5 Reasons Why Apache Kafka Needs a Distributed SQL Database
May 21, 2019
Modern enterprise applications must be super-elastic, adaptable, and running 24/7. However, traditional request-driven architectures entail a tight coupling of applications. For example, App 1 asks for some information from App 2 and waits. App 2 then sends the requested information to App 1. This sort of app-to-app coupling hinders development agility and blocks rapid scaling.
In event-driven architectures, applications publish events to a message broker asynchronously. They trust the broker to route the message to the right application, and the receiving parties subscribe to key events that interest them. Putting events first shifts the focus to the app’s users and their actions, supporting flexible, time-critical, context-sensitive responses.
In this post, we review the architectural principles behind Apache Kafka, a popular distributed event streaming platform, and list five reasons why Apache Kafka needs to be integrated with a distributed SQL database in the context of business-critical event-driven applications.
Apache Kafka
Since getting open sourced out of LinkedIn in 2011, Apache Kafka has gained massive adoption and has become an integral component of modern large-scale real-time data services. It serves as a publish-subscribe messaging system for distributed applications and hence avoids applications from getting tightly coupled with each other. Kafka use cases range from stream processing, and real-time messaging, to website activity tracking, metrics monitoring, and event sourcing. It is used by many of the Fortune 500 companies, including web-scale enterprises such as LinkedIn, PayPal, Netflix, Twitter, and Uber.
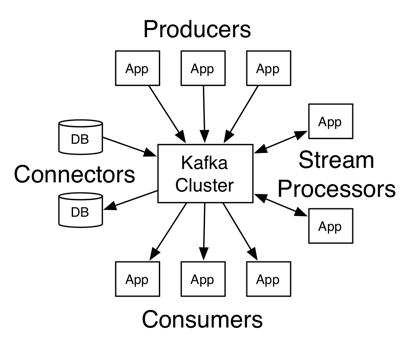
In Kafka, all messages are written to a persistent log and replicated across multiple brokers. The overall architecture also includes producers, consumers, connectors, and stream processors. Kafka is run as a cluster on one, or across multiple servers, each of which is a broker. The cluster stores streams of records in categories called topics. Each Kafka broker has a unique ID and contains topic partitions. Producers write to topics, and consumers read from topics. Connectors establish a link between Kafka topics and existing data systems. Stream processors transform input streams to output streams.
Following are the top three design principles behind Kafka that make it ideal for event-driven architectures.
Ordering & Delivery Guarantees
In Kafka, physical topics are split into partitions. A partition lives on a physical node and persists the messages it receives. Kafka preserves the order of messages within a partition. This means that if messages were sent from the producer in a specific order, the broker will write them to a partition in that order and all consumers will read them in that order. For example, if you have a topic with user actions which must be ordered, but only ordered per user, then all you have to do is to create topic partitions using a consistent message key, for example, userId. This will guarantee that all messages for a certain user always ends up in the same partition and thus is ordered.
Next is delivery guarantees. Three such guarantees are possible.
- At most once – Messages may be lost but are never redelivered.
- At least once – Messages are never lost but may be redelivered.
- Exactly once – Each message is delivered once and only once.
Kafka guarantees at-least-once delivery by default, and allows the user to implement at-most-once delivery by disabling retries on the producer and committing offsets in the consumer prior to processing a batch of messages. Additionally, Kafka supports exactly-once delivery in Kafka Streams, and the transactional producer/consumer can be used generally to provide exactly-once delivery when transferring and processing data between Kafka topics.
Horizontal Scalability
Scalability is a key characteristic for many online apps, and hence is a critical need for growing organizations. Apache Kafka is distributed in the sense that it stores, receives, and sends messages on different servers. It is also horizontally scalable, making it simple to add new Kafka servers when your data processing needs grow. With Kafka, you get both read and write scalability. This means that you can stream a huge workload into Kafka, and at the same time perform close-to-real-time processing of incoming messages — including publishing them to different systems across several topics.
