Unlock Azure Storage Options With YugabyteDB CDC
August 4, 2022
This blog explores how to transfer and process data from YugabyteDB to Azure Blob Storage or Azure Data Lake Storage using Azure EventHub through YBDB’s Change Data Capture (CDC) feature.
The Main Components
YugabyteDB Change Data Capture: This is a pull-based approach to CDC introduced in YugabyteDB 2.13 that reports changes from the YBDB’s write-ahead-log (WAL). Check out the detailed CDC architecture in YugabyteDB’s document section.
Azure EventHub: This is a data streaming platform and event ingestion service that can process millions of events per second. Data sent to an event hub can be transformed and stored using any real-time analytics provider, or via batching/storage adapters using stream analytics jobs, custom Azure Functions, or other Azure-supported services.
Azure Data Lake Storage (ADLS): ADSL can store massive amounts of data without hindrance in a file-based structure. It is an ideal storage service for analytical or big data workloads as it is highly optimized.
Azure Blob Storage: This is an Azure service specifically used to store large amounts of unstructured object data, such as text or binary data. You can use Blob storage to exhibit data to different audiences or store application data privately.
Kafka Mirror Maker: This feature, included in Kafka, allows you to maintain a replica of your Kafka cluster in a separate data center. To achieve this, it uses existing producer and consumer APIs.
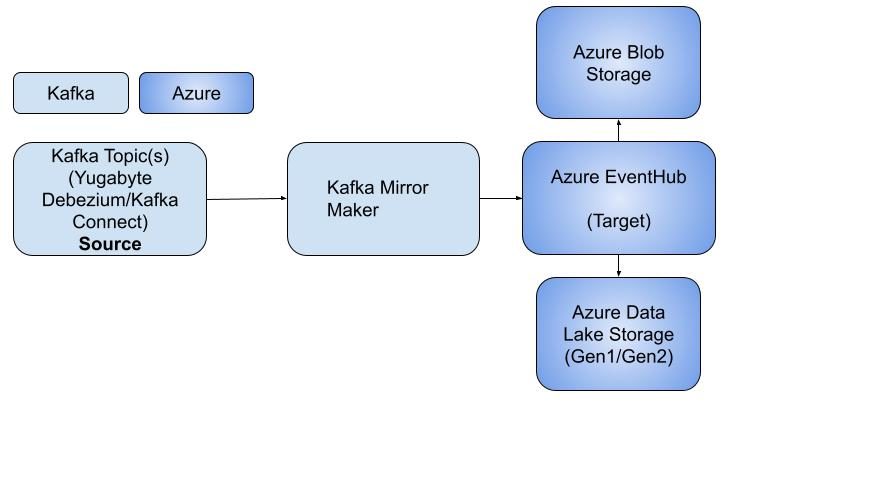
Architecture Diagram

The streamed change data coming from the YugabyteDB Debezium/Kafka connect is mirrored through Kafka Mirrormaker. It is then stored as Avro/JSON/CSV in Azure Blob Storage or Azure Data Lake Storage Gen1 and supports the Parquet file format with Azure Data Lake Storage Gen2. This process is shown in the detailed flow diagram below.
| Tool or Service | Purpose |
|---|---|
| Debezium YugabyteDB Kafka connect | Used to stream the changed datasets requested from YugabyteDB YSQL Tables |
| Kafka Mirror Maker | Enables “mirroring” of a stream from existing YugabyteDB CDC’s Kafka engine as a source and sends all (or selected) topics to Azure EventHub |
| Azure EventHub | A fully managed, real-time data ingestion service from Azure. This streams messages from Kafka to different targets and processes data during streaming through Azure Stream Analytics Jobs. |
| Azure Data Lake Storage (Gen1/Gen2) | Multi modal storage supporting large volume data for complex event processing and big data and analytics for the enterprise. It helps store different data formats such as Avro, Parquet, JSON, and CSV. |
| Azure Blob Storage | A large-scale storage which allows enterprises to store data in unstructured and semi structured data (e.g., JSON, Avro, Logs, etc..) |
Configuring the Azure EventHub Sink
Prerequisites: You must create an Azure EventHub namespace using Standard Pricing Tier as it needs Kafka Protocol communication. Then create an ADLS Storage Account and an Azure Blob Storage account.
