Beyond RAG: Using YugabyteDB as the Foundation for Reliable AI Decisions
May 26, 2026
Every loan decision in India must be explainable to the RBI regulator (who may audit it years later), the customer (who deserves a clear reason in their own language), and the bank’s credit committee (who must justify the final approval or rejection).
Manual underwriting is too slow for the scale and volume that Indian lenders handle. At the same time, a standalone AI agent is not sufficient because it can generate recommendations without a reliable system of record, a clear reasoning trail, or an audit-ready history.
This is where YugabyteDB comes in. By combining transactional consistency, distributed scalability, PostgreSQL compatibility, JSON support, and pgvector-based AI memory, YugabyteDB serves as the trusted foundation for storing customer data, policy checks, AI recommendations, explanations, human reviews, and final decisions.
A practical solution is to bring vector search, semantic caching, and operational business data together within a single YugabyteDB-backed data layer. This reduces token usage, improves response times, and ensures that AI-assisted lending decisions are grounded in trusted, auditable enterprise data.
In this blog, we walk through a fast and explainable copilot, but the real story is the foundation underneath it:
- RAG (Retrieval Augmented Generation)
- CAG (Cache Augmented Generation)
- vLLM (a high-throughput LLM serving framework)
RAG pulls relevant past decisions, CAG keeps RBI’s lending policy text loaded efficiently across requests, and vLLM runs the model. These moving pieces keep evolving as rules and situations change. YugabyteDB acts as the system of record, and everything else is replaceable.
The Problem We Solve
Customer records, policies, embeddings, and audit logs often end up scattered across Postgres, a vector database, object storage, and a separate audit system. Keeping them in sync becomes a problem in itself.
YugabyteDB consolidates all this into a single database. One source of truth for every record that an auditor, a customer, or a credit committee could ask about. That’s the core of the architecture, and everything else plugs into it.
Case Study
A home loan or gold loan underwriter at an Indian bank or housing finance company typically processes 30 to 50 cases per week. Each decision requires them to:
- Compare the current case with similar past decisions
- Validate it against evolving banking rules, credit policy, and credit bureau recommendations.
These rules include:
- Reserve Bank of India (RBI) Master Directions
- Fair Practices Code (FPC)
- Priority Sector Lending (PSL) classifications
- Case-specific regulations like the Foreign Exchange Management Act (FEMA) for NRI applicants, and the Pradhan Mantri Awas Yojana: Credit Linked Subsidy Scheme (PMAY-CLSS)
- Gold Loan Scheme as per the daily gold rate.
We decided to build an underwriting co-pilot or assistant that retrieves similar cases, applies policy, and generates a first-pass analysis.
The Reproducibility Problem
The challenge is not just getting AI to give an answer. The real challenge is ensuring that the same decision can be explained, verified, and reproduced months later, with every input, policy reference, and recommendation traceable.
Indian lending regulations are very specific, especially for collateral-based loans. Key Fact Statements, mandatory since 2024, must be supported by the policy and data used at the time of decision. Similarly, loan rejections must clearly mention the threshold breached and the policy section that defines it.
An example rejection would look like this:
Loan rejected: Fixed Obligations to Income Ratio of 68% exceeds the 60% threshold under Policy v3.2, Section 4.1. Referenced Home Loan precedents: HL-2023-11872, HL-2022-98431.
If a system cannot reproduce a decision exactly as it was made, it is not just a technical gap. It becomes a regulatory risk for the bank or financial institution.
To address this, the YugabyteDB assistant stores the complete loan case context, applicable policy versions, retrieved similar cases, AI recommendation, supporting evidence, prompt and model version, and human reviewer feedback. Policies such as the Reserve Bank of India Master Directions, the Fair Practices Code, Priority Sector Lending classifications, the Foreign Exchange Management Act rules for NRI applicants, the Pradhan Mantri Awas Yojana – Credit Linked Subsidy Scheme guidelines, and the Gold Loan rules linked to daily gold rates are versioned and traceable.
This ensures that the same analysis can be reproduced later using the same case data, policy version, retrieved evidence, and reviewer decision trail.
Why YugabyteDB?
YugabyteDB is a distributed database that delivers strong consistency with an ACID-compliant layer that holds the customer master, policy corpus, vector embeddings, and audit log. This keeps everything consistent and in sync. Its strong consistency and high resiliency ensure regulatory correctness, with built-in scalability, fault tolerance, and auditability, reliable, traceable, and compliant decision-making.
