Explore YugabyteDB’s Vector Indexing Architecture
June 5, 2025
As vector search becomes foundational to modern AI workloads, from semantic search and recommendations to retrieval-augmented generation (RAG), databases must rethink their architecture to handle high-dimensional vector data at scale.
In this blog, we will explore how YugabyteDB integrates a distributed vector indexing engine powered by USearch to deliver fast, scalable, and resilient vector search natively with a Postgres-compatible SQL interface.
PostgreSQL Compatible, SQL-First Interface, Search-Optimized Internals
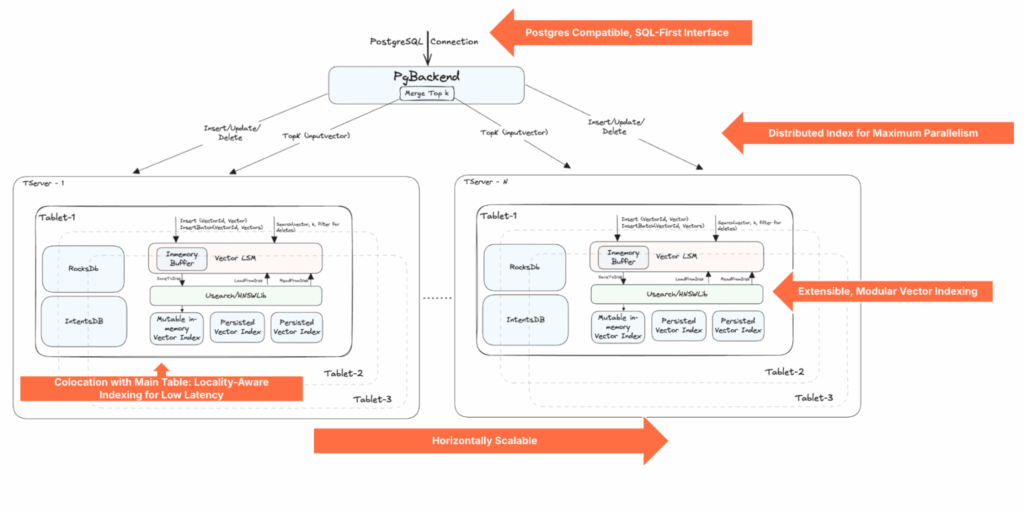
As it is fully PostgreSQL-compatible, YugabyteDB feels immediately familiar. Users can define vector columns, create vector indexes, and query them using standard SQL via the pgvector extension.
CREATE TABLE docs (id BIGSERIAL PRIMARY KEY, embedding VECTOR(1536)); CREATE INDEX ON docs USING hnsw (embedding vector_l2_ops) WITH (m=16, ef_construction=64); SELECT * FROM docs ORDER BY embedding <-> '[0.1, 0.3, ...]' LIMIT 10;
Underneath this familiar interface lies a deeply optimized, distributed vector storage engine, purpose-built for scale-out performance in a globally distributed database.
Vector LSM: Purpose-Built for Approximate Nearest Neighbor
A key innovation in YugabyteDB’s vector support is the decoupled, pluggable indexing layer via the Vector LSM abstraction. This modular architecture separates vector search logic from the rest of the database engine, enabling easy integration with multiple ANN (Approximate Nearest Neighbor) backends.
YugabyteDB’s Vector LSM works like an LSM tree, but is built for vector indexes:
- Ingestion: Vectors are first inserted into an in-memory buffer and indexed using HNSW-based libraries like USearch.
- Persistence: Once full, in-memory indexes are flushed to disk as immutable vector chunks.
- Querying: Searches fan out across all in-memory and on-disk vector indexes. Results are filtered using MVCC rules to ensure consistency and merged to produce the final result.
This tiered architecture is highly parallelizable and aligns well with YugabyteDB’s distributed sharding and replication model.
Each tablet replica runs its own Vector LSM instance. This design enables algorithm-level flexibility per workload and unlocks optimization opportunities specific to each deployment’s needs.
Supported and Future Backends
- USearch — a lightweight, high-performance C++ HNSW engine
- Hnswlib — a widely adopted HNSW implementation with proven robustness
- Future options — FAISS, DiskANN, or custom GPU-backed indexes
Colocation with Main Table: Locality-Aware Indexing for Low Latency
A standout YugabyteDB design choice is its co-partitioned vector index layout. Vector indexes are stored in the same tablets as the corresponding table rows, ensuring tight data locality and operational advantages that monolithic vector databases can’t offer.
