Discover a New Way to Learn About Distributed SQL, YugabyteDB, and YCQL
January 27, 2023
Yugabyte University is proud to announce the release of a new self-paced course, YugabyteDB YCQL Development.
Yugabyte Cloud Query Language (YCQL) is a semi-relational SQL API compatible with Apache Cassandra’s Query Language. YCQL supports strongly consistent secondary indexes, a native JSONB column type, and distributed transactions.
About YugabyteDB YCQL Development
Designed for developers new to distributed SQL database development, this three hour self-paced course provides a unique learning experience.
By watching the informative course videos and completing hands-on lab exercises, you learn the fundamentals of YCQL data definition language (DDL) and data manipulation language (DML), as well as diving deep into the internals of YugabyteDB, a cloud native distributed SQL database.
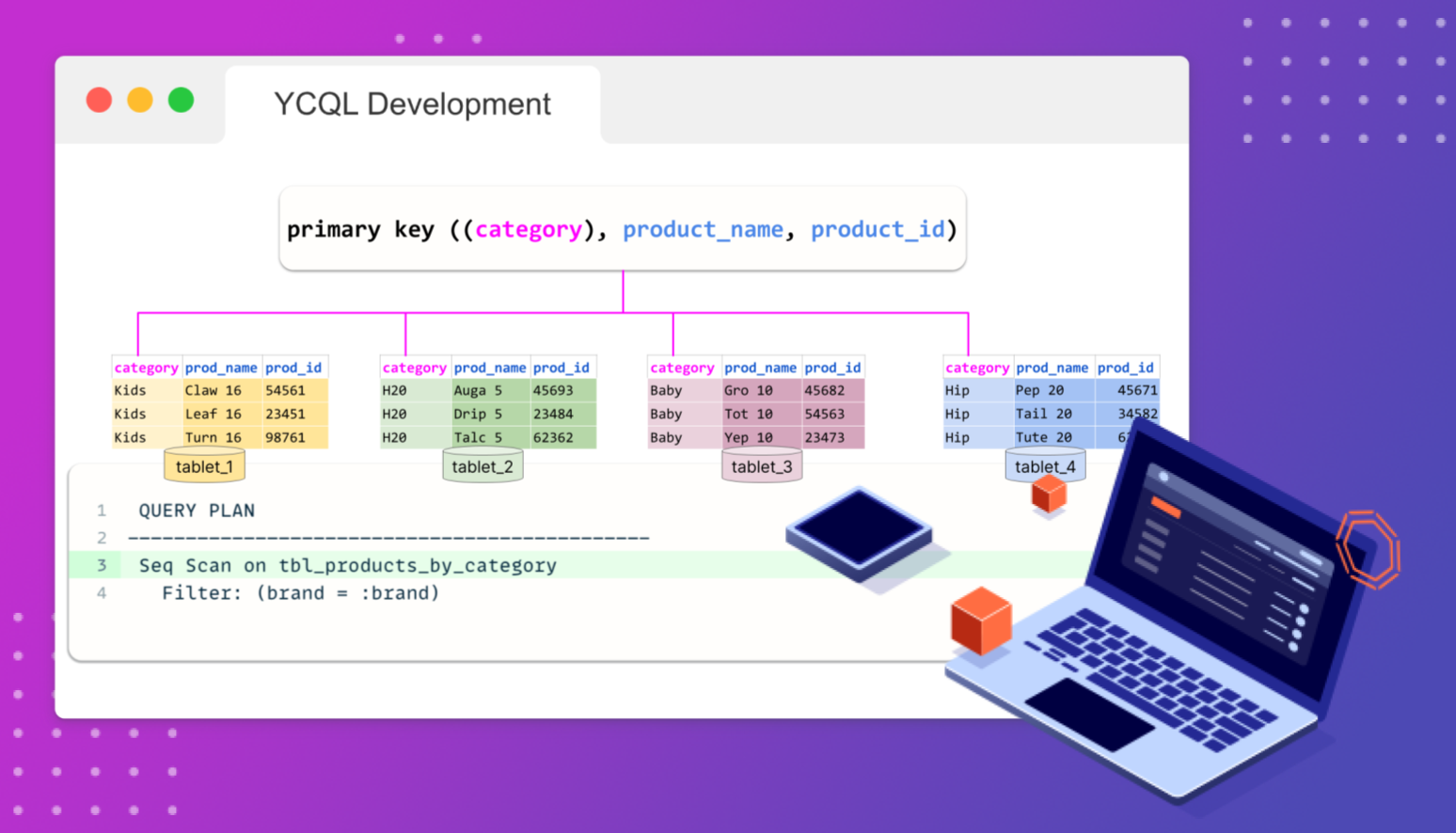
The goal of this course is to demystify key concepts like partition keys, clustering keys, and tablets. Students explore how the DDL of a table affects not only the distribution of data, but also the internals of data stored on disk.
