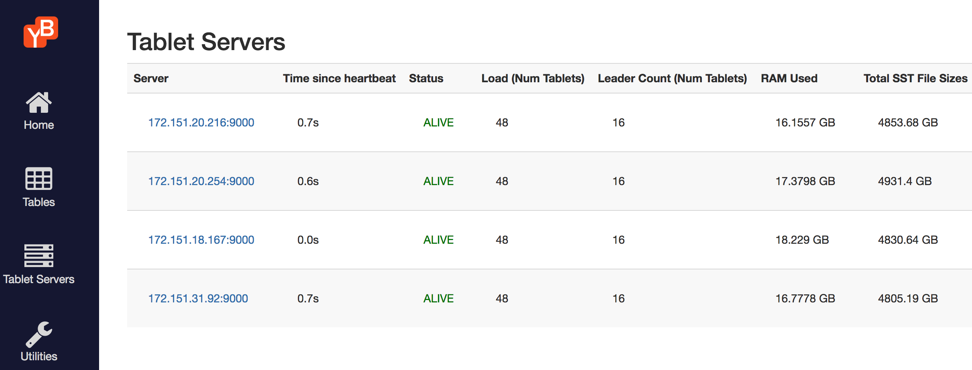
The figure below is from the yb-master Admin UI shows the tablet servers, number of tablets on each, number of tablet leaders and size of the on-disk SSTable files.
Workload Testing
Once data was loaded, we continued running the same application but under two different workload settings, a read heavy workload and a 100% write workload.
Read Heavy Workload (32 readers / 2 writers)
Starting the workload
% java -jar yb-sample-apps.jar -workload CassandraKeyValue --nouuid --nodes $CIP_ADDR --value_size 256 --max_written_key 19999999999 -num_threads_write 2 --num_threads_read 32
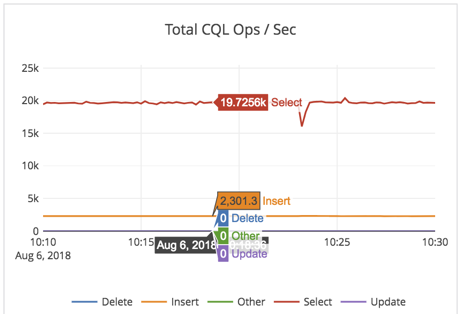
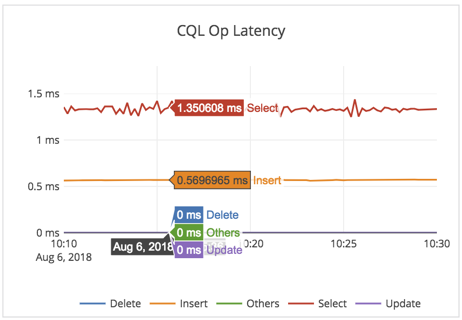
Performance metrics
iostat output

Observations
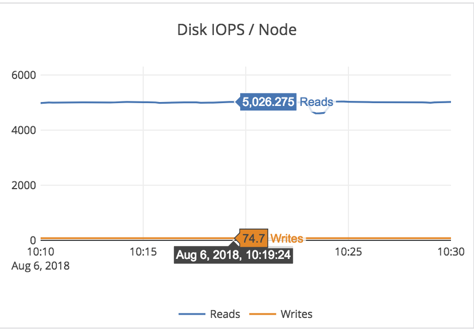
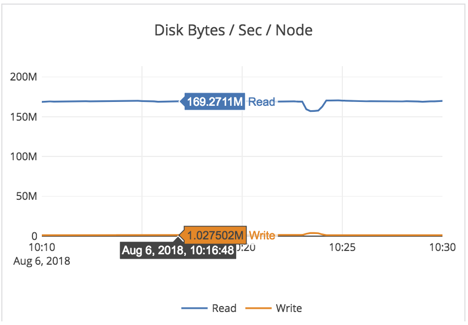
- Note that this is a random-read workload, with only 30GB of RAM for 4.5TB of data per-node. So every read will be forced to go to disk, and this workload is bottlenecked by the IO the EBS volume can support (as shown by the 96% %util on the iostat report above).
