A Yugabyte Software Engineering Intern’s Journey
February 1, 2021
Editor’s note: Yugabyte is hiring!
The Call to Adventure
My distributed SQL story begins late in 2019, back at my previous internship at a Norwegian startup called Cognite. While I was there, my team lead would always talk about how awesome distributed databases are, and also about his side project where he was building a small distributed SQL database from scratch in Rust (check it out here). His enthusiasm ended up rubbing off on me, and is a large part of why I decided to apply to Yugabyte in the first place.
My application process was fairly short, consisting of the application itself followed by a single interview with one of the software engineers on the team, Rahul. Through the interview, I got the feeling that I would be able to learn and contribute a lot during an internship, so I was very happy to accept the offer. (Rahul recalls having the same feeling, which is why Yugabyte extended an offer.)
Refusal of the Call
Unfortunately, around this time is when the pandemic struck, and so the start of my internship ended up being delayed until the end of June, as we worked out the intricacies of doing a remote internship from Canada. However, this ended up being a very exciting point to join Yugabyte as there was the recent announcement of a $30 million Series B, as well as a lot of new people joining the rapidly growing team.
And so, on a sunny Monday morning, I was thrilled to begin my Yugabyte adventure!
Meeting with the Mentor
My internship started off with a couple of starter tasks across both the core database and query layer sides of the codebase (read more about Yugabyte’s layered architecture). These tasks were extremely helpful in getting me better acquainted with not only the codebase and Yugabyte’s development cycle, but also various team members, who were all more than happy to answer any of my many questions.
During this time I also got assigned my mentor, which happened to be my interviewer Rahul due to us working in overlapping areas. He was an amazing help in answering all of my questions across all parts of the codebase, and I always looked forward to our weekly chats where we talked about work, current events, TV shows, games, and everything in between.
