Why are NoSQL Databases Becoming Transactional?
December 17, 2018
The SQL vs. NoSQL database split started with the publication of the Google BigTable and Amazon Dynamo papers in 2006 and 2007 respectively. These original designs focused on horizontal write scalability without compromising the performance observed in the single node databases dominant at that time. The compromises instead came either in the form of eventual consistency (i.e. inability to read the last update) or loss of multi-key access patterns (such as SQL integrity/foreign key constraints, ACID transactions and JOINs) or both. NoSQL became synonymous with “Non-Relational” and “Non-Transactional” where queries could typically access only a single key (or a range of nearby keys) at a time and even read-your-own-write consistency guarantee was considered out of norm. In fact, eventual consistency under failures could lead to a value that was either never committed in the database or was completely out of order. Given these fundamental limitations, developers continued to use monolithic SQL /RDBMS for business-critical workloads and use of NoSQL became limited to workloads with ever-growing but not-so-business-critical data needs.
However, big changes are happening in the NoSQL world in the last couple years. Multiple old and new NoSQL databases alike have embraced one or more flavors of ACID transactions. Through this post, we want to inform application architects on how these changes are being implemented in popular proprietary and open source databases. Finally, we also review why such changes did not happen in NoSQL’s first decade but are now happening faster than ever before in the second decade.
Rise of Transactional NoSQL
Proprietary
In this section we review three proprietary NoSQL databases and their transactional capabilities. By definition, proprietary means that these are closed source and/or managed-service-only databases that expose users to vendor lock-in risks.
Amazon DynamoDB
Amazon DynamoDB, first introduced to the world as an AWS managed service in 2012, is one of the most popular NoSQL databases out there. It acts as a successor to Amazon SimpleDB, which was AWS’s first managed NoSQL offering. From a design standpoint, DynamoDB brings together the best parts of the original Dynamo paper (scalability and performance) and Amazon SimpleDB (ease of administration and table-based data modeling that’s richer than a simple key-value store). If you are new to DynamoDB, we recommend our post 11 Things You Wish You Knew Before Starting with DynamoDB.
Dynamo, the Amazon internal database that led to the Dynamo paper, was created in 2004 when Amazon.com engineers realized that 70% of their workloads were single key-value operations that had no use for the relational features that their Oracle DB was offering. And for another 20% of workloads, the access pattern was limited to a single table. Only the remaining 10% was relational with access across multiple random keys. This insight allowed the engineers to design a new database that gives up on relational data modeling altogether and focuses on serving single key-access patterns. Additionally, they chose Availability over Consistency in the CAP Theorem with the rationale that users expect 100% availability from their systems but won’t be able to notice consistency issues. DynamoDB carried these same design principles forward and remained committed to them till AWS re:Invent 2018 came by.
DynamoDB “Eventually” Adds Transactions But With Strings Attached
As highlighted in our “AWS re:Invent 2018 Recap” post, DynamoDB recently announced support for transactions! There are severe limitations in the current offering so developers have to take care not to trip up during the rush to release transactional apps powered by DynamoDB. Limitations include:
- Available for single-region tables only
- Limited to a maximum of 10 items or 4MB of data
- No client-controlled transactions
- No consistent secondary indexes even though transactions are supported
In spite of these limitations, this is a milestone moment in the history of databases where one of the pioneers of the Non-Transactional NoSQL movement changed its core philosophy and embraced the emerging Transactional NoSQL movement.
Microsoft Azure Cosmos DB
Cosmos DB is essentially Microsoft Azure’s answer to Amazon DynamoDB. It started in 2010 as a Microsoft internal project and came to the public view in 2015 as a Azure service called DocumentDB. In 2017, Azure expanded the DocumentDB scope by adding new APIs and renamed the entire offering to Cosmos DB. Today Cosmos DB offers 5 different APIs – the original DocumentDB API with SQL support for queries, a MongoDB compatible API, a Cassandra compatible API, a Gremlin API for graph data modeling and a key-value API. We can see that all these APIs are tailored towards single-key access patterns so multi-key/relational data modeling is not supported.