- The cluster throughput was at 19K reads/sec across the 4 nodes at 1.3ms latency on General Purpose SSD (gp2) EBS drive!
- As expected (from the iostat output above), CPU was not the bottleneck in this workload. CPU utilization was under 7% (user + sys CPU combined).
- On a per-node basis, we expect to see 19K/4 = 4750 reads from SSD. And that matches the 5K number we see in the Disk IOPS/node graph above.
Summary: The cluster is working optimally and YugabyteDB is very effective in caching metadata blocks (such as index blocks and bloom filter blocks in the limited amount of RAM) and only going to the disk for 1 data block.
100% Write Workload (64 writers)
Starting the workload
% java -jar yb-sample-apps.jar -workload CassandraKeyValue --nouuid --nodes $CIP_ADDR --value_size 256 --max_written_key 19999999999 -num_threads_write 2 --num_threads_read 32
Performance metrics
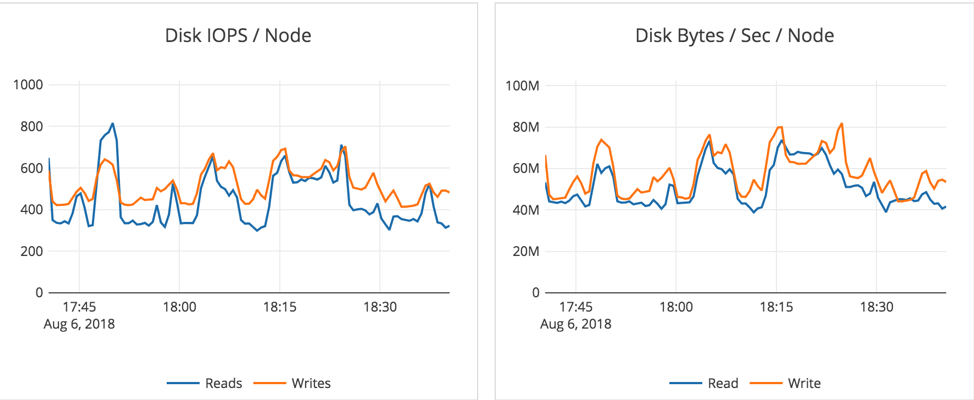
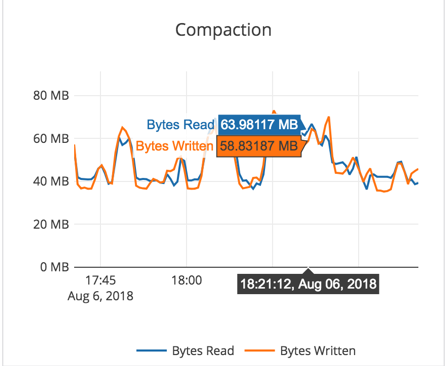
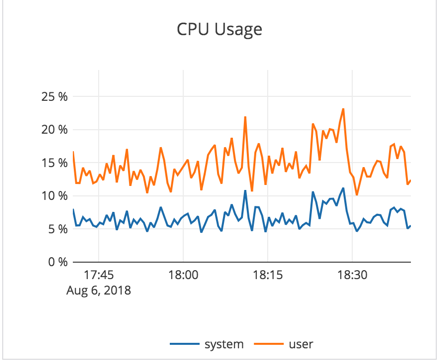
Observations
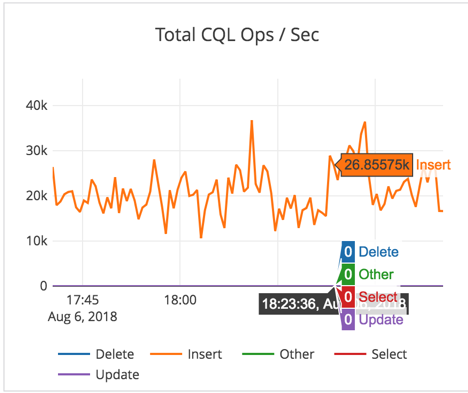
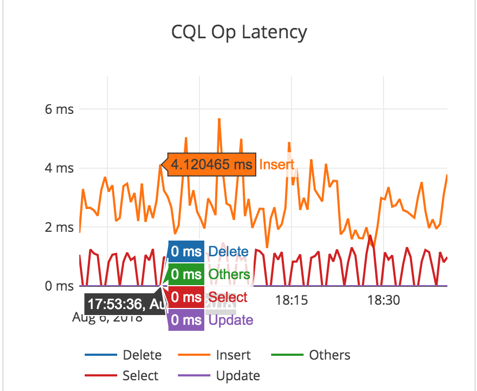
- We see about 20-25K write IOPS on an average at about 3-4ms latency.