One of the starter tasks I worked on was prioritizing bootstrapping of transaction status tablets on tserver restarts. The main issue here was that when we would restart tservers while running transactional workloads, sometimes other tablets would start up first and then complain that they were not able to find the transaction status tablets. I was able to fix this issue by simply ensuring we start the transaction status tablets first.
Another notable starter task that I worked on was adding support for ALTER COLUMN x TYPE y for types that don’t require on-disk changes (for example, changing a column from varchar(5) to varchar(10)). This task was useful for enabling support for Django applications, as this was a common operation performed in that framework.
The Road of Trials
After I finished working on these initial tasks, I started working on some larger projects. Due to my extended internship, I ended up working on quite a few different tasks, so in order to not make this a multipart blog post, I’d like to highlight just a few.
Load Balancer Improvements
One of the main parts of the database that I worked a lot on was the load balancer. The load balancer is responsible for moving tablets around the different tablet servers in order to make sure that load is even across the cluster. Before I started working on it, the load balancer would iterate table by table, and fetch the tablet counts on each tserver for that table. It would then sort all the tservers by tablet counts, and then try to move tablets from the highest loaded tserver to the lowest loaded. Once the maximum difference between the tservers is less than 2, the load balancer stops balancing this table since any further moves would not yield any more improvements. Let’s consider an example to get a clearer picture:
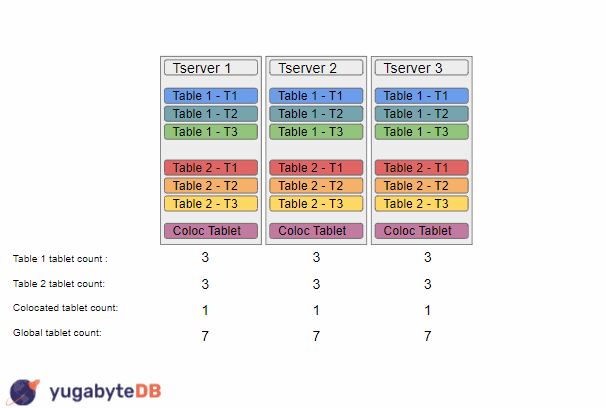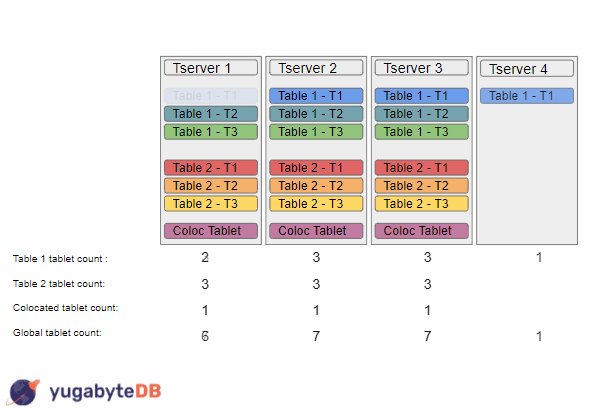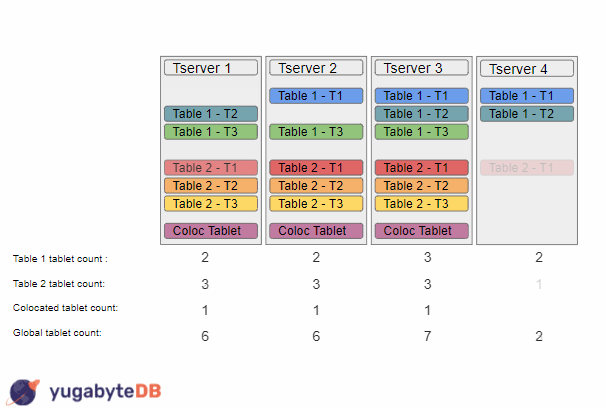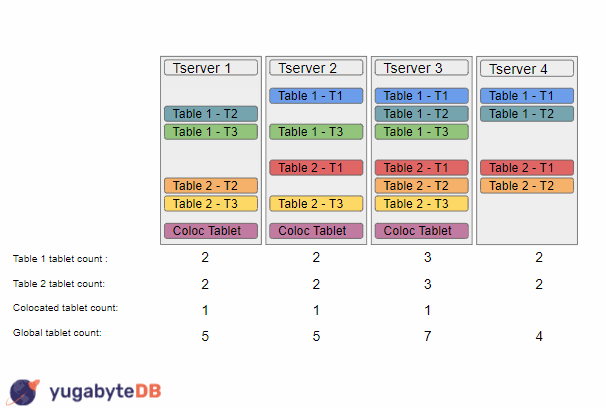
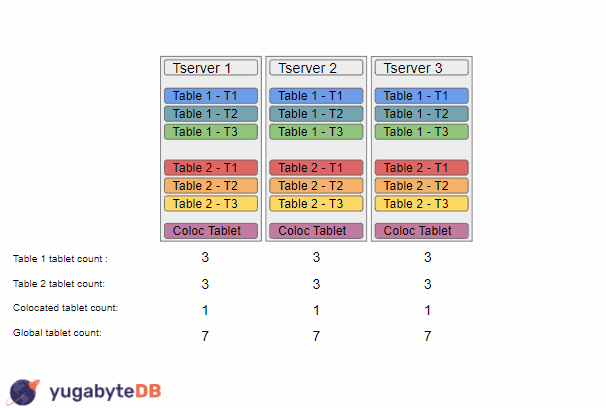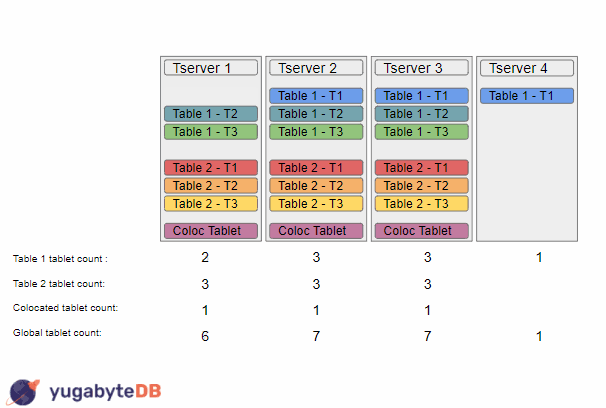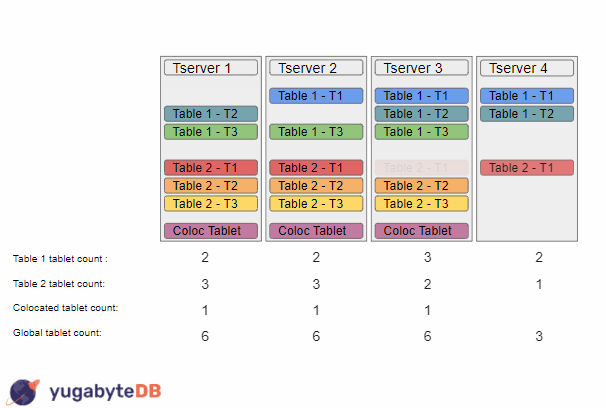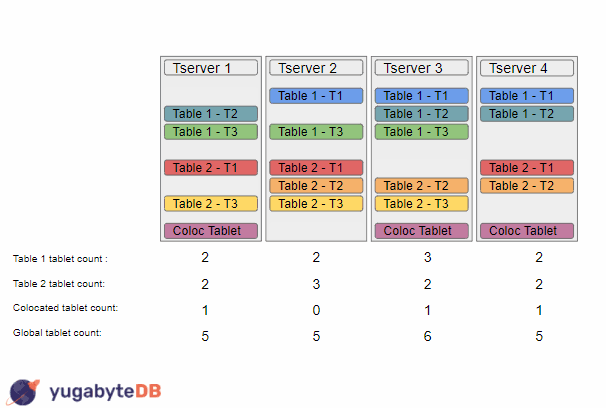
In this example, we start with 3 tservers with a replication factor of 3. We have 2 regular tables that are each split into 3 tablets, as well as a colocated tablet (which can have a number of tables all sharing a single tablet). Due to the replication factor of 3, there is only one way to balance these tablets which is to have one copy of each tablet on each tserver.