At the heart of Kafka is the distributed log structure, which makes it useful for running large scale messaging workloads. New Kafka messages are appended to the end of the log file. Reads and writes are sequential operations. Data can be sequentially copied directly from disk to network buffer for efficiency. This is quite different compared to traditional message brokers, which typically use hash tables, or indexes. They require tuning and need to be kept fully in memory, which can be costly to run.
Fault Tolerance
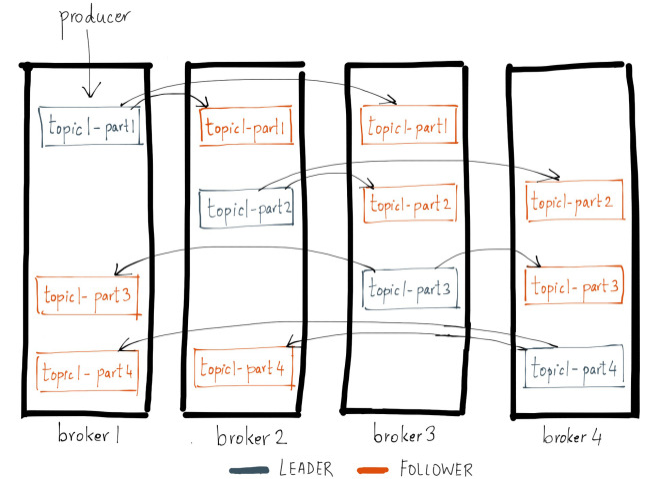
Replication of Kafka Topic Partitions (Source: Confluent)
As shown above, a Kafka topic partition is essentially a log of messages that is replicated across multiple broker servers. One of the replicas is elected a leader while remaining are followers. The fundamental guarantee a log replication algorithm must provide is that if it tells the client a message is committed, and the leader fails, the newly elected leader must also have that message. Kafka gives this guarantee by requiring the leader to be elected from a subset of replicas that are “in sync” with the previous leader. The leader for every partition tracks this In-Sync Replica (ISR) list by computing the lag of every replica from itself and storing it in ZooKeeper. When a producer sends a message to the broker, it is written by the leader and replicated to all the partition’s replicas. A message is committed only after it has been successfully copied to all the in-sync replicas. Since the message replication latency is capped by the slowest in-sync replica, it is important to quickly detect slow replicas and remove them from the in-sync replica list.
Apache Kafka + Distributed SQL = Developer Agility
While Kafka is great at what it does, it is not meant to replace the database as a long-term persistent store. This is because the persistence in Kafka is meant to handle messages temporarily while they are in transit (from producers to consumers) and not to act as a long-term persistent store responsible for serving consistent reads/writes from highly-concurrent user-facing web/mobile applications. While monolithic SQL databases such as MySQL and PostgreSQL can do the job of such a persistent store, there is an impedance mismatch between their monolithic nature and Kafka’s distributed nature that we reviewed previously. This is where modern distributed SQL databases such as YugabyteDB come in. These databases have a sharding and replication architecture that’s quite similar to that Kafka and hence they aim to deliver similar benefits. Following are the five key benefits of a distributed SQL database in a Kafka-driven messaging platform.
1. Horizontal Write Scalability
Your Kafka cluster is infinitely scalable, but what happens when your database cluster is not? The answer is loss of agility. You essentially create a central bottleneck in your data infrastructure. The solution lies in a distributed database, ideally a distributed SQL database that can scale horizontally similar to a NoSQL database. Distributed SQL databases do so through the use of automatic sharding for every table similar to Kafka creating multiple partitions for each topic. And they do so without giving up on strong consistency, ACID transactions and above all SQL as a flexible query language. Need to handle peak traffic during Black Friday? Simply add more Kafka brokers and distributed SQL nodes. And scale in gracefully after Cyber Monday. Note that it is relatively easy to achieve horizontal read scalability in monolithic SQL databases (by serving slightly stale reads from slave replicas) but it is not possible to achieve native horizontal write scalability.