Why Colocation Matters
- Fast local joins: Embeddings and their associated metadata are accessed in the same tablet, eliminating the need for expensive cross-shard lookups.
- Efficient filter pushdowns: SQL predicates and vector search can be jointly evaluated, reducing unnecessary computation and network I/O.
- Simplified transactions: Index and table updates live in the same Raft log, ensuring atomic updates and simplifying consistency management.
- Region-aware placement: Indexes can be placed alongside users or inference services, minimizing inter-region latency for geographically distributed AI use cases.
Distributed Index for Maximum Parallelism
YugabyteDB’s underlying architecture enables massive parallelism for vector queries. Every tablet contains a slice of the index and participates in query execution.
Fanout + Local Filtering = Scalable Top-K
- Fanout reads: A vector query fans out to all tablets in parallel.
- Local top-K evaluation: Each tablet computes top-K results locally using its embedded index.
- Global aggregation: Partial results are collected and merged to return the final top-K matches.
This architecture minimizes bottlenecks, maximizes throughput, and distributes compute across the entire cluster—ideal for large-scale vector workloads.
Horizontally Scalable and Self-Balancing by Design
YugabyteDB is designed for horizontal scalability from day one. Vector workloads grow fast, and YugabyteDB keeps up effortlessly—whether you’re scaling across regions or just adding compute.
How It Scales
- Tablet-based sharding: Data (and vector indexes) are automatically partitioned into tablets, the unit of distribution and replication.
- Elastic rebalancing: As new nodes are added, tablets are automatically redistributed to balance load and storage across the cluster.
- Automatic tablet splitting: If a single tablet grows too large—due to more rows, vectors, etc, it is automatically split into smaller tablets and redistributed for continued performance.
This elasticity ensures that performance scales linearly with data size and hardware, with no manual intervention required.
Ultra-Resilient Indexing with MVCC and WAL Recovery
Unlike most standalone vector libraries, YugabyteDB brings enterprise-grade resilience to vector search through its transactional storage engine and distributed consensus protocol.
Resilience Features
- MVCC filtering: All vector writes are timestamped, enabling multi-version, consistent reads—crucial for analytics and long-running queries.
- Bi-directional vector ID mapping: Vector IDs are versioned in RocksDB for stable key lookups, even through updates and deletes.
- Raft-consistent recovery: Vector LSM tracks persisted state. After crashes, WAL-based replay ensures consistency without losing data or search integrity.
Why USearch Powers YugabyteDB’s Vector Indexing
YugabyteDB integrates USearch as a core vector indexing backend due to its low-level efficiency, disk-backed architecture, and native support for predicate-aware search. These features meet the performance and concurrency requirements of a distributed, MVCC-based storage engine
Compact and Fast by Design
USearch is a modern, minimal HNSW implementation that is 10x faster than FAISS in many benchmarks. It’s SIMD-optimized, single-header C++ library enables lightening-fast search, ideal for embedding in the critical read/write path of Vector LSM.
Disk-Backed Indexing
Unlike many in-memory libraries, USearch supports memory-mapped file access, enabling YugabyteDB to persist vector indexes efficiently without loading them entirely into RAM. This is crucial for supporting large-scale deployments with billions of vectors and reducing memory pressure.
Predicate Pushdown for Efficient Filtering
USearch supports in-graph filtering, allowing YugabyteDB to push MVCC-aware predicates (like timestamps or delete filters) directly into the ANN traversal. This dramatically reduces post-processing overhead and improves query latency.
Flexibility with User-Defined Metrics
While YugabyteDB currently focuses on L2 and cosine distances, USearch enables future extensibility by supporting custom distance functions, even compiled ones. This paves the way for domain-specific metrics (e.g., Haversine for GIS or Tanimoto for molecules) in future YugabyteDB workloads.
Conclusion: Build AI-Native Apps at Cloud Scale
By combining:
- Postgres compatible, SQL-first UX
- Distributed, horizontally scalable, ANN indexing
- High-performance HNSW via USearch
- Raft-backed resilience and MVCC consistency
- Modular, pluggable architecture
YugabyteDB is not just adding vector support—it’s redefining what a production-grade vector database can be.
For teams building retrieval-augmented generation (RAG), semantic search, recommendation engines, or any application where scale meets intelligence, YugabyteDB with USearch delivers unmatched performance and flexibility.
Learn more about YugabyteDB’s Vector Indexing Architecture and how to build RAG and Gen-AI-enabled applications using YugabyteDB in this recent blog.