Step 1: YBDB CDC should be configured on your database as per this document and should run as per the above architecture diagram, along with its dependent components. You should see a Kafka topic name and group name related to the table name (e.g., testbalas I used here). It will appear in the streaming logs either through CLI or via Kafka UI (e.g., if you used Redpanda or another Kafka UI tool)
Step 2: The Kafka MirrorMaker service requires one or more consumer configuration files, a producer configuration file, and a whitelist or a blacklist of topics.
Consumer/Source: This is the part of MirrorMaker that reads the messages from the source Kafka cluster, intending to replicate the data to the target.
Sample configuration (Consumer/Source) file (e.g., source-kafka-cluster.config)
Bootstrap.servers – YugabyteDB’s CDC Kafka Container or your local Kafka Server
Client.id – Client ID is the Kafka consumer ID
Group.id – Group ID is useful for running multiple Kafka instances sharing the same group ID
Exclude.internal.topics – ensures MirrorMaker does not copy any of Kafka’s internal topics
Example:
bootstrap.servers=172.17.0.3:9092
client.id=mirror_maker_consumer
group.id=mirror-maker-group
exclude.internal.topics=true
Producer/Target: This is the part of MirrorMaker that uses the data read by the consumer and replicates it to the target cluster.
Sample configuration (Producer/Target) file (e.g., target-kafka-cluster.config)
# Event Hubs Kafka endpoint
bootstrap.servers=balaeventhub.servicebus.windows.net:9093 (Please refer to this link on how to get Azure Eventhub FQDN/Connection String)
client.id=mirror_maker_producer ((Client ID is the Kafka Producer ID)
# Event Hubs require secure communication
security.protocol=SASL_SSL (All broker/client communication use SASL_SSL security protocol ensures that the communication is encrypted and authenticated using SASL/PLAIN)
sasl.mechanism=PLAIN
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username=“$ConnectionString”
password=“Endpoint=sb://balaeventhub.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=xxxxxxxxx”;
# to avoid Azure load balancer (3 minutes timeout) closing idle connections
connections.max.idle.ms=180000
metadata.max.age.ms=180000
Step 3: Execute the Kafka MirrorMaker command below using the existing Kafka cluster (e.g., using bash command in YugabyteDB CDC’s Kafka docker container) with the above source/target configuration file (highlighted in yellow below).
$ sudo docker exec -it kafka bash
[kafka@850ed0bf9a18]$ ./bin/kafka-mirror-maker.sh –consumer.config source-kafka-cluster.config –num.streams 1 –producer.config target-kafka-cluster.config –whitelist=“dbserver1.public.testbalas”
- num.streams – Specifies the number of consumer stream threads to create.
- whitelist – An optional parameter where you can specify the topics to include using a comma-separated list
Note: Refer to the MirrorMaker detailed configuration and best practices per your target Kafka/Azure EventHub requirement.
Step 4: Verify that the docker containers required by the YugabyteDB CDC service are up and running. Here we use the Zookeeper and Kafka container, along with the Kafka Connect container (the debezium-connector):
- debezium/kafka:1.7
- debezium/zookeeper:1.7
- quay.io/yugabyte/debezium-connector:latest
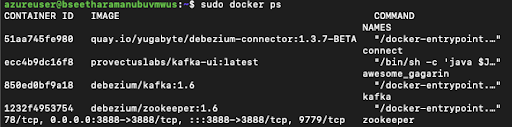
Note: The MirrorMaker service leverages existing debezium/kafka:1.6 containers to replicate the data from Kafka to Azure EventHub.