2. Native Failover & Repair
With ISR model and f+1 replicas, a Kafka topic can tolerate f failures without losing committed messages. Modern distributed SQL databases typically use a majority-vote-based per-shard distributed consensus protocol (such as Raft or Paxos) which allows them to tolerate f failures given 2f+1 replicas. This tolerance includes zero data loss as well as native failover and repair (through automatic election of new leaders for the impacted shards). The additional f replicas in the database allows it perform low latency writes without waiting for the slowest replica to respond. As described previously, Kafka’s replication protocol does not offer this benefit but rather expects a lower replication factor to be used if slow replicas become an issue. It is natural that the distributed SQL databases provide more stringent combination of data durability and low latency guarantees than Kafka because of their role as the long-term destination of the data.
3. Global Consistency & Distributed ACID Transactions
What if you need to process, store and serve data with extreme correctness and low latency to a user population that’s distributed across multiple geographic regions? Modern retail, SaaS, IoT and gaming apps fall into this category. You can deploy a Kafka cluster in each datacenter/region and then use solutions such as Confluent Replicator or MirrorMaker to perform cross-datacenter replication. What do you do for your database in each of these regions? Look for Google Spanner-inspired distributed SQL databases like YugabyteDB because they not only ensure global ordering for single-row operations but also support fully distributed multi-row/multi-shard transactions in case you need them — all in a single database cluster that spans multiple regions! Depending on your application needs, you may even avoid using Kafka cross-datacenter replication altogether and simply rely on the globally consistent replication of the database.
4. Low Latency Reads
The topic partition leader in Kafka is always ready to serve the producers with the latest data and that too without communicating with any of the replicas in the process. You want exactly the same property in the database that serves your user-facing app. This is because the app will be generating many more concurrent requests to your database cluster in response to user requests. If the database now has to perform a quorum among the replicas to serve each such request, then naturally the application will feel slow to the end user. With their per-shard distributed consensus architecture (where a shard leader always has the latest data), Spanner-inspired distributed SQL databases are built to serve strongly consistent reads (from the shard leader) without performing any quorum among the replicas.
5. SQL’s Query Flexibility
As previously highlighted in “Why Distributed SQL Beats Polyglot Persistence for Building Microservices?”, SQL is making a comeback in a big way. NoSQL’s model-your-query approach is very inflexible if the query needs to be changed in response to changing business requirements. On the other hand, SQL’s model-your-data approach is more flexible to such changes. Given that distributed SQL databases address the scalability and fault-tolerance challenges of monolithic SQL databases, there is no good reason to keep relying NoSQL databases for business-critical event-driven applications.
Integration Approaches

There are two approaches of integrating a distributed SQL database with Kafka. Kafka provides Kafka Connect, a connector SDK for building such integrations.
As a Sink for Kafka
In this approach, a sink connector delivers data from Kafka topics into tables of the database. For example, the Kafka Connect YugabyteDB Sink connector highlighted in the next section can subscribe to specific topics in Kafka and then write to specific tables in YugabyteDB as soon as new messages are received in the selected topics.
As a Source for Kafka
In this approach, a source connector streams table updates in the database to Kafka topics. The database should ideally support Change Data Capture (CDC) as a feature so that the connector can simply subscribe to these table changes and then publish the changes to selected Kafka topics. “The Case for Database-First Pipelines” highlights the need for a database to become the source for Kafka in the context of an Instacart-like online store.
Note that YugabyteDB’s support for CDC is currently in active development and is targeted for release in the upcoming Summer 2019 release.
Kafka Connect YugabyteDB Sink in Action
Apache Kafka can stream out data into YugabyteDB using the Kafka Connect YugabyteDB Sink Connector. An example scenario where this kind of integration is used, is a fleet management company that wants to track their vehicles which are delivering shipments. Event streams are ingested in real-time by Kafka and also are written into the YugabyteDB database for long term persistence. A stream processor such as KSQL or Apache Spark Streaming is used to analyze trends in the data with the final results again stored in YugabyteDB. Online applications such as rich interactive dashboards for business users can then be powered from YugabyteDB.
1. Install YugabyteDB
Install YugabyteDB on your local machine.
2. Create local cluster
Start a local cluster to test the Kafka integration.
