A Migration Journey from Amazon DynamoDB to YugabyteDB and Hasura
December 4, 2020
At the Distributed SQL Summit 2020, Tobias Meixner – CTO & Co-Founder at BRIKL, presented the talk, “A Migration Journey from Amazon DynamoDB to YugabyteDB and Hasura.”
Switching databases is painful, even more so when going from NoSQL to SQL. In this talk Tobias gave us insights into BRIKL’s two key elements of their migration path. First, migrating from Apollo Server and Amazon DynamoDB over to Hasura and YugabyteDB. Second, migrating from a growing monolith to a scalable service-oriented architecture.
Enabling ecommerce sites to sell customized products
BRIKL helps brands, retailers, and manufacturers sell custom team wear, sportswear, promotional wear, sports equipment, and any other customizable product online.
BRIKL offers a full ecommerce solution for custom and stock products. With BRIKL, you can create an online shop for your business, set up team stores, integrate your 3D configurator, sell products online, and collect payments.
A look at BIRKL’s data model
In the next part of the presentation Tobias walked us through their GraphQL ecommerce data model which includes objects to manage products, collections, designs, configurations, leads, quotes discounts, payments, shipping, notifications, and more.

DynamoDB’s strengths and weakness
Tobias next covered his experience with GraphQL and Amazon DynamoDB. Here’s what he liked:
- DynamoDB’s document data model is easy to get started with
- Lots of AWS integrations and tooling is available to make operating DynamoDB easier
- Support for auto-sharding allows the system to easily scale out
Next, Tobias covered the challenges his team experienced with using DynamoDB:
- Can be unpredictably expensive
- Latency can be an issue without caching
- Not ideal for microservices based apps
- No guarantees around consistency
- Developer experience is very challenging beyond simple applications as skills from other databases do not translate well
- DynamoDB’s single table design makes it impossible to create sophisticated data models
- Creating additional indexes will increase costs
Requirements for a new database
Because BRIKL wanted to move past the limitations of DynamoDB, they had to first define the requirements for their new data infrastructure. These included:
- An excellent developer experience where existing developer skills could be easily translated onto the new platform
- Support for flexible data modeling while delivering performant queries
- Global replication should be supported “out-of-the-box”
- Support for GraphQL
- From a DevOps standpoint, “no code” and “no ops”
Migrating to YugabyteDB and Hasura GraphQL
BRIKL has gone all in on GraphQL so it was critical that whatever database they selected for the next iteration of their platform must integrate very well with GraphQL.
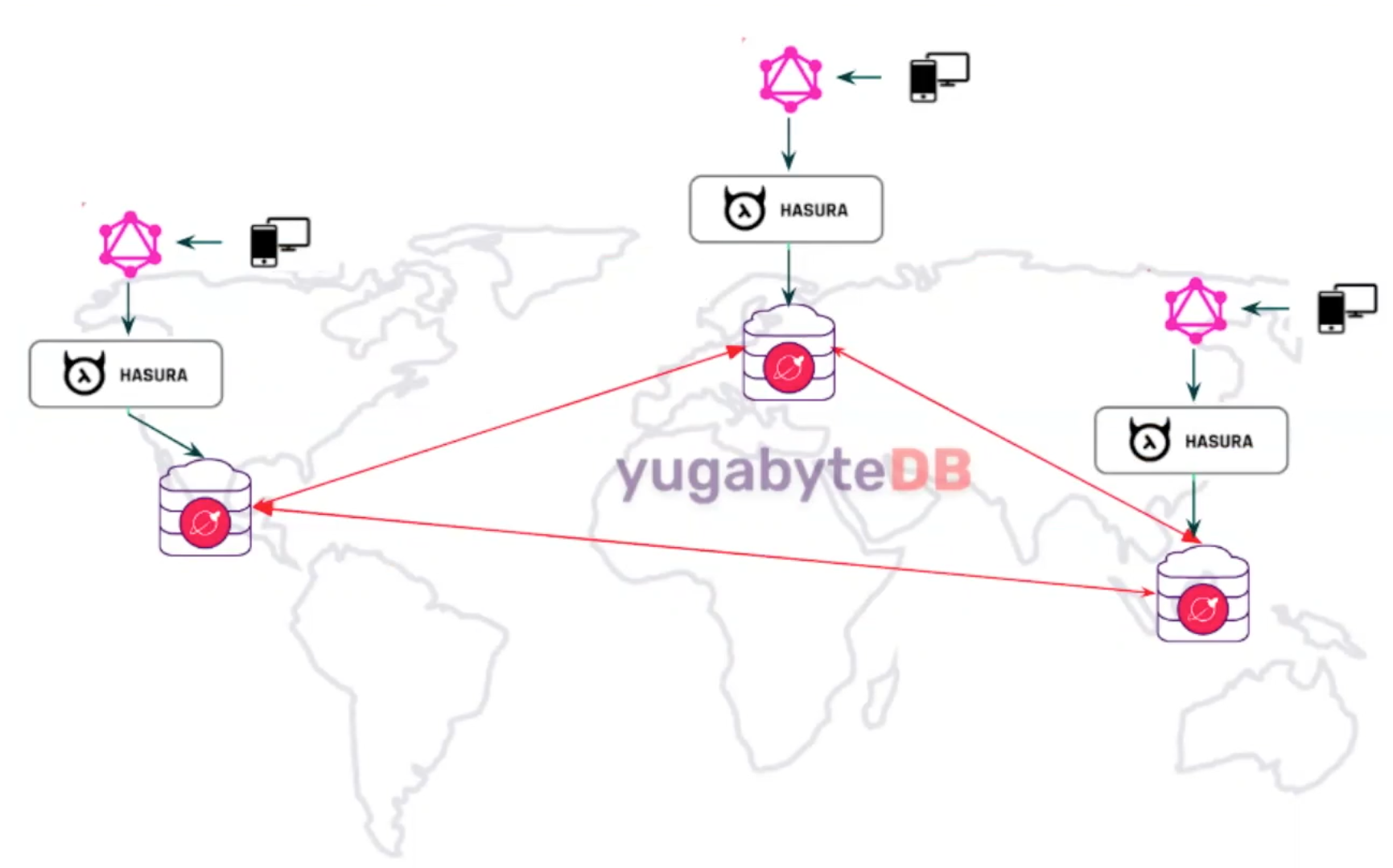
Tobias next pointed out that there is no right or wrong way to do a NoSQL (DynamoDB) to SQL (YugabyteDB’s PostgreSQL-compatible API) migration as each application and organization is different, plus the available resources, time, and developer skills are variable. His recommendation was to use a migration as an opportunity to type your data, rethink existing data models, and take advantage of data types that don’t exist in some NoSQL systems, like JSON.
