YugabyteDB 2.15: Accelerate Cloud Native Adoption with YugabyteDB Voyager
July 5, 2022
As organizations continue to embrace the public cloud for their applications, migrating business-critical data to cloud native databases remains one of the biggest barriers to accelerating cloud adoption. Organizations also want the freedom and confidence to move key applications and the underlying data to their choice of public, private or hybrid clouds.

Developed in response to customers who are struggling with migration from single node Postgres and similar environments, YugabyteDB Voyager is available today to remove many of these barriers. YugabyteDB Voyager delivers a powerful migration engine that helps to effortlessly migrate critical data from legacy on-premises or cloud databases to a distributed, multi-cloud data fabric powered by YugabyteDB. The engine also helps organizations optimize moving to a distributed, cloud native environment by managing the entire lifecycle of database migration, from cluster preparation to schema and data migration.
We are excited to reveal YugabyteDB Voyager and release the beta version of this new tool. We are looking forward to continuing to enhance the offering, add new features, and deliver key services around it in partnership with the Yugabyte Customer Success team.
Now, let’s introduce you to more details about YugabyteDB Voyager.
YugabyteDB Voyager overview
YugabyteDB Voyager, our new migration engine, manages the entire lifecycle of a database migration, including cluster preparation for data import, schema-migration and data-migration. These key actions use the yb-voyager CLI.
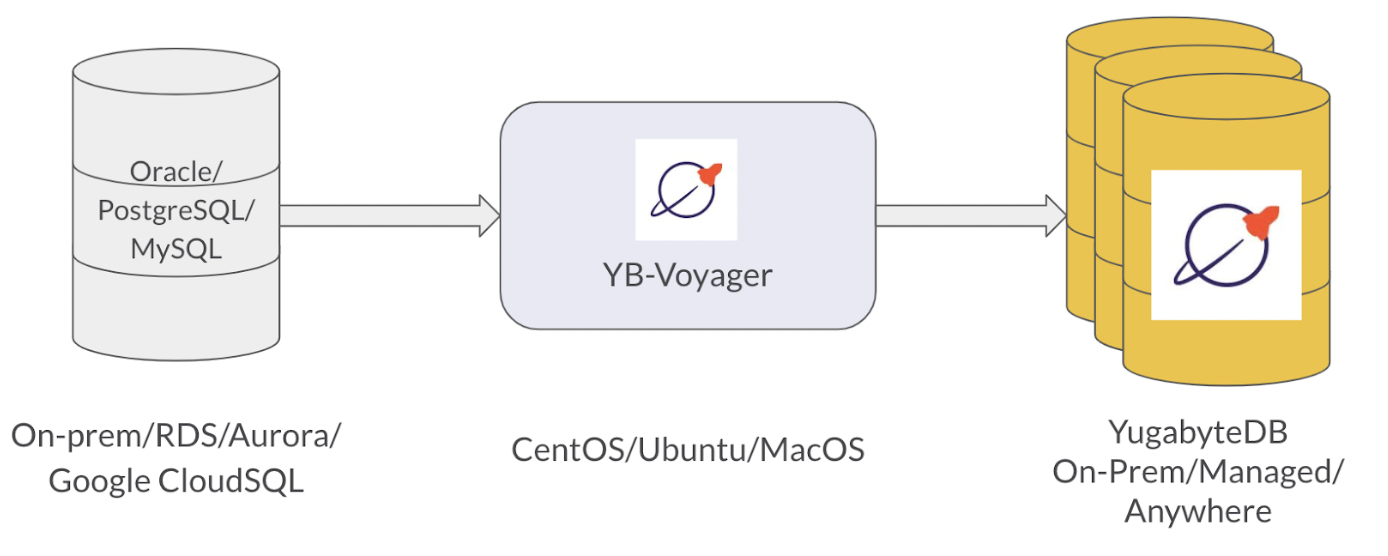
YugabyteDB Voyager is 100% open source. The engine supports widely used databases for migration and does not require changes to the source databases in most cases. All YugabyteDB products (v2.12 and above) exist as a target database, including the free open source database, YugabyteDB Anywhere for self-managed DBaaS, and YugabyteDB Managed for a fully-managed DBaaS.
The initial beta of YugabyteDB Voyager already supports a wide range of legacy on-prem and cloud databases. Out of the gate, you can simplify your migration from legacy databases including Oracle, Postgres, MySQL, and MariaDB as well as from common public cloud databases including AWS RDS, Aurora, Google CloudSQL, and Azure DB for PG.
Voyager provides a unified CLI experience across all different source databases. It is auto-tunable based on workloads by analyzing the target cluster capacity.
By default Voyager runs parallel jobs to import data; the parallelism is configurable and can be specified across tables and within tables data. Users can monitor the import status using progress bars and expected time to finish for data export and import.
Voyager also supports direct data import from data files. Currently, offline migration is supported through the beta release, but live migration support is under development. For any questions, contact Yugabyte Support.
YugabyteDB Voyager migration workflow
A typical migration workflow using yb-voyager consists of the following steps:

