11 Things You Wish You Knew Before Starting with DynamoDB
July 10, 2018
DynamoDB is a fully managed NoSQL database offered by Amazon Web Services. While it works great for smaller scale applications, the limitations it poses in the context of larger scale applications are not well understood. This post aims to help developers and operations engineers understand the precise strengths and weaknesses of DynamoDB, especially when it powers a complex large-scale application.
The Good
1. Data Modeling
DynamoDB supports a document-oriented data model. To create a table, we just define the primary key. Items can be added into these tables with a dynamic set of attributes. Items in DynamoDB correspond to rows in SQL, and attributes in DynamoDB correspond to columns in SQL. DynamoDB supports the following data types:
- Scalar data types: Number, String, Binary, Boolean
- Collection data types: Set, List, Map
2. Operational Ease
By virtue of being a managed service, users are abstracted away from the underlying infrastructure and interact only with the database over a remote endpoint. There is no need to worry about operational concerns such as hardware provisioning, setup/configuration, throughput capacity planning, replication, software patching, or cluster scaling — making it very easy to get started.
In fact, there is no way to access the underlying infrastructure components such as the instances or disks. DynamoDB tables require users to reserve read capacity units (RCUs) and write capacity units (WCUs) upfront. Users are charged by the hour for the throughput capacity reserved (whether or not these tables are receiving any reads or writes).
3. Linear Scalability
DynamoDB supports auto sharding and load-balancing. This allows applications to transparently store ever-growing amounts of data. The linear scalability of DynamoDB is good for applications that need to handle growing datasets and IOPS requirements. However, as described later, this linear scalability comes with astronomical costs beyond a certain point.
4. AWS Ecosystem Integration
DynamoDB is well integrated into the AWS ecosystem. This means that end users do not need to figure out how to perform various integrations by themselves. Below are some examples of these integrations:
- Data can easily and cost-effectively be backed up to S3
- Easy to export data to Elastic MapReduce (EMR) for analysis
- Security and access control is integrated into AWS IAM
The Bad
5. Cost Effectiveness
As highlighted in The Million Dollar Engineering Problem, DynamoDB’s pricing model can easily make it the single most expensive AWS service for a fast growing company. Here are the top 6 reasons why DynamoDB costs spiral out of control.
Over-provisioning to handle hot partitions
In DynamoDB, the total provisioned IOPS is evenly divided across all the partitions. Therefore, it is extremely important to choose a partition key that will evenly distribute reads and writes across these partitions. If a table ends up having a few hot partitions that need more IOPS, total throughput provisioned has to be high enough so that ALL partitions are provisioned with the throughput needed at the hottest partition. This can lead to dramatic cost increases and frustrated engineers.
Cost explosion for fast growing datasets
The post You probably shouldn’t use DynamoDB highlights why DynamoDB is a poor choice for fast growing datasets. As data grows, so do the number of partitions in order to automatically scale out the data (each partition is a maximum of 10GB). However, the total provisioned throughput for a table does not increase. Thus, the throughput available for each partition will constantly decrease with data growth. To keep up with the existing rate of queries, the total throughput would have to be continually increased, increasing the total cost multi-fold!
Paid caching tier
As noted later in the post, when the latency of DynamoDB is not low enough, it is necessary to augment it with a cache (DAX or ElastiCache) to increase the performance. In either case, the caching tier is an additional expense on top of the database tier.
Indexes may cost extra
Applications wanting to query data on attributes that are not a part of the primary key need to create secondary indexes. DynamoDB supports Local Secondary Indexes and Global Secondary Indexes. Local Secondary Indexes do not incur extra cost, but Global Secondary Indexes require additional read and write capacity provisioned leading to additional cost.
Writes, strongly consistent reads and scans are expensive
Firstly, writes to DynamoDB are very expensive. Secondly, strongly consistent reads are twice the cost of eventually consistent reads. And thirdly, workloads performing scans can quickly get cost prohibitive. This is because the read capacity units actually take the number of bytes read into account.
Lack of lower cost test/dev tables
DynamoDB is a managed service, and therefore does not really distinguish between a customer-facing, production table vs. dev/test/staging tables.