Key Benefits:
- Single ACID transaction across customer, policy, vector search, and audit
- Strong consistency for regulatory correctness
- Unified relational and vector storage with HNSW (Hierarchical Navigable Small World) Index
- Horizontal scalability and fault tolerance
- Auditability built in (e.g. PgAudit, Custom Audit table to trace the underwriting workflows, maker/checker logs)
YugabyteDB Assistant Architecture
Figure 1 below illustrates the underwriter copilot process flow, showing what happens when an underwriter clicks Analyze in the UI: YugabyteDB retrieves the relevant precedents and policy, vLLM generates the analysis, and the decision is logged before the response is returned to the screen.

The system is composed of three components, as shown in Figure 2 below:
- a UI layer
- a data layer
- an inference layer
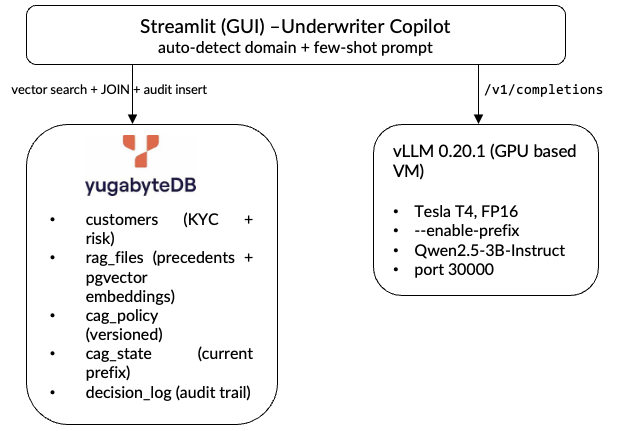
Streamlit (GUI) serves as the user interface for the underwriting agent or loan officer issuing the loan to a customer.
It automatically detects the loan domain (home or gold) from the underwriter’s question, constructs the few-shot prompt, and orchestrates calls to both backend layers. YugabyteDB forms the data layer. Its tables collectively hold every regulated asset the copilot relies on.
The table below shows YugabyteDB’s table name and its purpose.
| Table Name | Purpose |
|---|---|
| customers | KYC and risk grade master data |
| rag_files | past underwriting decisions with pgvector embeddings for similarity search |
| cag_policy | versioned policy corpus (RBI Master Directions, internal credit rules) |
| cag_state | tracks the currently warm prefix in the LLM cache |
| decision_log | append-only audit trail, one row per decision |
vLLM 0.20.1 is the inference layer, running Qwen/Qwen2.5-3B-Instruct at FP16 on a Tesla T4 GPU. The –enable-prefix-caching flag enables CAG behavior: policy tokens are processed once and reused across requests. The server exposes an OpenAI-compatible API on port 30000.
Data flow: When the underwriter clicks Analyze, Streamlit runs a vector search joined with the customer master in YugabyteDB, sends the policy prefix plus retrieved precedents to vLLM, captures the response, and writes one row to decision_log. All this in a single user-visible action. The model can be swapped (SGLang, Anthropic API, Ollama for local development), but the data layer does not change.
RAG + CAG + vLLM: How it Comes Together
RAG (Retrieval-Augmented Generation) finds similar past cases using vector search on precedent files stored in YugabyteDB. CAG (Cache-Augmented Generation) uses a large, mostly static policy context, typically 30,000 to 40,000 tokens of RBI Master Directions, internal credit policy, and product-specific rules, which is also stored in YugabyteDB.
Why Prefix Caching Matters
Without optimization, every request recomputes the full 30K–40K token policy from scratch. On a Tesla T4 GPU, that means:
- 2–3 seconds of latency per call
- Wasted GPU compute on tokens that never change
- Higher cost per query and throughput drops as the policy grows
vLLM (an open-source LLM inference engine from UC Berkeley) fixes this with automatic prefix caching:
- Policy prefix processed once, cached in GPU memory
- Subsequent requests reuse the cache, and only new content is computed
- Old prefixes are evicted automatically when memory fills
- We can just pass –enable-prefix-caching at the launch flag for prefix caching.
