TPC-C Benchmark: Scaling YugabyteDB to 100,000 Warehouses
February 11, 2022
We’re excited to announce a new milestone in our TPC-C benchmark journey! YugabyteDB can now scale up to 100,000 warehouses with an efficiency of 99.78%. More specifically, this results in 630,000 operations per second on the database cluster, observed over a two-hour period.
For those new to TPC-C, it’s an OLTP system benchmarking tool used to measure performance when handling transactions generated by a real-world OLTP application. It models a business that has a warehouse, multiple districts, and inventory for those warehouses, as well as items and orders for those items.
Of course, the number of warehouses is the key configurable parameter that determines the scale of running the benchmark. Increasing the number of warehouses increases the data set size, the number of concurrent clients, as well as the number of concurrently running transactions.
In this blog post, we reveal the results and key observations of running our TPC-C benchmark to scale YugabyteDB to new heights.
Benchmark observations
Above all, the table below summarizes the key observations of running this benchmark.
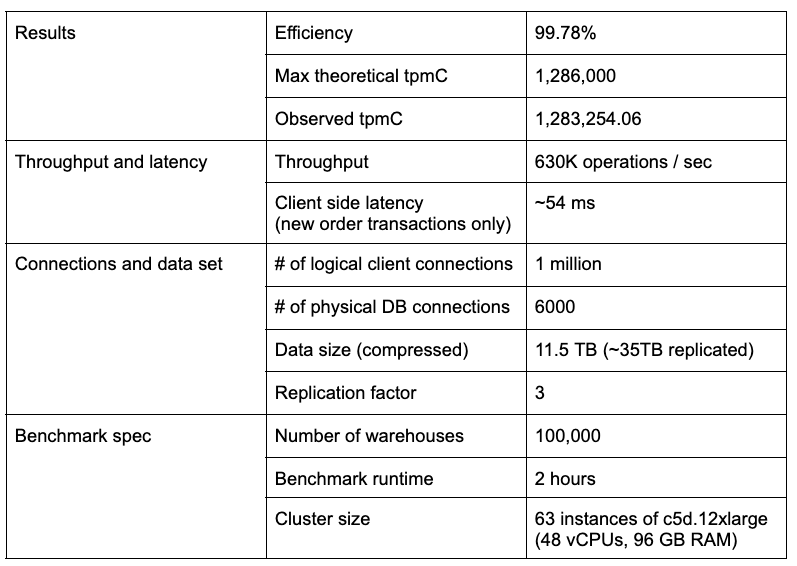
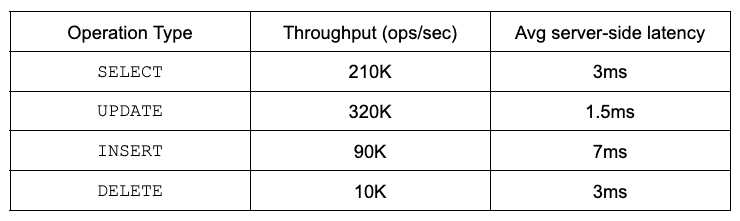
Of course, this benchmark simulates a relational application. It involves multi-row transactions and joins using 1 million concurrent logical client connections. These connections are multiplexed across 6,000 physical connections to the database cluster. See below for a summary of the throughput and latency breakdown.
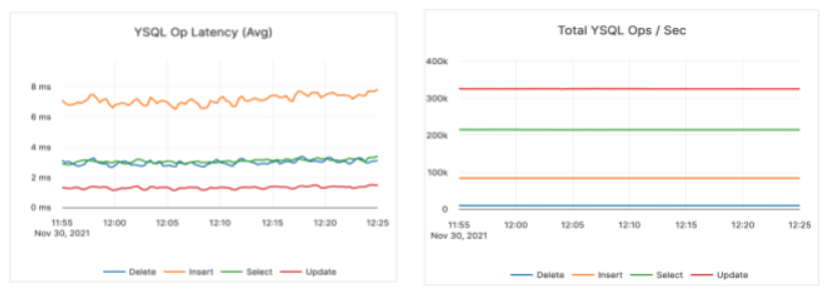
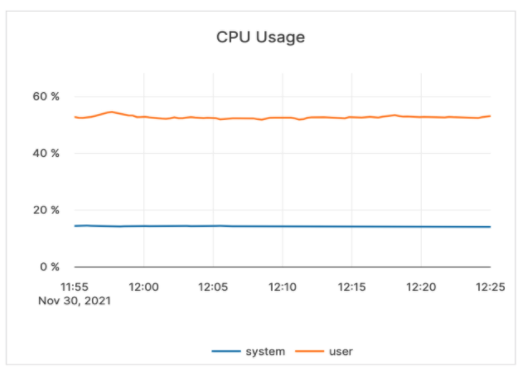
More specifically, the CPU usage throughout the run was around 70%, as shown below.
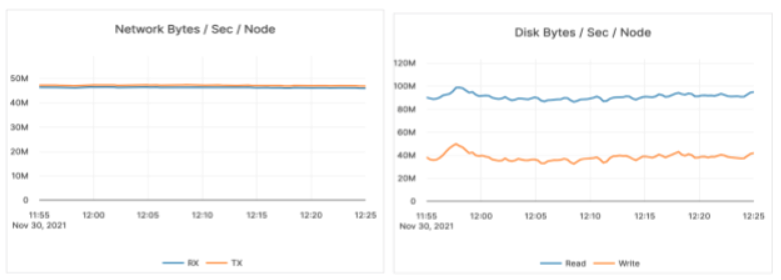
And the graph below shows the disk and network utilization for the duration of the run.
Running the benchmark
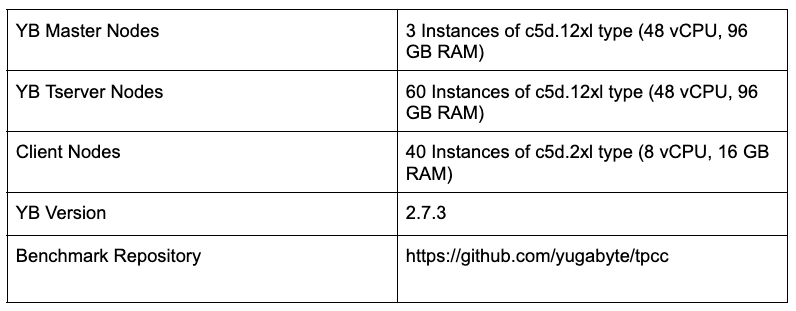
The code for the TPC-C benchmark client is open sourced in the yugabyte/tpcc GitHub repository. The benchmark client ran on 40 AWS instances of type c5d.2xlarge (8 vCPUs, 16 GB RAM) to drive the database cluster. Below are the setup details for the cluster:
- Running on AWS in the US West 2 region, US West 2A availability zone.
- The version of YugabyteDB used was v2.7.3.
- Replication factor of the data in the cluster is 3, allowing 1 instance of failure.
- The cluster comprises 60 instances of type c5d.12xlarge (48 vCPU, 96 GB RAM) running YB-TServers (that serve end user queries), and 3 instances of the same type running YB-Masters (cluster coordination).
- Each of the instances has a local attached 2 x 900 NVMe SSD.
Conclusion
The results of this exercise illustrate YugabyteDB’s horizontal scalability. This distributed SQL database can accommodate a large number of concurrent transactions, high connection counts, and large data sets while delivering ACID transactional semantics. Stay tuned for the next set of benchmark results!
If you haven’t already, check out our Docs site to learn more about YugabyteDB. Any questions? Ask them in the YugabyteDB community Slack channel.


