Achieving AI-Driven Innovation with YugabyteDB and IBM watsonx.data
September 10, 2024
This blog explores how YugabyteDB, a cloud-native distributed SQL database, can be seamlessly integrated with watsonx.data (IBM’s Presto-based data lake) using the Postgres driver. It also details critical business use cases.
The Benefits of Integrating YugabyteDB and watsonx.data
About watsonx.data
Watsonx.data is IBM’s powerful data platform designed for real-time, scalable analytics across distributed environments. It enables fast SQL-based querying on massive datasets and integrates seamlessly with multiple data sources.
Key features:
- Presto-powered engine for high-performance distributed SQL queries
- Data federation to unify access to diverse data sources (data lakes, warehouses, etc.)
- Hybrid and multi-cloud support, allowing flexibility across on-premise and cloud environments
- Real-time analytics for low-latency data processing and insights
- Strong security and governance to ensure data privacy and compliance
- AI and machine learning integration to facilitate AI-driven insights and model development
About YugabyteDB
YugabyteDB is a high-performance, distributed SQL database designed for cloud-native applications. It combines the benefits of SQL’s relational model with the scalability and resilience of a distributed database. This makes it ideal for modern applications that require global data distribution, high availability, and strong consistency. Built on top of a highly scalable architecture, YugabyteDB can handle large amounts of data and high transaction volumes across multiple regions, all while maintaining low-latency access to data.
Key features:
- Multi-cloud: Seamlessly operate across public, private, and hybrid clouds to ensure flexibility and avoid vendor lock-in
- Geo-distribution: Globally distribute data using flexible design patterns that support synchronous or asynchronous replication
- Multi-API: Select a familiar PostgreSQL API or an enhanced Cassandra-inspired API
- Connection management: Boost connection creation and support more connections with built-in connection pooling
- Observability: Real-time access to consolidated monitoring and alerts for database clusters on any cloud
- Native security: Secure your data with end-to-end encryption, advanced authentication, and a security-first design
Together, YugabyteDB and watsonx.data deliver:
- Scalable analytics: YugabyteDB’s distributed SQL and watsonx.data’s Presto-powered data lake enables scalable analytics, ensuring efficient query performance even for large-scale workloads.
- Data consistency and integrity: YugabyteDB ensures data consistency and transactional integrity across distributed environments, crucial for industries like finance and healthcare that demand high accuracy.
- High availability and resilience: The fault-tolerant architecture of YugabyteDB combined with watsonx.data enables robust high availability and seamless resiliency, reducing the risk of operational disruptions.
- Fragmented data challenges: The integration of YugabyteDB and watsonx.data is essential for unifying fragmented data across multiple sources, enabling real-time analysis of distributed datasets.
- AI-driven decision making: watsonx.ai, in conjunction with YugabyteDB and watsonx.data, simplifies the management of vast datasets, facilitating real-time AI model training and inference for enhanced decision-making.
- Managing multi-source workloads: watsonx.data’s data federation capabilities, along with YugabyteDB’s ability to handle distributed workloads, streamline the management of complex multi-source workloads, optimizing insights and reducing costs.
- Real-time insights: Combined, YugabyteDB, watsonx.data, and watsonx.ai deliver real-time insights, AI-driven optimization, and seamless data workflows, empowering businesses to stay competitive in today’s data-driven environment.
Key Use Cases
The integration of YugabyteDB with watsonx.data and watsonx.ai offers a powerful solution for enterprises looking to unify their data ecosystems and derive actionable insights through AI. YugabyteDB’s distributed SQL capabilities, combined with the federated query engine of watsonx.data make it ideal for the following use cases.
Dynamic Pricing and Inventory Optimization
Challenge: Retailers need to adjust product prices dynamically based on factors like demand, competitor pricing, stock levels, and seasonal trends. Manually managing prices across thousands of products and stores is inefficient and can lead to missed opportunities for maximizing revenue. Similarly, maintaining optimal inventory levels across multiple locations while preventing stock-outs or overstocking is a complex logistical challenge.
Solution: By integrating YugabyteDB and watsonx.data, retailers can manage dynamic pricing and optimize inventory in real time. YugabyteDB handles the storage and ingestion of real-time sales data, competitor pricing feeds, and inventory levels. watsonx.data federates this data from internal systems (like ERP and POS systems) and external sources (like competitor pricing). AI models in watsonx.ai can then be used to adjust pricing dynamically based on market conditions, customer demand, and stock availability, as well as optimize inventory levels across stores.
Key features include:
- Real-time dynamic pricing: AI-driven models in watsonx.ai analyze real-time sales data and competitor prices to adjust product pricing instantly, maximizing revenue opportunities.
- Inventory optimization: watsonx.data consolidates data from stores, warehouses, and suppliers, allowing retailers to optimize stock levels, preventing stock-outs or overstocking.
Business Impact:
- Increased revenue: Dynamic pricing ensures that prices are competitive and aligned with demand, leading to higher sales and profit margins.
- Reduced stock-outs and overstocking: Real-time insights help retailers maintain optimal inventory levels, reducing excess stock or shortages and improving operational efficiency.
