Presto on YugabyteDB: Interactive OLAP SQL Queries Made Easy
November 14, 2018
Presto is a distributed SQL query engine optimized for OLAP queries at interactive speed. It was created by Facebook and open-sourced in 2012. Since then, it has gained widespread adoption and become a tool of choice for interactive analytics. It supports standard ANSI SQL, including complex queries, aggregations, joins, and window functions. It has a connector architecture to query data from many data sources such as SQL and NoSQL databases as well as traditional big data platforms such as Hive/Hadoop. Presto can work not only can work off a single database at a time, it can also join data across multiple databases easily.
The question to ask is why would you ever need to query a NoSQL database with a SQL API or even join data from SQL and NoSQL databases together? The answer lies in the structure of OLAP queries that help users derive insights from data that has already been created by the standard OLTP databases. These queries usually go across multiple tables in one or more disparate data sources and are often performed in an ad-hoc manner by an end user.
YugabyteDB is a cloud native, transactional and high performance database that is both multi-API and multi-model. It supports 2 NoSQL APIs, namely the Cassandra-compatible YCQL and the Redis-compatible YEDIS, as well as an SQL API called YSQL that is PostgreSQL compatible. This post describes how you can run Presto queries on YCQL API as well as join data across the YCQL and YSQL APIs.
Architecture – Presto on YugabyteDB
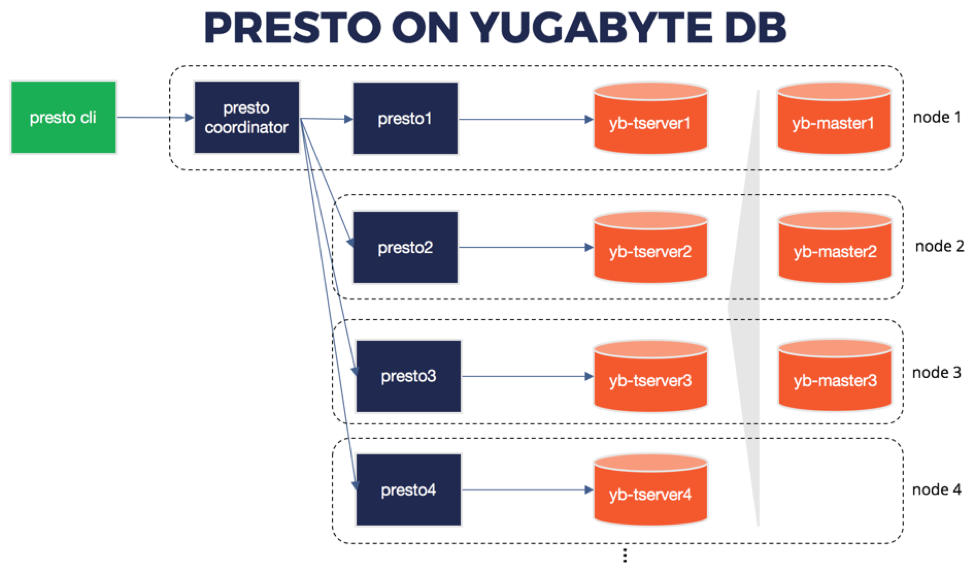
A YugabyteDB universe consists of a cluster of nodes running two sets of processes – YB-Master and YB-TServer. The YB-Master processes are responsible for keeping system metadata, coordinating system-wide operations such as create/alter drop tables, and initiating maintenance operations such as load-balancing. The YB-TServer processes are responsible for hosting/serving user data (e.g, tables).
Presto is also a distributed system that runs on a cluster of nodes. A full installation includes a coordinator process and multiple worker processes. To enable Presto querying over YugabyteDB tables, the Presto coordinator process should be started on one of the machines in the cluster, and the worker processes are started up on all of the other machines.
SQL queries are submitted from a client such as the Presto CLI or JDBC to the Presto coordinator. The Presto coordinator parses, analyzes and plans the query execution, then distributes the processing to the Presto workers. Detailed instructions for configuring Presto with YugabyteDB’s YCQL API are available on our documentations site.
Each of the Presto workers accesses data from the local YB-TServer process. A subset of the SQL query is processed by the worker (including filtering, partial aggregations and joins), before returning the results to the coordinator for final processing. A 4 node Presto-on-YugabyteDB architecture is shown below for reference.
Use Case #1 – Rich SQL Queries over YCQL
Presto can be used to run rich SQL queries over YCQL tables including complex queries with joins, aggregations, and window functions.
