Rewind, Clone, and Time-Travel with YugabyteDB
July 21, 2025
Imagine accidentally deleting a critical row in production, or wanting to test a schema change on real data without risking the original. Every developer, SRE, or data engineer has wished for a Ctrl+Z for their database at some stage.
With YugabyteDB, that wish is granted.
In this post, we’ll explore how YugabyteDB’s point-in-time capabilities, including point-in-time recovery, instant database cloning, and time travel queries, make it easy to rewind your data, spin up lightweight clones, and explore historical states with precision.
What are YugabyteDB Point-in-Time Capabilities and Why Do We Need Them?
In our modern data-driven world, mistakes happen, and when they do, the consequences can be costly.
Human or software error in SQL (interactive or programmatic) is the most common customer-side cause of data loss, whether it’s an accidental delete, an incorrect update, or a misapplied schema change.
Additionally, organizations struggle to test new features safely using real, up-to-date data.
Traditional test environments often lag behind production or lack the ability to reflect the system’s exact state at a specific moment, making accurate testing difficult.
To help users solve these problems, YugabyteDB provides a range of point-in-time (PIT) capabilities that give you full control over your data’s past.
- Point-in-Time Recovery (PITR):
Rewind your entire database to a precise moment in time within a configurable retention period. Ideal for recovering from accidental drops or destructive operations without needing a full restore. - Time-Travel Queries:
Query your data as of a point in time in the past. This is useful for recovering deleted rows or performing forensic analysis without affecting live data. - Instant Database Cloning:
Instantly create zero-copy database clones as of any point in time. Useful to safely test changes and extract clean data for recovery, all without disrupting production.
Disaster at 9:15 AM. Recovered by 9:25 AM — Thanks to PITR
In this example, Adam, a DBA managing a busy production database, accidentally runs a DROP TABLE command and deletes a critical table at 9:15 AM. He realized the mistake at 9:25 AM. In a traditional setup, Adam would be forced to restore from the last full backup, potentially taken hours earlier, say at 3:00 AM, which is less than ideal.
Restoring from the backup can result in:
- Data loss since last backup: Any data added after the last backup is permanently lost. In this example, the company stands to lose over six hours of data. This results in a non-zero recovery point objective (RPO), as recovery only returns the system to the point of the last backup.
- Lengthy restore time (High RTO): Restoring a backup involves copying all data back into the cluster, which can take anywhere from several minutes to several hours, depending on the size of the database. This leads to a high recovery time objective (RTO), meaning it takes a significant amount of time to get the system back online.
YugabyteDB’s point-in-time recovery (PITR) solves these issues.
Adam can simply rewind the database to 9:14:59 AM, just before the table was dropped (we support microsecond precision). Full restores can take hours to finish, but YugabyteDB’s PITR feature solves the issue with minimal downtime as PITR is a fast, efficient operation that completes in just a few seconds.
The timeline below shows how a human error at 9:15 AM was resolved within seconds, once detected using the PITR operation.
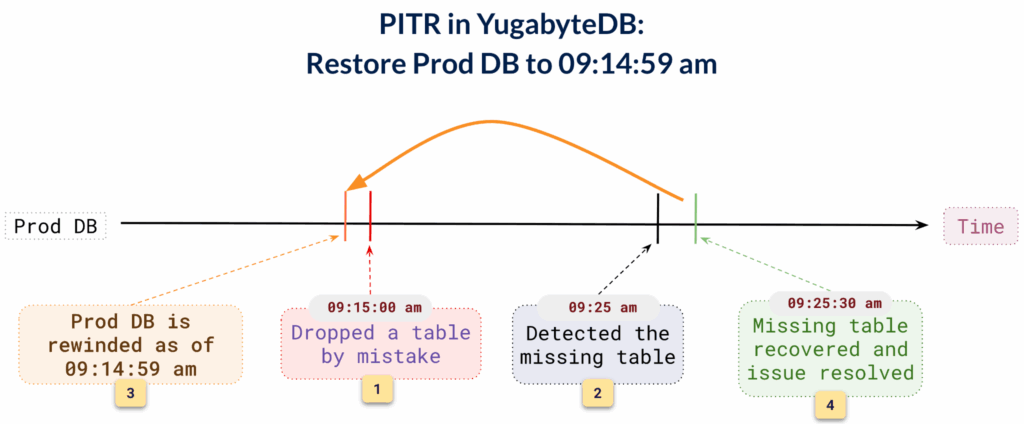
PITR in YugabyteDB achieves fast point-in-time restore by avoiding the expensive operation of physically copying the backup, performing the restore, and then sequentially replying WAL logs.
Instead, when a customer initiates a PITR, the system automatically sets a read timestamp on the underlying tablets to the specified recovery time. This allows the system to instantaneously view the database exactly as it was at that moment in time.