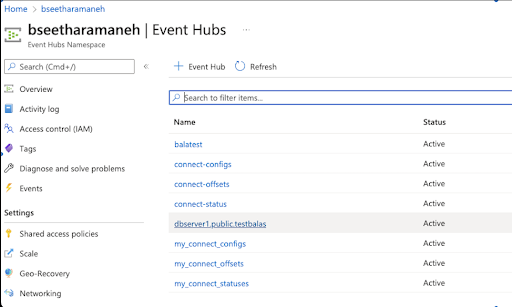
Step 5: Azure Eventhub shows the Kafka topic we mirrored through MirrorMaker below.
Example: dbserver1.public.testbalas is the topic name here.
Step 6: Ingest the data into Azure Blob Storage in Avro format or into Azure Data Lake Storage with Parquet or Avro Format.
Azure Blob Storage:
Capture the events coming from the YugabyteDB Kafka engine and persist them in the Azure Storage Account (i.e., Azure Blob Storage).
Note: For demo purposes, here we use a short time window and size window, but it can be adjusted to meet your requirements.
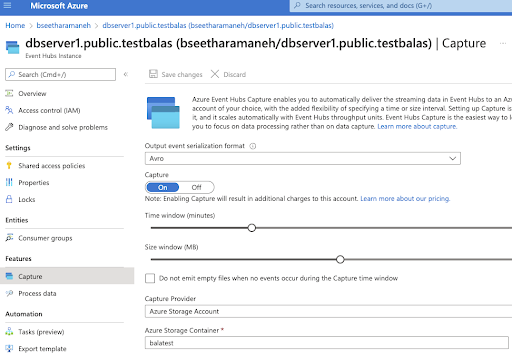
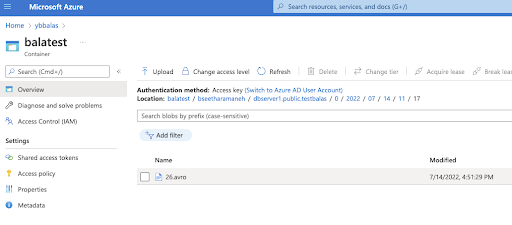
The data is converted into an Avro format from CDC Output and stored directly in the Storage container below.
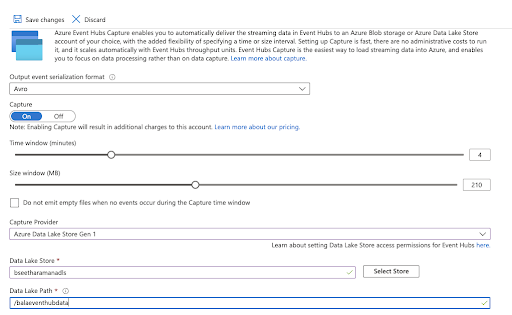
Azure Data Lake Storage (Gen1): Using Azure Data Lake Store Gen1 Provider in Eventhub helps to capture the streamed data into ADLS directly in AVRO format.
Note: It requires the data lake store account name and folder path, as shown in the diagram below.
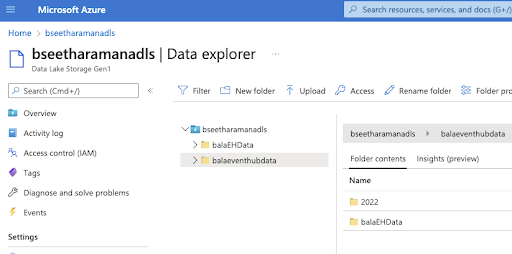
After configuring Capture Provider, the data will be stored continuously in the ADLS folder, as shown below.
Conclusion
Using the YugabyteDB CDC connector and an existing Kafka cluster, Azure EventHub can continuously receive the changed dataset from YugabyteDB through Kafka’s MirrorMaker. It can then process and store this in Azure Storage (either Azure Blob Storage or Azure Data Lake Storage Gen1/Gen2).
During this process, data coming in JSON format can be converted into CSV, Parquet, or JSON, and EventHub filters and processes this using Azure Stream Analytics.
Was this blog focused on unlocking Azure storage options with YugabyteDB CDC useful? Interested in finding out more? Join our active Slack community of users, experts, and enthusiasts for live and interactive YugabyteDB and Distributed SQL discussions.


