TPC-C Benchmark: 10,000 Warehouses on YugabyteDB
July 28, 2020
We are excited to announce that the TPC-C benchmark implementation for YugabyteDB is now open source and ready to use! While this implementation is not officially ratified by the TPC organization, it closely follows the TPC-C v5.11.0 specification.
For those new to TPC-C, the aim of the benchmark is to test how a database performs when handling transactions generated by a real-world OLTP application. This blog post shows the results of running the TPC-C benchmark in addition to outlining our experience of developing and running a TPC-C benchmark against YugabyteDB.
Results
The results of running the above TPC-C benchmark with 10, 100, 1000, and 10,000 warehouses on a YugabyteDB cluster running in a single zone of AWS are shown below.
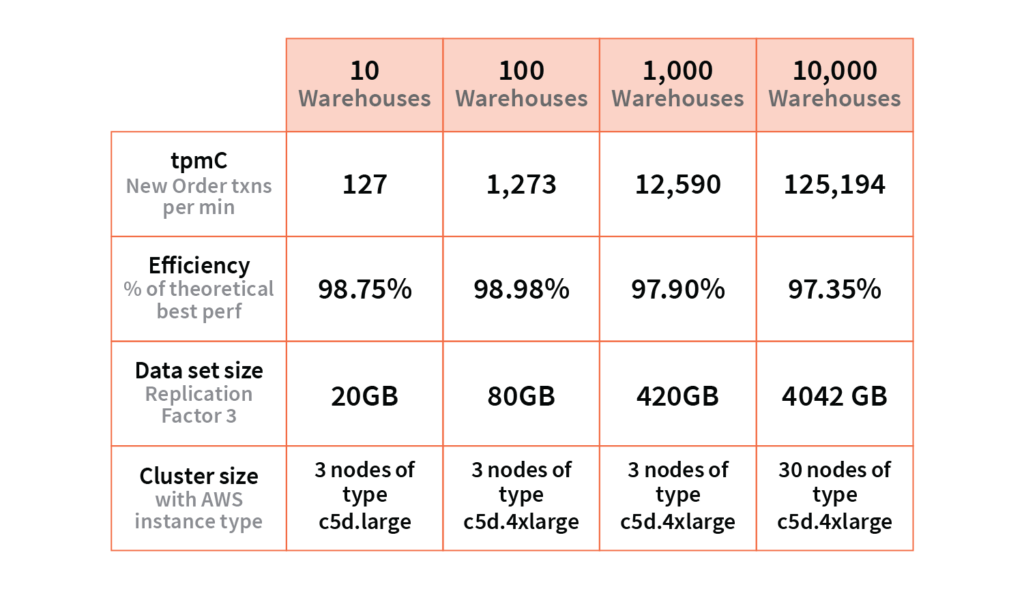
You can find the instructions to reproduce the above results in the benchmarking section of YugabyteDB docs. The rest of this post goes into some details about the TPC-C workload itself, how we built the benchmark tool, and our considerations when running it in public clouds.