Across all the APIs, Cosmos DB supports strongly consistent writes and reads in only the primary region where the particular key is located. Since there is no synchronous replication across regions, multi-region writes and reads can be only eventually consistent. Cosmos DB’s support for strong consistency (aka single-key ACID) albeit limited qualifies it as a single-region-only Transactional NoSQL.
Note: There is no notion of single-shard or multi-shard ACID transactions yet.
FaunaDB
FaunaDB launched as a serverless managed service in 2017. Since then it has added new deployment options including an Enterprise On-Premises option for more traditional customers who are not ready for the public cloud yet. FaunaDB bills itself as a relational and transactional NoSQL database. The relational aspect of the data modeling comes from its custom proprietary API that does not support SQL but still aims to provide SQL-like constructs such as JOINs, foreign keys and unique indexes. The transactional guarantees are backed by the Calvin-inspired architecture. Our post, “Google Spanner vs. Calvin: Is There a Clear Winner in the Battle for Global Consistency at Scale?” highlights the pros and cons of the Calvin architecture.
Open Source
Open source databases are by definition open from a source code standpoint and often undertake a community-driven development process so that users of the database get a say in how the database is designed and developed. Needless to say, there is no vendor lock-in risk in an open source database since one can continue to use the database without needing a purchase agreement with the vendor of the database. In this section, we review three open source transactional NoSQL databases.
MongoDB
Keeping aside the debate of whether the recent license change of MongoDB (from AGPL to SSPL) still qualifies it as an open source DB, it is easy to state that MongoDB has emerged as a popular datastore for web and mobile applications. As one of original open source NoSQLs with an eventually consistent architecture (along with Apache Cassandra), MongoDB long argued that strong consistency, ACID transactions and relational data modeling are for old school applications that do not care for high scalability. First, there was the argument that strong consistency and transactions are bad for low latency applications because the write path now requires commit at multiple replicas in a Replica Set. This argument conveniently missed to note that committing a write at only one node is a pyrrhic victory on the latency front because it comes at the cost of data loss in presence of failures. Note that disk, node and network failures are unavoidable in the inherently-unreliable infrastructure offered by the public cloud platforms. Then, there is the evangelism of data denormalization that aims to convince developers to create self-contained single MongoDB documents so that the need for multi-key access patterns can be avoided altogether. Again, this evangelism fails to note how non-intuitive data modeling can become and how much data duplication needs to be done across the documents.
Our post, “Are MongoDB’s ACID Transactions Ready for High Performance Applications?” details how MongoDB has been slowly changing the above philosophy over the last few years. Not only MongoDB 3.4 had to adopt a more resilient Replica Set primary election protocol (based on Raft), it also had to add a linearizable read concern to satisfy applications needing strongly consistent reads (assuming the writes were executed at majority concern). However, given that actual data replication is still asynchronous, using this linearizable read concern essentially means paying the high latency penalty associated with quorum reads. MongoDB 4.0 followed up on the transactional dimension by adding single-shard transactions that allow multiple documents in a single Replica Set to be updated with ACID guarantees. Multi-shard transactions that work in a MongoDB Sharded Cluster is not yet available.
FoundationDB
Started in 2009, FoundationDB was probably the first transactional NoSQL database on the market. However, Apple acquired it in March 2015 before it could achieve any significant adoption. The database became closed source and vanished away from the public view altogether. Fast forward to April 2018 when Apple re-introduced FoundationDB to the market as an Apache 2.0 open source project. The initial release included support for single-region multi-shard transactions on a key-value API.
FoundationDB positions itself as a common database core for building multiple database APIs. Its basic key-value API functions as a good starting for building higher level database APIs called Layers. In November 2018, the FoundationDB team announced the availability of their first Layer in the form a MongoDB-compatible Document API.