In addition, this course offers a practical methodology for modeling semi-relational data, a methodology known as query-driven data modeling. For traditional RDBMS developers, learning this methodology can be a significant benefit when transitioning from a monolithic database to YCQL and YugabyteDB. It helps you identify data access patterns for an application and outlines how to improve query performance by analyzing query plans and creating secondary indexes.
Additional course topics help you understand the nuances of YCQL such as time-to-live, upserts, collections, JSONB, and secondary indexes. The course includes the following modules and topics:
Language Fundamentals
- DDL: Create table
- DDL: Data types
- DML: Select
- DML: Insert, update, delete, and more
- DML: Built-in functions
Query-Driven Data Model
- Logical data model
- Data access patterns
- Physical data model
- Optimization and tuning: Query plans
- Optimization and tuning: Secondary indexes
Working with JSON
- JSONB: DML and secondary indexes
Hands-on Labs
- [LAB]: YCQL Development with Gitpod
Audience Prerequisites
Students should already be familiar with YugabyteDB concepts, terminology, and features. Additional experience with semi-relational data models, CQL, SQL, YCQL, and Bash shell scripting is helpful.
Checklist
To complete this course, students need the following free applications, services, and accounts:
- Chromium web browser such as Chrome, Opera, or Microsoft Edge
- YugabyteDB Managed sandbox cluster
- YugabyteDB Community Slack account
- Yugabyte University account
- Basic Github account
Certification
Each course module includes a knowledge check. The quizzes help prepare you for the certification exam. After course completion, you can take the exam, free of charge. If you successfully demonstrate your knowledge and pass the exam, you will receive a digital certificate which you can share on your professional network, including LinkedIn. A Yugabyte University certification establishes credentials and validates your expertise.

A frictionless learning experience
This course offers no-cost, hands-on exercises using Gitpod, VS Code Browser, and Jupyter notebooks.
Gitpod provides a fully initialized, perfectly set-up, developer environment for the code repository for this course. In just a few minutes, you can spin up your Gitpod environment, known as a workspace. All you need is a free GitHub account and Chromium based browser. The on-demand, integrated developer environment is 100% browser based. A basic free GitHub account provides you with up to 50 hours of Gitpod workspace utilization per month.
The Gitpod workspace for this course runs a three node YugabyteDB cluster. The Ubuntu docker image in the Gitpod workspace includes VS Code Browser with all the related Jupyter extensions already enabled. The workspace repository consists of several notebook files. When opened, these files function as interactive Juypter notebooks.
Each notebook consists of numerous Markdown and Code cells. Students run individual code cells. The Python kernel for the notebook executes the code in a cell, and when required, outputs results to an output cell. You can modify a notebook, as well as restart the notebook.

The notebooks take advantage of the Ubuntu loopback addresses for the three node YugabyteDB cluster. Code cells run Bash, Python, and YCQL commands. Using command-line tools such as curl, grep, html2text, and jq, you can execute cells that access the web endpoints for both the YB-Master and YB-TServers nodes.
Because the return values from one code cell can be passed as arguments to the next code cell, you can easily perform advanced procedures like flushing a tablet and dumping the related SST files. Revealing in human-readable form how tablet data persists to disk is just one example of how the course exercises help demystify the distributed document store of YugabyteDB.
This course, with its notebooks exercises, is designed to help developers see how YCQL data modeling decisions affect query performance.
Let’s get Started!
Ready to learn more about YugabyteDB and YCQL? Enroll today in YugabyteDB YCQL Development for free!