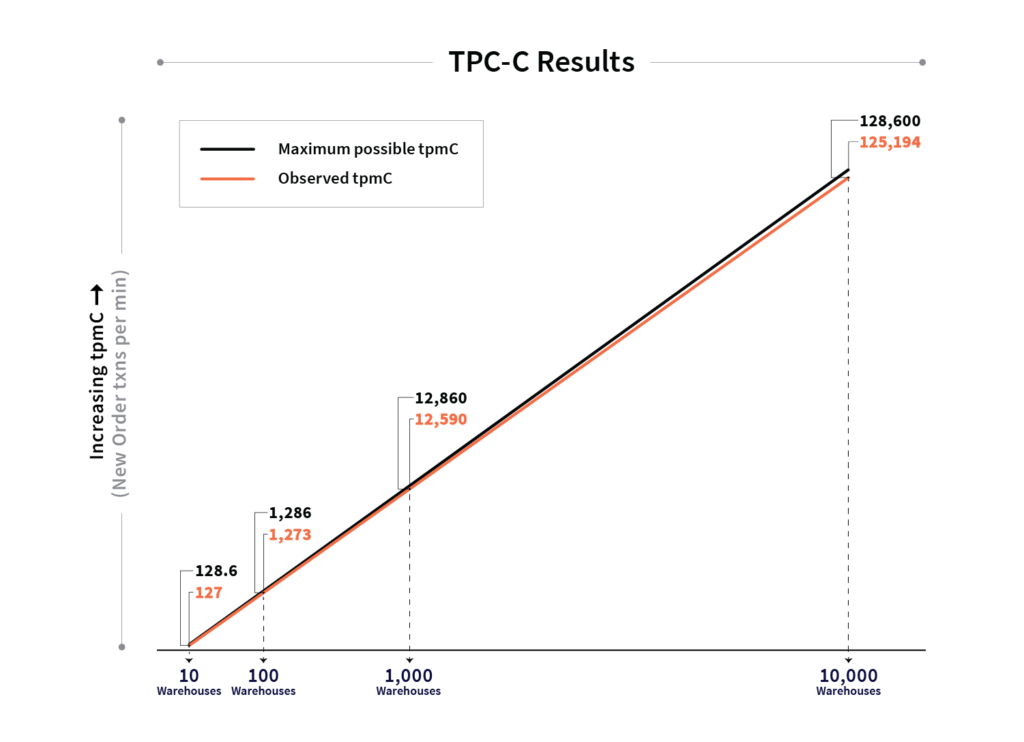
Linear TPC-C scalability in the context of a distributed relational database refers to the fact that support for a larger number of warehouses without compromising high efficiency can be achieved by simply adding new nodes to the cluster. As shown below, we are excited to prove this property in the context YugabyteDB. YugabyteDB shows a tpmC value of 12,590 (while running 1000 warehouses on a 3 node cluster of c5d.4xlarge nodes) which is 97.90% of the theoretical maximum. In order to handle scaling the workload up by a factor of 10 from 1,000 to 10,000 warehouses, the cluster was scaled up to 30 nodes. This resulted in 10 times as many transactions per second being handled, for a tpmC of 125,194 (which is 97.35% of the theoretical maximum possible tpmC value of 128,600).
Understanding the TPC-C workload
TPC-C models a business that has a warehouse, multiple districts, and inventory for those warehouses, as well as items and orders for those items. The TPC-C benchmark tests five different transaction workloads, which are briefly described below.
- The New Order transaction simulates entering a new order through a single database transaction. This transaction, which forms the backbone of the workload, has a high frequency of execution with low latency requirements to satisfy online users. About 1% of these transactions will simulate failures to test transaction rollback.
- The Payment transaction updates the customer’s balance and reflects the payment on the district and warehouse sales statistics. This transaction includes non-primary key access to the CUSTOMER table.
- The Order Status transaction queries the status of a customer’s last order.
- The Delivery transaction processes a batch of new orders which are not yet delivered, executed in the background using a queuing mechanism.
- The Stock Level transaction determines the number of recently sold items that have a stock level below a specified threshold and therefore would need to be restocked.
The complete entity-relationship diagram for the TPC-C workload is shown below.