We then add a new tserver to the cluster, which causes the load balancer to start working. It will first start with Table 1, and will sort the tservers based on tablet counts, so we could end up with the sorting {TS1, TS2, TS3, TS4}. It will then move a tablet from tserver 1 to tserver 4. On the next run, the load balancer will repeat this operation, resulting in a sorting {TS2, TS3, TS1, TS4}, and so will move a tablet from tserver 2 to tserver 4. At this point the load balancer would consider this table to be balanced as the tablet counts for this table are as spread out as they could be (i.e. the max difference of tablet counts across tservers is less than 2). The load balancer would then continue and balance the next table, which could result in a similar result of a tablet from tserver 1 and tserver 2 moving to tserver 4.
At this point the load balancer would stop doing any more work as each table was individually balanced. However, if you have a sharp eye, you might notice that there is a larger issue as the overall global load is not very balanced. This problem is even more apparent for colocated tables as since they only have one tablet, the load balancer would always think that they are perfectly balanced, resulting in it never moving a colocated tablet.
In order to fix this problem, I implemented global balancing logic into the load balancer. The solution I came up with was to add a secondary sorting condition when the load balancer sorts all of the tservers. When the load balancer sorts tservers, it first looks at the table’s tablet counts, then it breaks any ties by looking at the global tablet counts for the tservers. There are of course a few other small intricacies, but this is the main idea behind my changes. With that, let’s take a look at how the load balancer today would approach the same example:
The load balancer still does the same steps for Table 1, but for Table 2, it will end up with a different sorting due to the global tablet count being used: {TS3, TS1, TS2, TS4}. Thus, it will now move a tablet from tserver 3 to tserver 4 instead. The load balancer would then come up with the sorting of {TS1, TS2, TS3, TS4} and would move a tablet from tserver 1 to tserver 4.