- After Installing yb-voyager, prepare the source and the target database.
- Convert the source database schema to PostgreSQL format using the yb-voyager export schema command. Then generate a Schema Analysis Report using the yb-voyager analyze-schema command. The report suggests changes to the PostgreSQL schema to make it appropriate for YugabyteDB.
- Manually change the exported schema as suggested in the Schema Analysis Report. You can rerun the analysis if needed. Export the source database in the local files on the yb-voyager machine, using the yb-voyager export data command.
- Import the schema to the target YugabyteDB database using the yb-voyager import schema command. And then Import the data to the target YugabyteDB database using the yb-voyager import data command.
YugabyteDB Voyager import performance and best practices
When using YugabyteDB Voyager, please note the following best practices and tips to help improve your overall experience and performance.
Importing into a schema with secondary indexes
When importing data into a table with secondary indexes, the import step will ingest the table data and required secondary index data concurrently. This may result in a longer import time compared to a table without secondary indexes.
It may be preferable to remove the secondary indexes from the schema, perform the import, and then re-create the indexes separately. The Index backfill operation should be performed, which is faster than the online index maintenance operation. This provides increased visibility into its progress and ability to retry each step independently.
Importing into a schema with constraint checks/triggers
Similarly, for tables with foreign key constraints or triggers, it may result in a longer import time compared to a table without foreign key constraints or triggers.
For maximum throughput, yb-voyager disables all the constraints checks during the data import phase. Please note this is only disabled in the sessions which yb-voyager uses internally to migrate data. Similar to disabling constraints checks, triggers are also disabled during the import phase.
Import performance
There are other factors which can impact the speed of data ingestion. In order to increase the ingestion performance consider following factors and tune them as per your need.
Data load parallelism: In order to increase ingestion throughput, the data migration engine executes ‘N’ parallel batch ingestion jobs at any given time where ‘N’ is equal to the number of nodes in the YugabyteDB cluster. Normally this is a good default to assume. However, the target YugabyteDB cluster can be running on large instances with many vCPUs. In such cases, you can increase the parallelism.
Batch size – The default value of –batch-size is 100000, choosing a very small value might result in slow performance because time spent on actual data import might be comparable/less to time spent on other tasks like bookkeeping, setting up the client connection etc.
Disk write contention – YugabyteDB servers can pass one or multiple disk volumes to keep tablet data. If all the tablets are writing to a single disk then write contention can slow down the ingestion speed. In such cases configuring the t-servers with multiple disks helps a lot in reducing the disk write contention thereby increasing the throughput. Also disks with higher IOPS and better throughput helps the write performance.
Number of tablets: For larger tables and indexes that are hash-sharded, specify the desired number of initial tablets as a part of the DDL statement of the table. This helps distribute the table data across multiple nodes.
For larger tables and indexes that are range-sharded and the value ranges of the primary key columns are known ahead of time, pre-split them at the time of creation. This is especially beneficial for range sharded tables/indexes.
Import throughput experiments
Let us examine some simple experiments to understand the factors and configurations that can help ensure high speed data import. In the following experiments, we use a 40GB CSV file, which has 120 million rows of the following table schema.

The table below shows the target YugabyteDB cluster configuration used for these experiments.

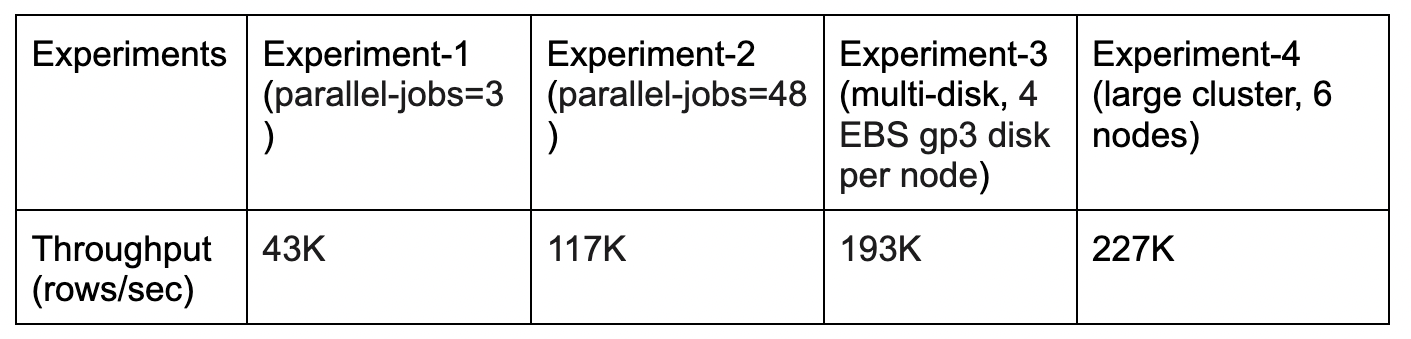
We ran four experiments as seen in the table below, with each of the columns describing the settings used in our four tests. Specifically, these 4 experiments have varying configurations and you can see the resulting throughput impacted by those settings. The batch-size configures as 200K in yb-voyager CLI options.
Get started and learn more
We’re thrilled to be able to deliver these enterprise-grade features in the newest version of our flagship product – YugabyteDB 2.15. We invite you to learn more and try it out:
- YugabyteDB 2.15 is available to download now! Installing the release just takes a few minutes.
- Join the YugabyteDB Slack Community for interactions with the broader YugabyteDB community and real-time discussions with our engineering teams.
Finally, Register for our 4th annual Distributed SQL Summit taking place in September.
NOTE: Following YugabyteDB release versioning standards, YugabyteDB 2.15 is a preview release. Many of these features are now generally available in our latest stable release, YugabyteDB 2.16.

")