How Time-Travel Querying Saves the Day
Not all mistakes require a full database rewind. Imagine that at 9:15 AM, a few rows were accidentally deleted due to a manual query or an application bug. The issue wasn’t discovered until 10:45 AM, well after new, valid data had been added to the database.
Rewinding the entire database using PITR isn’t an option here, as you would undo the valid data added between 9:15 AM and 10:45 AM.
YugabyteDB’s time travel query capability provides a precise, non-disruptive solution.
You can simply query the table as it existed at 9:14:59 AM, just before the delete occurred. From there, it’s easy to isolate the missing rows, export them, and reinsert them into the production database, without affecting the new data that was added after the mistake.
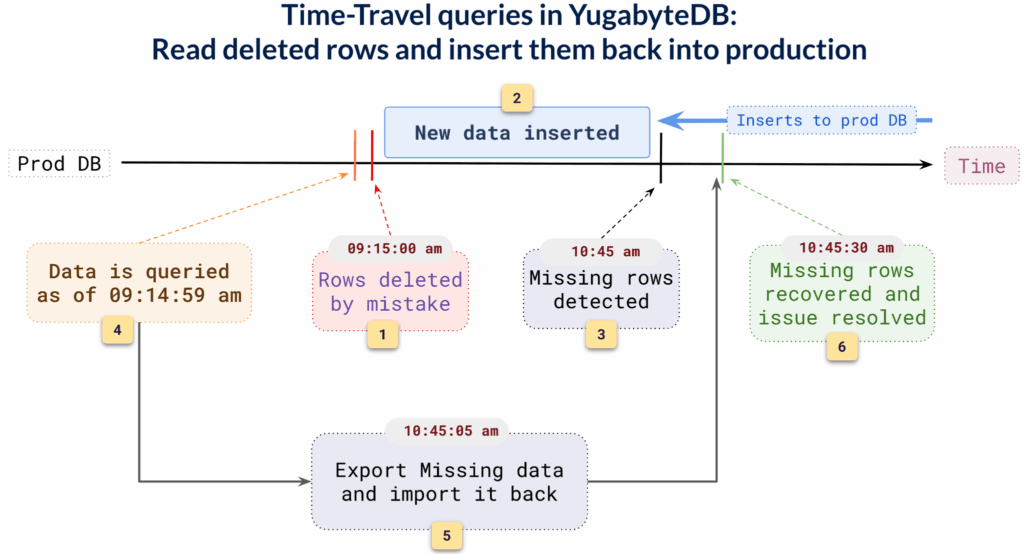
This approach allows for targeted recovery. The missing rows are recovered back into the system without losing new data and with minimal data copying (avoiding full restores and massive data movement). In just a few steps, lost data is restored cleanly, safely, and without downtime.
Clone. Investigate. Recover.
Sometimes, the damage runs deeper than a single table or a few rows. Imagine a scenario where a bad deployment script or faulty application upgrade corrupts data across multiple tables.
The problem isn’t immediately obvious, and by the time it’s detected, new data is still being written to the system. Rewinding the entire database isn’t feasible, and trying to fix it manually in production is risky and time-consuming.
This is where YugabyteDB’s instant database cloning comes in.
With just a single SQL command, you can create a full clone of the production database as of a known good timestamp. The operation is fast and lightweight because it doesn’t involve physically copying data. Instead, the clone shares the same underlying storage, but remains fully isolated. In other words, any changes made to the clone have no impact on the original database.
In the cloned database, you can:
- Inspect the data as it existed before the corruption
- Identify what went wrong
- Extract clean versions of the affected rows or tables
Once verified, you can safely re-import the corrected data into the live production system, all without disrupting users or compromising new data.
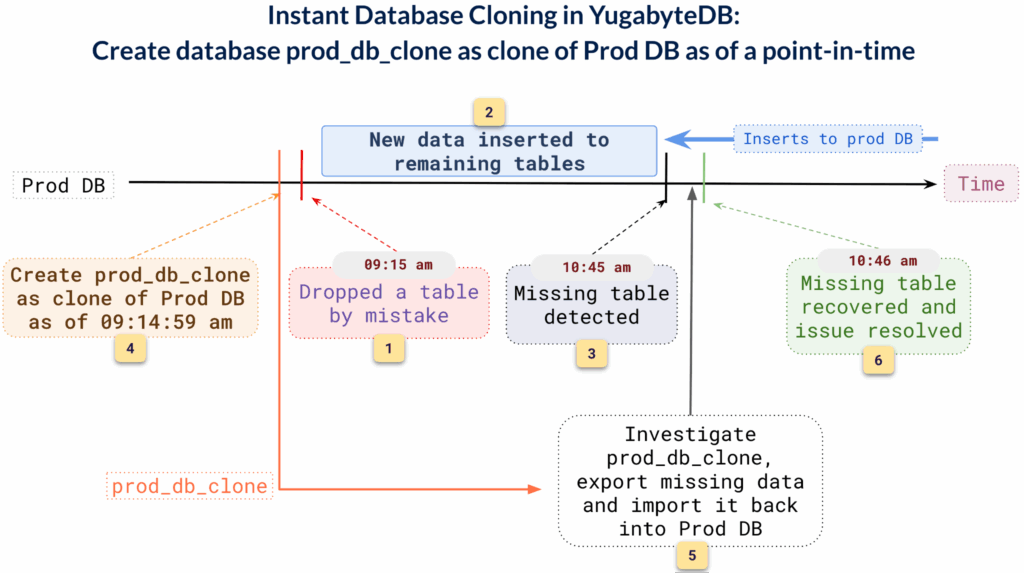
This approach allows teams to recover data with confidence, especially in complex cases where the full scope of the error isn’t immediately known.