6. Low Latency Reads
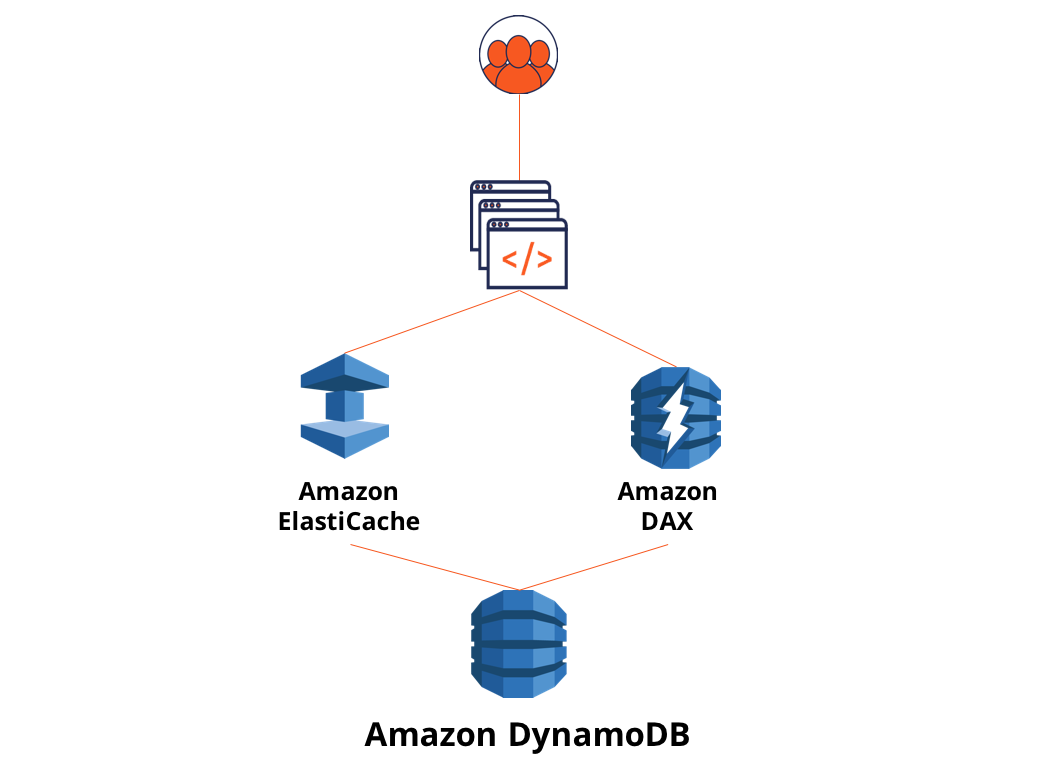
Given the lack of a built-in distributed cache, typical latency of operations in DynamoDB is in the 10ms–20ms range. Note that strongly consistent reads typically will have higher latencies than eventually consistent reads. Applications that are ok with these latencies can use DynamoDB as is. However, a large class of applications, requiring 1ms or lower latencies are required to use either DynamoDB Accelerator (DAX), an add-on transparent caching layer, or provision a separate ElastiCache, another AWS service that offers Redis as a managed cache. Note that these services cost extra, and compromise on data consistency and developer agility since the app has to deal with the additional complexity of populating the cache and keeping the cache consistent with the database.
7. Geo-Distribution
Global Tables, introduced late 2017, is the primary feature for adding geo-distribution to DynamoDB. Each region has an identical yet independent table (each charged separately) and all such tables are linked through an automated asynchronous replication mechanism, thus leading to the notion of a “Global Table”. However, this approach suffers from the same unpredictable last-writer-wins conflict resolution challenge that traditional multi-master database deployments suffer from. Concurrent writes across regions will lead to data loss and reads cannot be strongly consistent across those regions.
8. Development Agility
The microservices paradigm is being adopted widely to increase software development agility and accelerate release cycles. But in a microservice-oriented architecture, each microservice tends to read and write data independent of the others — for example, each microservice might re-read a user’s profile information to perform privacy checks and update different attributes of a user’s profile. This would increase the total IOPS on the database, even though the data might be cached. This results in tables being provisioned for much higher IOPS, making it very expensive.
Setting up a robust CI/CD (continuous integration and continuous delivery) pipeline is another critical paradigm to accelerate release cycles. But with DynamoDB being a managed service, it is very difficult to setup a CI/CD (as an example, verifying that the app is not impacted by database failures).