- For write heavy workload, there is more variability because of the use of General Purpose SSD (gp2) EBS volumes. This variability arises from the need to perform periodic compactions. [Note: For time series data such as IoT or KairosDB-like workloads, YugabyteDB doesn’t need to perform aggressive compactions, and the results will be even better. But this particular experiment is running an arbitrary KV workload, and as expected puts higher demand on the system.]
- Instead of using 1x6000GB EBS volume per node, using 2x3000GB EBS volumes might have been a better choice to get more throughput. When the disk R + W throughput reaches its max (around 150MB/sec) during compactions, the latencies also go up a bit.
- To allow sufficient room for foreground operations on a low-end gp2 SSD volume based setup, we reduced the default quota settings for “compaction/flush rate” from 100MB/sec to 30MB/sec.
- On i3* instance types with direct attached nvme SSDs which have much more disk IOPS and throughput, this observed variability should be minimal for a similar workload.
Reliable & Rapid Scaling
Along with the above workload testing, we also tested the impact of high data density on horizontal scaling by adding a 5th node to the 18TB cluster. Driven by YugabyteDB’s highly resilient Raft-based auto-rebalancing of tablet leaders/followers across all nodes, the new node drew about 3.8 TB from the 4 nodes (with each node contributing about 0.95 TB of data).
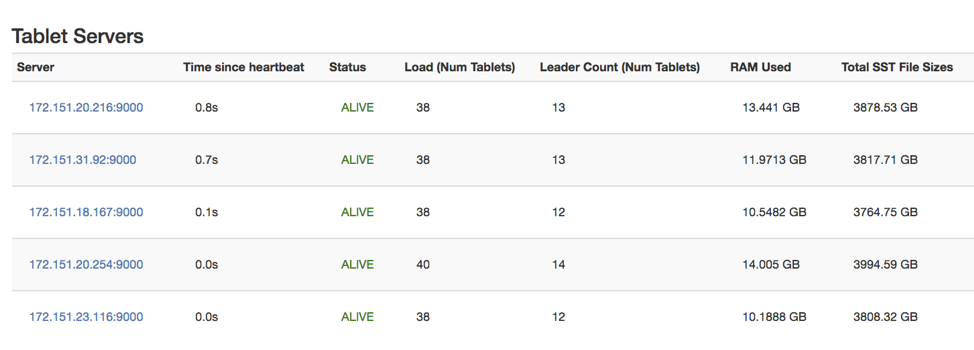
The new node became operational as soon as the first few tablets moved even though the entire rebalancing took about 7 hours to complete. Other Cassandra-compatible databases are known to be highly unreliable during new node bootstrapping, a process that can even take days for multi-terabyte data moves.
Summary
Running a high performance database cluster with highly dense data nodes can lead to huge cost savings. However, legacy NoSQL databases such as Apache Cassandra were never designed to handle multi-terabytes of data per node. We designed YugabyteDB so that it does not suffer from the same limitation. As of result, YugabyteDB is now able to run 4.5 TB data nodes with high reliability and performance while easily handling day 2 operational tasks such as adding/removing nodes. At the same time, we believe that improving data density without compromising performance is a never-ending journey. We are committed to making YugabyteDB even better in this regard. Subscribe to our blog at the bottom of this page and stay tuned with our progress.
What’s Next?
- Read more about YugabyteDB’s performance benchmarks.
- Compare YugabyteDB to databases like CockroachDB, Amazon Aurora and MongoDB.
- Get started with YugabyteDB.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.