With cloning, recovery becomes precise, controlled, and completely downtime-free.
Like Git for Databases: Safely Test with Instant Clones
Testing new features on real data is critical, but it can be a major challenge to do so without risking your production environment.
Whether it’s a schema migration, a new API, or a performance test, teams often need a staging environment that mirrors production as closely as possible. Traditionally, this involves setting a separate staging environment and restoring a backup of the production database there.
This solution is slow to provision, resource-intensive, and provides an outdated version of the production database.
Additionally, the emergence of agentic AI means that AI agents need to interact with real production data more than ever. Because these agents are inherently non-deterministic and prone to hallucinations, allowing them to operate directly on production systems introduces unacceptable risks of data corruption.
To safely experiment, test, or run AI workloads, it becomes necessary to create isolated copies of production data where AI agents can operate freely without the risk of impacting the actual production environment.
YugabyteDB’s instant database cloning allows you to create a fully independent copy of your production database in seconds.
The clone uses copy-on-write, meaning no physical data copying takes place. The clone database uses a pointer to the original data files and then tracks changes separately. This makes the clone operation fast, efficient, and storage-friendly.
Better yet, the clone is completely detached from production, so any change made to the clone stays in the clone. Developers are free to run experiments, test schema changes, simulate edge cases, or replay workloads, without any risk of impacting live users or data.
Think of it like Git for databases: you create a branch (a clone), test and iterate freely, and simply delete it when you’re done, with zero impact on the original database.
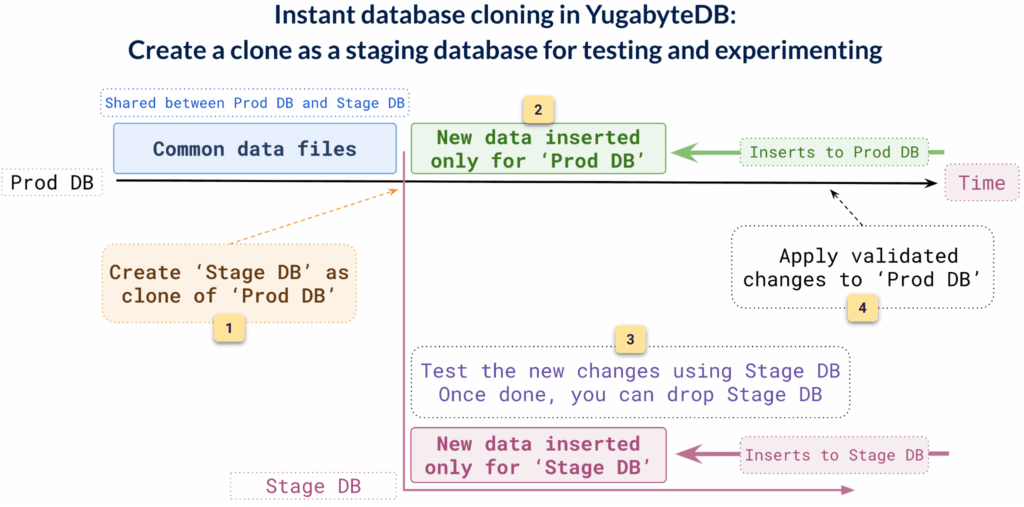
The result? A faster, safer, and more realistic way to test changes using up-to-date, production-grade data. All with zero risk to the original database and without the overhead of full restores or backup pipelines.
Conclusion: Time Travel Features That Put You in Control
From fixing critical errors to enabling safe testing, YugabyteDB’s point-in-time capabilities offer a powerful, unified solution for managing data across time, all with minimal effort and no downtime.
Below is a quick summary of the point-in-time (PIT) capabilities in YugabyteDB and their characteristics.
| Purpose | Capability | Characteristics |
| Rewind to PIT | Point-in-Time Recovery | Fast, rewind database in-place |
Clone to PIT  | Instant Database Cloning | Fast, zero-copy, new database instance |
| Inspect at PIT | Time-Travel Queries | Instant, read same database |
Together, these capabilities turn painful, high-risk operations into fast, routine workflows. This allows developers, DBAs, and DevOps teams to move quickly, recover confidently, and test safely.


