Why We Built YugabyteDB by Reusing the PostgreSQL Query Layer
April 24, 2020
Reusing PostgreSQL’s native query layer instead of writing a new Postgresql-compatible query layer ground up has been one of the best design decisions we have made in YugabyteDB. As outlined in the challenges we faced building a distributed SQL database, we have battle scars to prove this insight – we started writing a PostgreSQL-compatible query layer from scratch before realizing that we simply cannot build the world’s best cloud native RDBMS in a timely manner if we persist down this path. The following is a snippet from the blog post referenced above.
The YugabyteDB Query Layer has been designed with extensibility in mind. Having already built two APIs (YCQL and YEDIS) into this query layer framework by rewriting the API servers in C++, a rewrite of the PostgreSQL API seemed easier and natural at first.
We were about 5 months down this path before we realized this was not an ideal path. The other APIs were much simpler compared to the mature, full-fledged database that PostgreSQL was. We then reset the whole effort, went back to the drawing board and started anew with the approach of re-using PostgreSQL’s query layer code. While this was painful in the beginning, it has been a much better strategy in retrospect.
In this post, we will look at some of the benefits YugabyteDB enjoys based on its reuse of the PostgreSQL code.
Transforming PostgreSQL into Distributed SQL
Yugabyte SQL (YSQL) API, which uses a fork of PostgreSQL’s query layer as its starting point, runs on top of YugabyteDB’s distributed storage layer called DocDB. This is shown in the figure below. Monolithic PostgreSQL on the left, distributed YugabyteDB on the right.
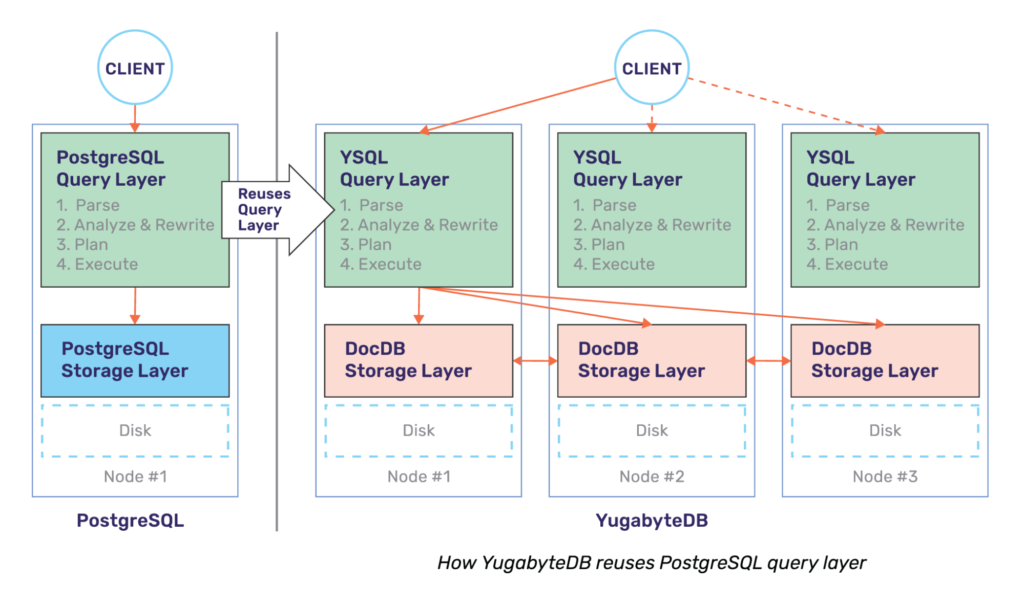
As described in “What is Distributed SQL?”, this design ensures that the entire database cluster (irrespective of the number of nodes in it) looks to applications as a single logical SQL database. Not only do applications continue to benefit from the flexibility of the PostgreSQL language and the easy-to-understand ACID transactions semantics, they also gain three fundamental benefits that have eluded single-node RDBMSs forever. The first benefit is extreme resilience against failures with native failover/repair, second is ability to scale writes on-demand through auto sharding/rebalancing, and finally lower user latency through geographic data distribution.