TiKV
TiKV is a new distributed transactional key-value store that draws design inspirations from Google Spanner and Apache HBase. It provides two APIs, namely Raw KV and Transactional KV, for developers to use based on whether their application needs multi-shard transactions and/or multi-version concurrency control (MVCC). TiKV serves as the foundation to TiDB, a distributed SQL database optimized for single-region Hybrid Transactional & Analytical Processing (HTAP) workloads. In this respect, TiKV’s philosophy is similar to that of FoundationDB where a simple KV layer can serve as the core for more complex database APIs.
The Reasons Behind NoSQL Embracing Transactions in 2017-2018
The first decade of NoSQL (2006-2016) was all about educating software engineers on the benefits of horizontally scalable, shared-nothing database architectures while maintaining high performance through avoidance of relational data modeling. This was a herculean task to say the least when monolithic SQL databases such as Oracle, MySQL and PostgreSQL ruled the roost. Since this era also coincided with the Big Data/Hadoop era, one of the easiest use cases to introduce NoSQL was that of a “Big Data sink” where the intermediate and final results of a Big Data analytics pipeline could be easily stored for serving to end users without any need for transactional guarantees. Any lost data was re-computed back from the raw data.
After the introduction of DynamoDB in 2012, application architects realized the pivotal role non-relational databases can play in building internet-scale, user-facing applications. By then MongoDB had already helped JavaScript developers build user-facing applications fast but durability and scaling challenges remained. DynamoDB initially attacked both these problems better than MongoDB. However, given the lack of ACID transactions, every user-facing application had no choice but to also use a monolithic SQL/RDBMS alongside a distributed NoSQL such as DynamoDB or MongoDB. Every potential source of data was carefully analyzed to understand the ingestion/storage needs as well as the ability to tolerate data loss. Low-volume, zero-data-loss data went to the SQL DB while the high-volume, data-loss-ok data went to the NoSQL DB. Unfortunately, if there was high-volume, zero-data-loss data then manually sharding the SQL DB was the only option.
As described in one of our most popular posts, “NoSQL vs SQL in 2017,” smart engineers had realized by 2017 that this division between SQL and NoSQL datastores is significantly slowing down application release velocity. Architects have to spend more time thinking through this divide, developers have to then code against this divide, the CI/CD pipeline has to account for this divide and finally the overworked operations team have to deploy and run efficiently two or more different types of database clusters and that too across multiple environments and in multiple data centers. Since then NoSQL is becoming transactional with the goal of making application development, deployment and operations simpler, faster and more resilient than ever before. SQL is also becoming distributed for exactly the same reason. Note that the ability to use an existing NoSQL database for transactional workloads is not only a 50% reduction in engineering pain but also highly cost efficient especially when it allows avoiding additional Oracle licenses.
YugabyteDB’s Unique Value Proposition
That NoSQL databases will become transactional is one of the founding theses behind YugabyteDB when we started the project nearly 3 years back. We believed that SQL too will become distributed for exactly the reasons outlined above. Our work experiences at Oracle & Facebook helped us understand that the NoSQL and SQL APIs are simply means to model the desired end goal of application agility — the real innovation in database software will come from building a core engine that can easily handle multiple data models without compromising on the core guarantees of transactions, high performance and geo-distribution. This in turn ensures that your operational database infrastructure is not only fit-for-purpose on day 1 but is also future-proof for years to come.
Let’s review how YugabyteDB’s API and storage layers are architected with the above goals in mind.
API Layer – Unparalleled Data Modeling Freedom
Applications interact with the database using either a NoSQL or a SQL API. NoSQL APIs focus on single-key access patterns and come in many flavors with key-value and flexible schema (or document) being the two most common. SQL APIs model relational data with complex relationships or dependencies across multiple keys.