There were three approaches that the BRIKL team considered when it came to the migration. First, use DynamoDB Streams, which offers a lot of flexibility. Second, use an AWS data pipeline, which came with a significant learning curve. And finally, using custom scripts in conjunction with Lambda and EC2.
Ultimately, the BRIKL team decided that for their needs, the best migration approach was to start from scratch and re-architect their entire application along the way. Steps in the process included:
- Clean up deprecated features
- Break up the existing monolith application into microservices
- Start with less critical services and then advance to more complex ones
- Have clients connect to new API endpoints step by step using feature flags
In regards to the actual data migration, the BRIKL made use of DynamoDB’s full table scan feature, then did a bulk import of existing data with custom scripts, and finally was able to re-import all or just deltas during the cut over.
Finally, in making the switch from Prisma GraphQL to Hasura GraphQL there were some missing features the BRIKL team had to work around, detailed below:
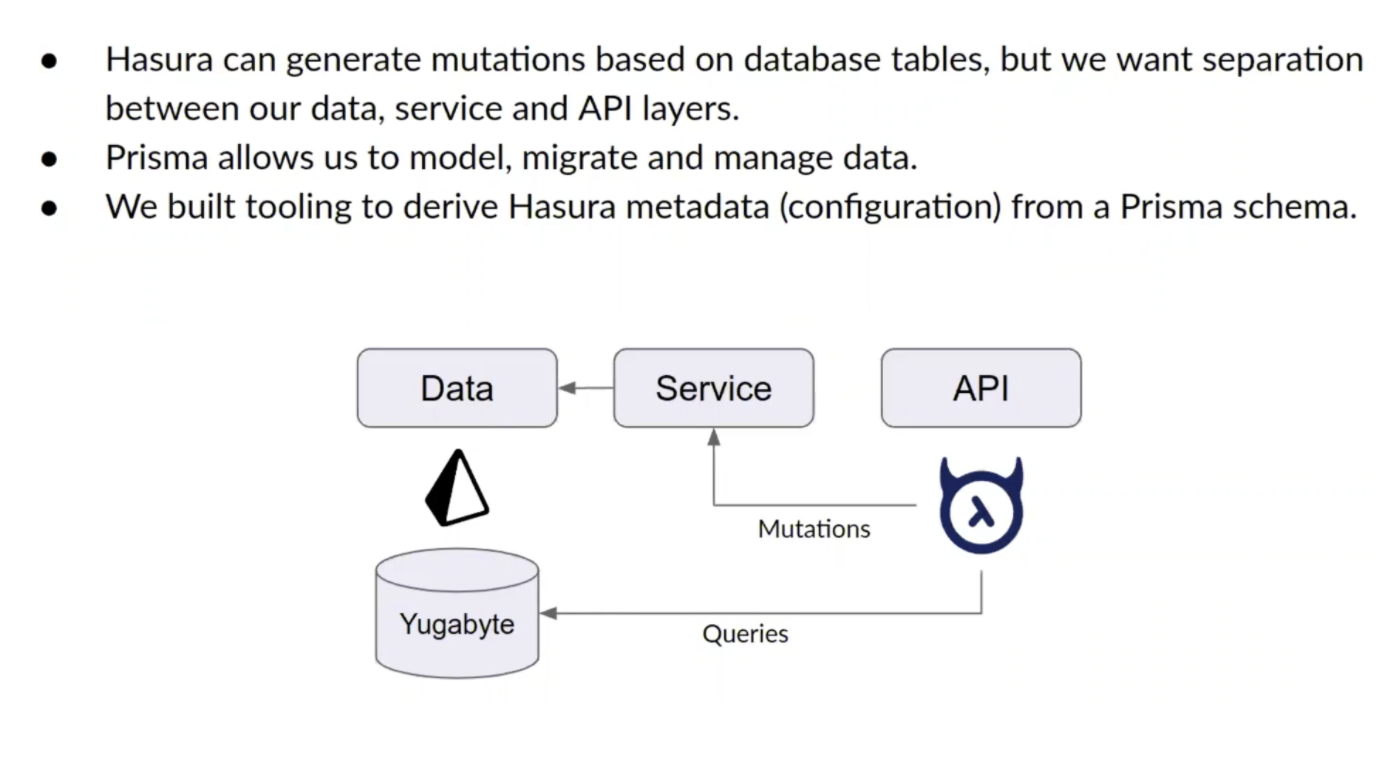
To learn more about BRIKL’s deployment architecture, implementation details, and performance numbers make sure to watch the video!
Want to see more?
Check out all the talks from this year’s Distributed SQL Summit including Pinterest, Mastercard, Comcast, Kroger, and more on our Vimeo channel.