9. Troubleshooting in Production
A managed service is a great offering when everything works, but can be difficult to deal with in the face of troubleshooting. Even simple actions such as identifying the exact key that leads a partition becoming hot is complicated. The only option available is to rely on support from the managed service provider (AWS in this case) by filing a support ticket with them. This option might be slow and/or expensive. The loss of control on finding an alternative, quick fix could also often become frustrating.
The Ugly
10. Strong Consistency with High Availability
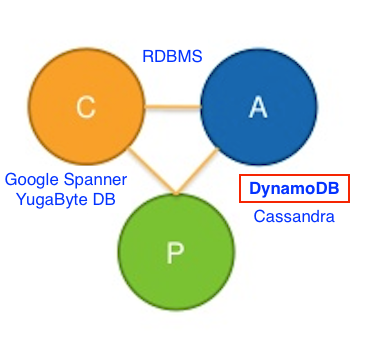
In terms of the CAP theorem, DynamoDB is an available and partition-tolerant (AP) database with eventual write consistency. On the read front, it supports both eventually consistent and strongly consistent reads. However, strongly consistent reads in DynamoDB are not highly available in the presence of network delays and partitions. Since such failures are common in multi-region/global apps running on public clouds such as AWS, DynamoDB tries to reduce such failures by limiting strongly consistent reads only to a single region. This in turn makes DynamoDB unfit for most multi-region apps and an unreliable solution for even single-region apps.
11. ACID Transactions and Secondary Indexes
DynamoDB is not ACID compliant. It only provides the ‘C’ (consistency) and ‘D’ (durability) in ACID. Here is an example of how to achieve ACID on top of DynamoDB, but this makes the application architecture very complex.
The global secondary indexes in DynamoDB are eventually consistent, and are not guaranteed to return correct results. Thus, DynamoDB is akin to most first generation NoSQL databases where a separate RDBMS tier is mandatory to handle the transactional portion of the app. Second generation NoSQL databases such as FoundationDB and YugabyteDB (which also supports SQL) remedy these problems through native support for distributed transactions and strongly consistent secondary indexes.
Update after AWS re:Invent 2018: As highlighted in our Why are NoSQL Databases Becoming Transactional? post, DynamoDB now supports transactions albeit in a severely restricted manner. These limitations include:
- Available for single-region tables only
- Limited to a maximum of 10 items or 4MB of data
- No client-controlled transactions
- No consistent secondary indexes even though transactions are supported
Summary
DynamoDB’s strengths and weaknesses can be summarized as below.
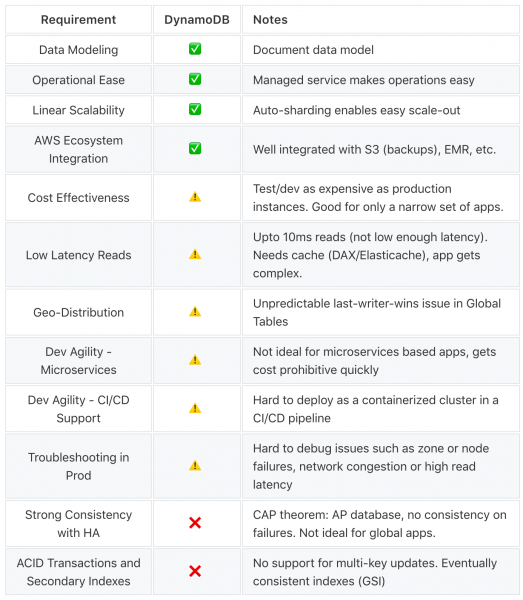
The ideal workloads for DynamoDB should have the following characteristics:
- Low write throughput.
- Small and constant dataset size, no unbounded data growth.
- Constant or predictable read throughput, should not be bursty or unpredictable.
- Apps that can tolerate eventually consistent reads, the least expensive data access operation in DynamoDB.
For a new app still in experimental phase of growth, the above criteria are a good fit. However, as the app hits fast growth, increasingly larger data volumes need to be stored and served. If we add low latency and geo-distribution as additional requirements for driving customer satisfaction, DynamoDB becomes a cost-prohibitive choice that also slows down release velocity. Our post, DynamoDB vs MongoDB vs YugabyteDB for Fast Growing Geo-Distributed Apps, reviews a few popular alternatives to DynamoDB.