Key-value APIs are usually the most restrictive as far as data modeling complexity is concerned but the resulting modeling simplicity lends itself to high performance in terms of low latency and high throughput. Flexible schema APIs are a step ahead of key-value APIs in terms of data modeling sophistication since the value part of the key is no longer restricted to a single value or a single data structure. A key can have a flexible number of values or columns associated with it. It should not come as a surprise that the database has to do more work to fetch these additional columns (and the associated indexes) and hence may be of slower performance than a simple key-value API. Even updating individual columns may get more expensive. At the very end of the spectrum is the SQL API with its complex relational data modeling capabilities. Even assuming that the SQL API has been optimized to run on a distributed storage layer, fetching data from multiple different shards located on multiple different nodes would still naturally be slower than the NoSQL APIs. These insights led us to create three different APIs for YugabyteDB as shown below.
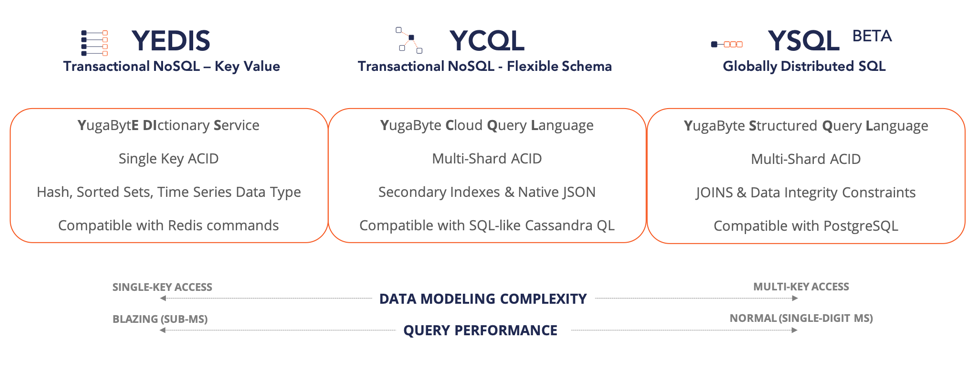
For the first time ever, application developers have unparalleled freedom when it comes to modeling data for workloads that require internet scale, transactions and geo-distribution. Additionally, instead of creating three proprietary APIs from scratch, we made our APIs compatible with APIs from existing popular databases. Redis’s support for elegant data structures such as sorted sets made it a natural fit for our YEDIS key-value API. YCQL’s compatibility with Cassandra Query Language (CQL) was driven by the fact that CQL is simply a scale-out ready version of SQL with explicit partition keys and clustering columns. To make YCQL an even stronger flexible schema API, we added important features such as native JSON support, global secondary indexes and multi-shard transactions all of which are missing in the original CQL spec. Finally, as previously described in, “Introducing YSQL: A PostgreSQL Compatible Distributed SQL API for YugabyteDB,” PostgreSQL’s open and rapidly growing ecosystem helped seal our decision in its favor in the context of YSQL’s compatibility.
Storage Layer – A Transactional Document Store Inspired by Google Spanner
All the three YugabyteDB APIs are powered by a common transactional document store called DocDB. From a core storage engine standpoint, DocDB builds on top of the popular RocksDB project by transforming RocksDB from a key-value store (with only primitive data types) to a document store (with complex data types). Every key is stored as a separate document in DocDB, irrespective of the API responsible for managing the key. DocDB’s sharding, replication/fault-tolerance and distributed ACID transactions architecture are all based on the the Google Spanner design first published in 2012.