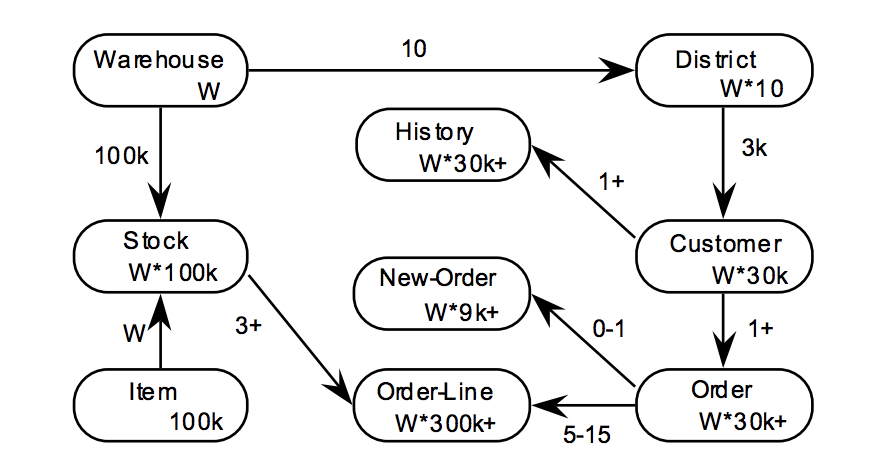
The number of warehouses is the key configurable parameter that determines the scale of running the benchmark. Increasing the number of warehouses increases the data set size, the number of concurrent clients as well as the number of concurrently running transactions. A warehouse can have up to ten terminals (point of sale or point of inquiry counters) which generate transactions such as entering a new order, settling payments, and looking up the status of an existing order. TPC-C also models other behind the scenes activities at warehouses that would result in transactions, such as finding items that need to be restocked or marking items as delivered.
The TPC-C benchmark tool
TPC-C is considered an industry standard when it comes to benchmarking the performance of a relational database (aka RDBMS). However, there is no standard, out of the box implementation for the TPC-C benchmark. We reviewed a number of open source TPC-C implementations, and finally forked oltpbench as a starting point for our benchmark a few months ago. We added a number of enhancements to our fork, some of which are listed below.
While oltpbench could load data and generate queries to stress the database, it did not meet some of the key requirements of the TPC-C specification, such as being able to specify keying time and think time. TPC-C uses a remote terminal emulator (RTE) to maintain the required mix of transactions over the performance measurement period. The keying time represents the time spent entering data at the terminal and the think time represents the time spent, by the operator, to read the result of the transaction at the terminal before requesting another transaction. Each transaction has a minimum keying time and a minimum think time.
The next issue was that oltpbench establishes direct connections to the underlying database. The TPC-C benchmark requires that each user terminal maintain a persistent connection to the database. However, the number of connections increases with the number of warehouses, making oltpbench‘s implementation of the benchmark not very scalable. To resolve this issue, a connection pool can be used to multiplex these requests using fewer physical connections. Therefore, we added the Hikari connection pool to the benchmark tool to handle a very high number of concurrent clients.
Sharding the TPC-C tool to benchmark at scale
As we kept ramping up the number of warehouses to increase the scale of the benchmark, we noticed that the TPC-C tool itself was becoming a bottleneck in terms of the CPU and the memory it consumed. As a result, it could not generate as many transactions per second across an ever increasing number of warehouses. Additionally, the threading model of the benchmark client would spawn one thread per warehouse, which eventually resulted in the JVM not being able to spawn new threads.
We first optimized the CPU and memory used by the benchmark tool. Subsequently, we made the tool scalable by sharding it to run the benchmark for a subset of warehouses on different nodes. These partial benchmarks were run concurrently from multiple nodes. Each sharded execution generated a partial result for the TPC-C benchmark which was combined to form the final result. This approach has the advantage that we can scale to much larger numbers of warehouses. Note that enhancing the tool to change the threading model, which would enable running an even larger number of warehouses per node, is a work in progress.
What’s Next?
Since v2.1 (released in February 2020), we have improved the TPC-C performance of YugabyteDB by ~100x – going from running 10 warehouses to 1000 warehouses on a 3-node cluster. Additionally, we are now able to run 10000 warehouses on a 30-node cluster with high efficiency. The current set of benchmarks on YugabyteDB v2.2 establish a great baseline for performance and also demonstrate linear scalability. While this progress is a noteworthy achievement, the quest for higher performance is never complete. We aim to improve the efficiency of a 3-node cluster even further and also scale to a larger number of warehouses on larger clusters.
You can run these benchmarks on your own by simply following our TPC-C documentation. Join our community if you have questions or are interested in contributing to this initiative. And if this kind of work is your cup of tea, we’re hiring and would love to talk to you!