Consider a time series use case where IoT devices are sending sensor data to the database. Before running the queries, you create the tables and load data through the Cassandra compatible YCQL tools such as cassandra-loader of Spark/Kafka connectors. The device_data table stores all the readings sent by sensors along with the associated timestamp.
DROP TABLE myapp.device_data; CREATE TABLE myapp.device_data ( device_id int, ts text, temperature float, humidity float, pressure float, PRIMARY KEY (device_id, ts) ); INSERT INTO myapp.device_data (device_id, ts, temperature, humidity, pressure) VALUES (101, '2018-09-01 10:00:00', 78.5, 45, 30); INSERT INTO myapp.device_data (device_id, ts, temperature, humidity, pressure) VALUES (101, '2018-09-01 10:01:00', 78.6, 45, 30); …
Now start up the Presto client to run a variety of SQL queries over these YCQL tables.
Query #1 : Find maximum temperature reading for a device during a time period
This query uses aggregate functions along with group-by construct.
SELECT max(temperature) maxtemp
FROM device_data
WHERE device_id = 101;
maxtemp
---------
78.7
(1 row)Query #2 : Find the devices reporting the highest average temperatures during a time window
This query sorts the results based on aggregate values.
SELECT device_id, avg(temperature) avgtmp
FROM device_data
WHERE ts BETWEEN '2018-09-01 10:00:00' AND '2018-09-01 10:05:00'
GROUP BY (device_id)
ORDER BY avg(temperature) DESC LIMIT 2;
device_id | avgtmp
-----------+--------
102 | 79.6
101 | 78.6
(2 rows)Query #3 : Return the rolling average temperature over time windows for a device
This query uses the advanced window functions with OVER clause.
SELECT device_id, ts,
avg(temperature) OVER (PARTITION BY device_id ORDER BY ts) rolling_avg
FROM device_data
WHERE device_id = 101
ORDER BY device_id LIMIT 5
device_id | ts | rolling_avg
-----------+---------------------+-------------
101 | 2018-09-01 10:02:00 | 78.6
101 | 2018-09-01 10:03:00 | 78.575
101 | 2018-09-01 10:04:00 | 78.58
101 | 2018-09-01 10:00:00 | 78.5
101 | 2018-09-01 10:01:00 | 78.55
(5 rows)Use Case #2 – Joining YCQL and YSQL Data
As highlighted previously, one of the unique use cases enabled by Presto involves joining data across multiple data sources. Given that YugabyteDB is a multi-model and multi-API database, Presto can be configured to connect to each of the APIs to query and join across them.
For example, consider that device metadata information is stored in a Postgres compatible YSQL table. A couple of preparation steps:
- Step 1: Configure Presto to connect to Postgres tables (in a manner similar to Cassandra). Details here.
- Step 2: Create and load the YSQL table storing device metadata.
CREATE TABLE store.device_info ( device_id int primary key, device_type text, loc_city text, loc_state text, loc_country text ); INSERT INTO store.device_info VALUES (101, ‘smart-sensor-42’, ‘San Jose’, ‘CA’, ‘USA’); INSERT INTO store.device_info VALUES (102, ‘smart-sensor-39’, ‘San Jose’, ‘CA’, ‘USA’); ...
You can now join the sensor data stored in YCQL tables (from Use Case 1) with the device metadata stored in YSQL tables as shown below.
Query #4 :- Find the device_type and location of the device reporting the highest average temperature
SELECT d.device_id, avg(d.temperature) avgtmp,
i.device_type, i.loc_city
FROM cassandra.myapp.device_data d, postgresql.store.device_info i
WHERE d.device_id = i.device_id
GROUP BY (d.device_id)
ORDER BY avg(d.temperature) DESC LIMIT 2;
device_id | avgtmp | device_type | loc_city
-----------+--------+-----------------+----------
101 | 78.5 | smart-sensor-42 | san jose
(1 row)Interactive SQL The Easy Way
Presto is a powerful SQL engine that supports a broad set of SQL functionality for interactive OLAP use cases. It can be easily configured to connect to, query and join across YugabyteDB tables including Cassandra-compatible YCQL and Postgres-compatible YSQL tables, as well as external data sources such as MySQL and Hive.
What’s Next?
- Integrate Presto to query YugabyteDB
- Compare YugabyteDB to databases like Amazon DynamoDB, Apache Cassandra, MongoDB and Azure Cosmos DB.
- Get started with YugabyteDB with a local cluster on your laptop
- Contact us to learn more about licensing, pricing or to schedule a technical overview.