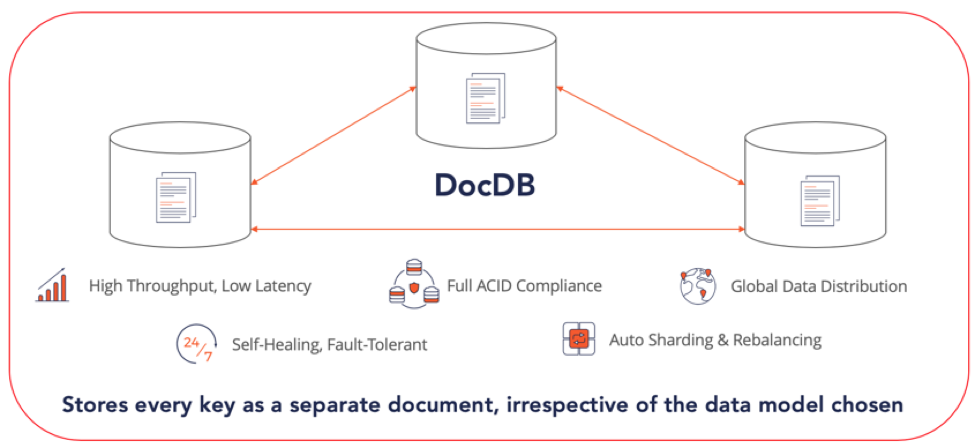
DocDB is designed to provide the same transactional, high performance and global data distribution guarantees to each of the three APIs. The APIs serve the client requests by managing one or more keys in DocDB — the two NoSQL APIs focus on single-key access while the SQL API can work with relationships across multiple keys.
Summary
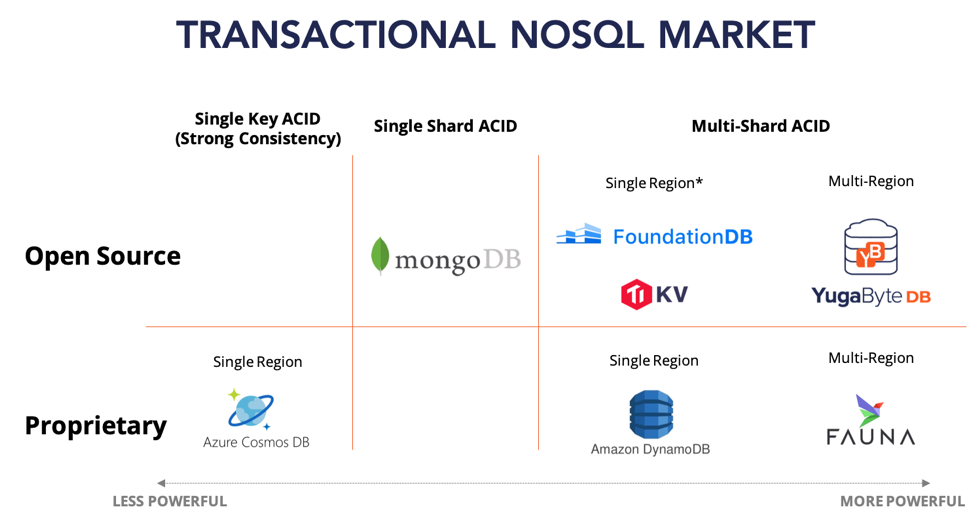
The emerging transactional NoSQL market can be summarized as per the figure below. One aspect requires further elaboration. As open source databases, FoundationDB and TiKV do not restrict users to single region deployments. A single cluster can indeed be deployed across multiple regions. However, such a multi-region deployment would be impractical because both databases use a single timestamp source for committing transactions which essentially leads to extremely high latencies (assuming the timestamp oracle will be in a different region for a majority of transactions in a random access OLTP workload). Our post “Implementing Distributed Transactions the Google Way: Percolator vs. Spanner” describes this issue in greater detail.
All of us at YugaByte are excited to be playing an integral role in shaping this market. The competition observed in the market is already benefiting the users in the form of stronger offerings that they can trust and adopt at scale. Given that YugaByte is also helping shape the Distributed SQL market, we look forward to coming back in 2019 with our analysis of that market. Till then, we wish all our readers happy holidays and a joyful new year!
What’s Next?
- Compare YugabyteDB in depth to databases like Amazon DynamoDB, MongoDB and Azure Cosmos DB.
- Get started with YugabyteDB on macOS, Linux, Docker and Kubernetes.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.