Check that you are able to connect to YugabyteDB:
$ ./bin/cqlsh localhost
Create table test_table. Incoming Kafka events will be stored in this table.
cqlsh> CREATE KEYSPACE IF NOT EXISTS demo; cqlsh> CREATE TABLE demo.test_table (key text, value bigint, ts timestamp, PRIMARY KEY (key));
3. Download Apache Kafka
Get the latest release from the Apache Kafka downloads page. This blog uses Apache Kafka 2.2.0.
$ mkdir -p ~/yb-kafka && cd ~/yb-kafka $ wget https://us.mirrors.quenda.co/apache/kafka/2.2.0/kafka_2.11-2.2.0.tgz $ tar xvfz kafka_2.11-2.2.0.tgz && cd kafka_2.11-2.2.0
4. Install the Kafka Sink Connector for YugabyteDB
Clone the yb-kafka-connector git repo.
$ cd ~/yb-kafka $ git clone https://github.com/YugaByte/yb-kafka-connector.git $ cd yb-kafka-connector/
Build the repo to get the connector jar.
$ mvn clean install -DskipTests
The connector jar yb-kafka-connnector-1.0.0.jar is now in the ./target directory. Copy this jar to the libs directory in Kafka Home.
$ cp ./target/yb-kafka-connnector-1.0.0.jar ~/yb-kafka/kafka_2.11-2.2.0/libs/
Go to the Kafka libs directory and get the additional jars that the connector needs (including the driver for the YCQL API).
$ cd ~/yb-kafka/kafka_2.11-2.2.0/libs/ $ wget https://central.maven.org/maven2/io/netty/netty-all/4.1.25.Final/netty-all-4.1.25.Final.jar $ wget https://central.maven.org/maven2/com/yugabyte/cassandra-driver-core/3.2.0-yb-18/cassandra-driver-core-3.2.0-yb-18.jar $ wget https://central.maven.org/maven2/com/codahale/metrics/metrics-core/3.0.1/metrics-core-3.0.1.jar
5. Start ZooKeeper and Kafka
$ cd ~/yb-kafka/kafka_2.11-2.2.0
Make sure to run Zookeeper first.
$ ./bin/zookeeper-server-start.sh config/zookeeper.properties &
$ ./bin/kafka-server-start.sh config/server.properties &
Next, create the topic that we’ll use to persist messages in the YugabyteDB table.
$ ./bin/kafka-topics.sh --create \
--zookeeper localhost:2181 \
--replication-factor 1 \
--partitions 1 \
--topic test6. Start Kafka Connect YugabyteDB Sink Connector
Now, we have YugabyteDB’s YCQL API running at the 9042 port with the table test_table created in the demo keyspace. We also have Kafka running at the 9092 port with topic test_topic created. We are ready to start the connector.
$ ./bin/connect-standalone.sh \~/yb-kafka/yb-kafka-connector/resources/examples/kafka.connect.properties \~/yb-kafka/yb-kafka-connector/resources/examples/yugabyte.sink.properties
The yugabyte.sink.properties file already has the right configuration for this sink to work correctly. You will have to change this file to include the Kafka topic and YugabyteDB table necessary for your application.
7. Produce events for Kafka
We can now produce some events into Kafka.
$ ./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test_topic
Enter the following:
{"key" : "A", "value" : 1, "ts" : 1541559411000}
{"key" : "B", "value" : 2, "ts" : 1541559412000}
{"key" : "C", "value" : 3, "ts" : 1541559413000}8. Verify events in YugabyteDB
The events above should now show up as rows in the YugabyteDB table.
cqlsh> SELECT * FROM demo.test_table;
key | value | ts -----+-------+--------------------------------- A | 1 | 2018-11-07 02:56:51.000000+0000 B | 2 | 2018-11-07 02:56:52.000000+0000 C | 3 | 2018-11-07 02:56:53.000000+0000
What’s Next?
- Using YugabyteDB at your company? Tell us about it and we’ll send you a hoodie!
- Compare YugabyteDB in depth to databases like CockroachDB, Google Cloud Spanner and MongoDB.
- Get started with YugabyteDB on macOS, Linux, Docker, and Kubernetes.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.

")