Supporting advanced RDBMS features
The single biggest advantage of this reuse approach is the fact that YugabyteDB gets to leverage advanced RDBMS features that are well designed, implemented, and documented by PostgreSQL. While the work to get these features to work with high performance on top of a cluster of YugabyteDB nodes is significant, the query layer does get radically simplified with such an approach.
YugabyteDB supports many more RDBMS features that other distributed SQL databases can only dream of. The following is a list of such features.
| PostgreSQL Feature | YugabyteDB v2.2 |
|---|---|
| Most operators, expressions, and built-in functions | Yes |
| Expression-based indexes | Yes |
| Partial indexes | Yes |
| Table functions | Yes |
| Stored procedures (SQL, pl-pgsql) | Yes |
| Triggers | Yes |
| User-defined types | Yes |
| Temporary tables | Yes |
| Row level security | Yes |
| Column level privileges | Yes |
| PostgreSQL extensions | Yes (partial)* |
| Foreign data wrappers | Roadmap |
* Since YugabyteDB only reuses the query layer of PostgreSQL, it only supports extensions that use the query layer. Extensions that access the storage layer would not work.
Every feature listed in the table above is quite complex. Writing such features from scratch would not have been easy. Additionally, ensuring that developers can quickly adopt and derive value from these features requires an implementation that adheres closely to the PostgreSQL specification. Reusing the PostgreSQL codebase has made this possible in YugabyteDB.
Keeping quality high
In addition to building these advanced RDBMS features, it is also important to ensure the features undergo significant testing both by incorporating a robust regression test suite (that also has adequate code coverage) and also by hardening their stability through usage across a wide range of scenarios. YugabyteDB reuses even the PostgreSQL regression tests to achieve the former goal.
The table below shows some rough statistics of the unit tests that Yugabyte SQL has incorporated from the PostgreSQL codebase. We are committed to getting as close as possible to 100% coverage through additional engineering investments in this area.
| Regression Tests | PostgreSQL | YugabyteDB (current coverage) |
|---|---|---|
| Files | 192 | 114 (59%) |
| Lines | 68,803 | 33,459 (49%) |
| SQL Statements | 29,292 | 14,943 (51%) |
Note that the above tests include a multitude of SQL features such as joins, foreign keys, triggers, data types and functions/operators, plpgsql, row-level security, and many more. There are additional tests on top of these that test SQL scenarios pertaining to the distributed SQL nature of YugabyteDB. Additionally, there are regression tests in the YugabyteDB codebase that test the various other components of the database beyond YSQL.
Integrating with ecosystem tools and frameworks
Another advantage of the reuse of PostgreSQL query layer is the number of ecosystem tools and frameworks YugabyteDB can integrate with out-of-the-box. A few notable examples are:
Summary
Franck Pachot, an independent respected voice in the database community, captured the essence of YugabyteDB’s reuse of PostgreSQL query layer in his recent blog post:
The big advantage of YugabyteDB is that the YSQL API is more than just compatibility with PostgreSQL like what CockroachDB does. Yugabyte re-uses the PostgreSQL upper layer. Then an application built for a PostgreSQL database with the best one-node performance can scale-out without changing the application when moving to YugabyteDB. And vice-versa. This looks similar to what Amazon is doing with AWS Aurora except that Aurora runs only on AWS but YugabyteDB is open-source and can run anywhere.
Delivering an Amazon Aurora-like application developer and operations engineering experience on multi-cloud, hybrid cloud, and Kubernetes environments while remaining fully compatible with PostgreSQL is certainly important to us. This post shows that we are well on our way there when it comes to PostgreSQL compatibility. We continue to increase coverage of the PostgreSQL features with every major/minor release, but our journey is not yet complete. This means that single-node PostgreSQL applications may require code changes when migrating over to YugabyteDB. We are always available to assist our users on schema modeling, query design, and application changes–as well as anything else they may need–through our Community Slack, GitHub, as well as Community Forum. We hope that you will partner with us in our mission of building the world’s most powerful, 100% open source, cloud native RDBMS.