At this point, each table is individually sorted, however the load balancer is now able to notice that the global load is as balanced as it could be, so it takes an additional pass in order to fix that. In this example, it chooses to move a colocated tablet from tserver 2 to tserver 4, thus resulting in a state where each table is balanced and the overall global load is also balanced.
Enhancements for Colocated Tables
Another project that I worked on was adding more support for colocated databases. As explained a bit for global load balancing, colocated databases allow for multiple tables within a database to all share the same tablet. Colocated tablets help to reduce CPU, network, and disk overhead, as it helps to reduce the number of tablets.
The main project I was supposed to work on was to add colocated tablet support for xCluster replication. This would allow for a user to setup two colocated databases on two separate clusters, and then have any changes on one side magically be replicated to the other side. The main way this magic works is by capturing Write Ahead Log (WAL) changes and streaming those to the other cluster where these changes are directly applied. The big problem that I discovered while initially designing a solution is that for colocated databases, we store the Postgres table OIDs (object identifiers) as part of the document keys in order to differentiate the different tables on the tablet. The issue is that the table OIDs are almost always different on the different clusters, so directly applying WAL changes wouldn’t work.
One potential solution I came up with was to have a mapping of table OIDs and to modify the values when we were streaming the changes. The other solution was to have a way to ensure that the table OIDs on each cluster matched. We decided to go with the second solution as it was a bit simpler for this initial implementation, and since it would also allow for adding support for colocated backup/restore.
The first thing I worked on was adding a way to the YSQL syntax for creating tables with a set table OID. This required me to do a deep dive into how Postgres OIDs are generated and used, which let me learn a lot more about Postgres and the YugabyteDB query layer that reuses PostgreSQL’s native query layer. Adding support for backup/restores then mostly just consisted of getting the old tables’ OIDs and ensuring that the new tables get created with the corresponding OIDs. For adding in the xCluster replication, some additional verifications had to be done to ensure that the colocated databases had tables with the same schemas across the different clusters. However, since we made the design decision to keep table OIDs the same, I was able to reuse most of the existing code paths allowing for a fairly straightforward implementation. One of the more time consuming parts actually turned out to be writing tests, since I had to add a lot more testing support for testing YSQL with xCluster replication.
Other Projects
Of course, those were just two of the projects that I worked on during my internship. Some of the other projects I worked on include:
- Parallelizing add tablet tasks for the load balancer – this allows for the load balancer to perform more operations per run
- Better support for pending leader moves – this allows the load balancer to not get stuck on a single table while balancing
- YCQL system.partitions cache – added a background thread to refresh this cache so that queries wouldn’t be blocked on a long calculation
- More resilient master startups – added various improvements to help out in case the master crashes on its first run
- Various bug fixes across the codebase, including some very fun to debug segmentation faults
The Road Back
And as quickly as my journey began, my six months at Yugabyte came to a close. Looking back over my internship, I am really proud of all that I was able to accomplish and contribute. I got the opportunity to work on some really interesting and meaningful projects, and was able to learn a ton about distributed systems and databases along the way.
I was also able to work with an amazing team, and I’d like to give a special shoutout to Rahul, Bogdan, Mihnea, and Neha for all their help and guidance throughout my internship! Outside of work, we also had multiple gamenights which were a lot of fun – getting to kill your boss in Among Us is not something I’ve ever experienced before…
On the not so good side of things, the biggest con was definitely the pandemic. While I would have preferred to be in an office and talk to coworkers in person, working remotely turned out to not be all that bad. Everyone was still easily accessible via Slack whenever I had questions, and things like gamenights and smaller meetings still let me get to know my other team members.
All in all, this internship has been an extremely rewarding experience, and has helped me develop a stronger passion for distributed systems and databases.
If you feel inspired to pick up your sword keyboard and contribute or learn more about distributed SQL, please join the community Slack! Also feel free to reach out to me on LinkedIn if you want to ask questions or have a chat!