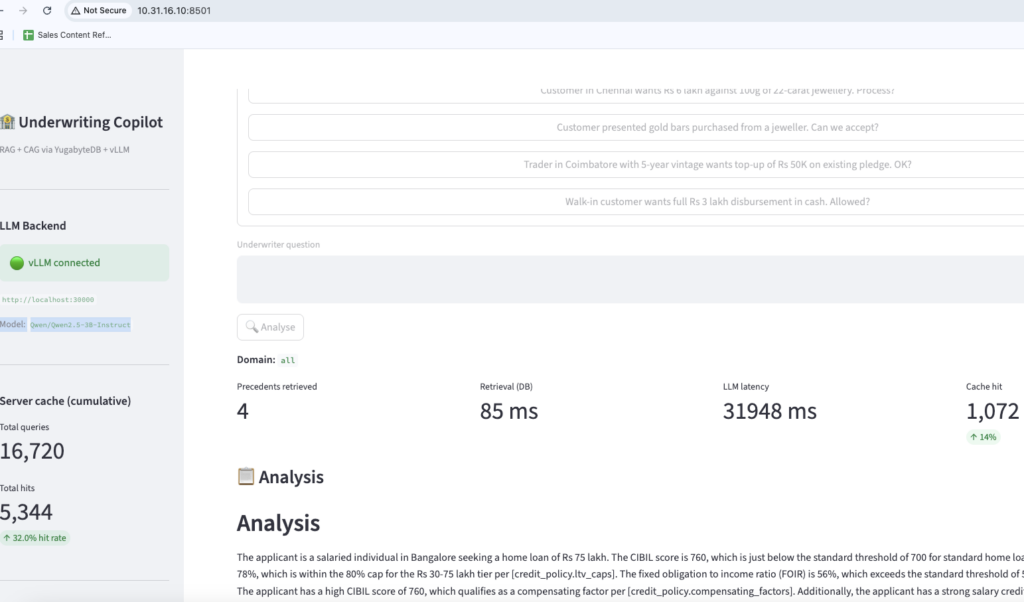
On our T4 deployment running Qwen2.5-3B-Instruct, we measured a 97% prefix cache hit rate and a 62% latency drop between cold and warm calls, sub-second responses on a consumer-grade GPU.
RAG brings relevance, and CAG brings correctness. vLLM is a GPU (Graphical Processing Unit) inference server built around PagedAttention, which manages the KV(Key Value) cache in fixed-size memory pages (much like virtual memory in an operating system) to eliminate fragmentation and enable cache reuse across requests, and makes both RAG and CAG usable at scale
LLM Serving Engine Choices
Several engines support the prefix-caching pattern this architecture depends on. The choice depends on hardware, scale, and operational complexity.
| Engine | Details |
|---|---|
| vLLM | Mature, broad GPU support. Slightly less aggressive prefix optimization than SGLang |
| SGLang | SGLangBest prefix optimization, but dropped Turing (T4) support in 0.4+. |
| TensorRT-LLM | TensorRT-LLMHighest throughput, but complex setup and NVIDIA vendor lock-in |
| HF TGI | HF TGIStable, but prefix caching is less mature. |
| Anthropic API (managed) | Anthropic APIZero ops, managed. |
Implementation Steps
Refer to the Github Repo which has step-by-step instructions to implement the underwriting copilot using vLLM with RAG/CAG and integrate it with YugabyteDB.
Sample Output:
Limitations and Next Steps
This is a reference architecture, not a production-ready deployment. It showcases how RAG, CAG, and vLLM integrate with YugabyteDB as the single source of truth, while also validating real-world prefix-caching performance on a Tesla T4 GPU.
The design is intentionally modular and intended to be extended, optimized, and tuned to your specific workload and scale requirements.
Limitations of This Build
- Synthetic data only. The 80 customers and 100 precedents are deterministic generators, not real loan files. Production retrieval quality will need real precedents and may benefit from a re-embedding step.
- Single GPU, single tenant. Concurrency, multi-region replication, and load balancing across multiple vLLM instances are out of scope here.
- Native-language generation is not implemented. The Fair Practices Code requires rejection letters in the borrower’s preferred language; this translation layer is left as future work.
- LTV monitoring is not implemented. For gold loans, especially, daily LTV recomputation against IBJA rates would be required in production.
- The 3B model is fit for demos. A production deployment would likely use Qwen2.5-7B or Mistral-7B on a larger GPU (A10 or A100) to achieve a higher answer quality.
Conclusion
With YugabyteDB at the core, customer records, vector embeddings, policies, and audit logs live together in a single distributed data layer. There is one source of truth and one consistent answer for the regulator.
Retrieval is a single SQL query, the audit trail is a single transaction, and reconstruction is a single SELECT, even months or years later. Models, inference engines, and UI layers will change, but YugabyteDB remains the durable system of record that powers AI, operational data, vectors, and compliance together.
Want to know more about how YugabyteDB’s distributed design enhances scalability and performance for AI workloads?
Download ‘A Practical Guide to Building GenAI Apps on a PostgreSQL-Compatible Database’ to discover basic AI concepts, architectural considerations, and access to hands-on tutorials that demonstrate how to build your first GenAI application on various platforms.