- Enhanced customer satisfaction: By ensuring the right products are in stock and priced competitively, retailers can improve customer satisfaction and loyalty.
Fraud Prevention in E-Commerce
Challenge: As e-commerce transactions grow, so do the risks of fraudulent activities like stolen credit cards, account takeovers, and refund fraud. Retailers need to identify and prevent fraudulent transactions in real time without creating friction for legitimate customers.
Solution: By leveraging YugabyteDB and watsonx.data, retailers can detect and prevent fraud in real-time. YugabyteDB stores real-time transactional data, user behavior, and payment information, while watsonx.data federates data from external fraud detection sources and internal customer profiles. AI models in watsonx.ai analyze transaction patterns, geolocation, device information, and payment behaviors to detect anomalies and flag potential fraud. Suspicious transactions can be reviewed manually or blocked automatically, while legitimate users proceed with a frictionless shopping experience.
Key features include:
- Real-time fraud detection: AI models analyze data in real-time to detect unusual patterns in transaction behavior, such as sudden large purchases, IP mismatches, or device inconsistencies.
- Multi-layered verification: Suspicious transactions can trigger step-up authentication processes (such as MFA (Multi Factor Authentication) or CAPTCHA) or manual reviews to confirm legitimacy.
Business Impact:
- Reduced financial losses: Real-time fraud detection minimizes fraudulent transactions and chargebacks, protecting the retailer’s revenue.
- Improved customer trust: By preventing fraud while ensuring a smooth shopping experience for legitimate users, retailers build trust and enhance customer loyalty.
- Operational efficiency: Automated fraud detection reduces the need for manual reviews, lowering operational costs while improving security.
How to Integrate YugabyteDB with IBM Watsonx.Data Platform Using Watsonx Infrastructure Manager
The data integration flow below shows the integration between YugabyteDB and the IBM Watsonx.Data platform.
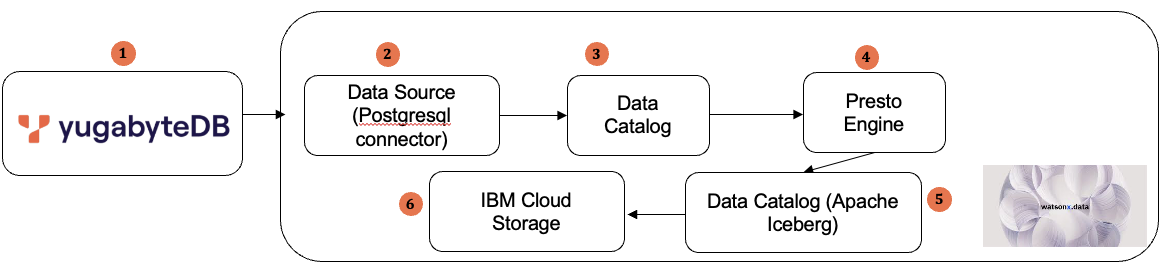
This architecture shows the integration of YugabyteDB with IBM’s watsonx.data, leveraging its Presto engine, data cataloging, and cloud storage. Here’s a simplified breakdown:
| Data flow seq # | Operations/Tasks | Component Involved |
|---|---|---|
| 1 | YugabyteDB – stores transactional data | YugabyteDB Aeon |
| 2 | Data Source – Helps to connect the data from YugabyteDB Aeon in real-time using Postgresql connector | Watsonx.Data Sources |
| 3 | Data catalog (Logical Object) needs to be associated to integrate any data source with Watsonx.Data Platform | Watsonx.Data Catalogs |
| 4 | Presto acts as a query engine that allows us to query data stored in YugabyteDB | Watsonx.Data Query Engines |
| 5 | Select Apache Iceberg as the catalog type and enter a name. Apache Iceberg is a high-performance open source format for massive analytic tables, facilitating the use of SQL tables for big data | Watsonx.Data Catalogs |
| 6 | IBM Cloud Storage is used as the lakehouse infrastructure to store the data from the respective data catalog. | Watsonx. Data Storage |
Prerequisites:
- Get your Watsonx.Data account set up in IBM Cloud. Follow the instructions HERE.
- Set up your YugabyteDB using either local or cloud cluster.
Set up Data Source, Data Catalog, and Integration with Presto Engine
YugabyteDB is connected to Watsonx.Data Infrastructure manager via a PostgreSQL connection type, enabling seamless data flow between the two systems. YugabyteDB serves as the primary source database, where transactional data is stored and managed.
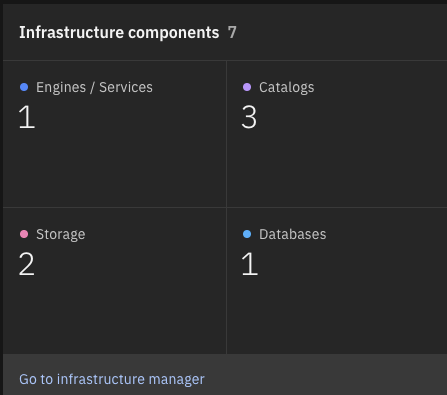
- Click ‘Go to Infrastructure Manager’ in Watsonx.Data

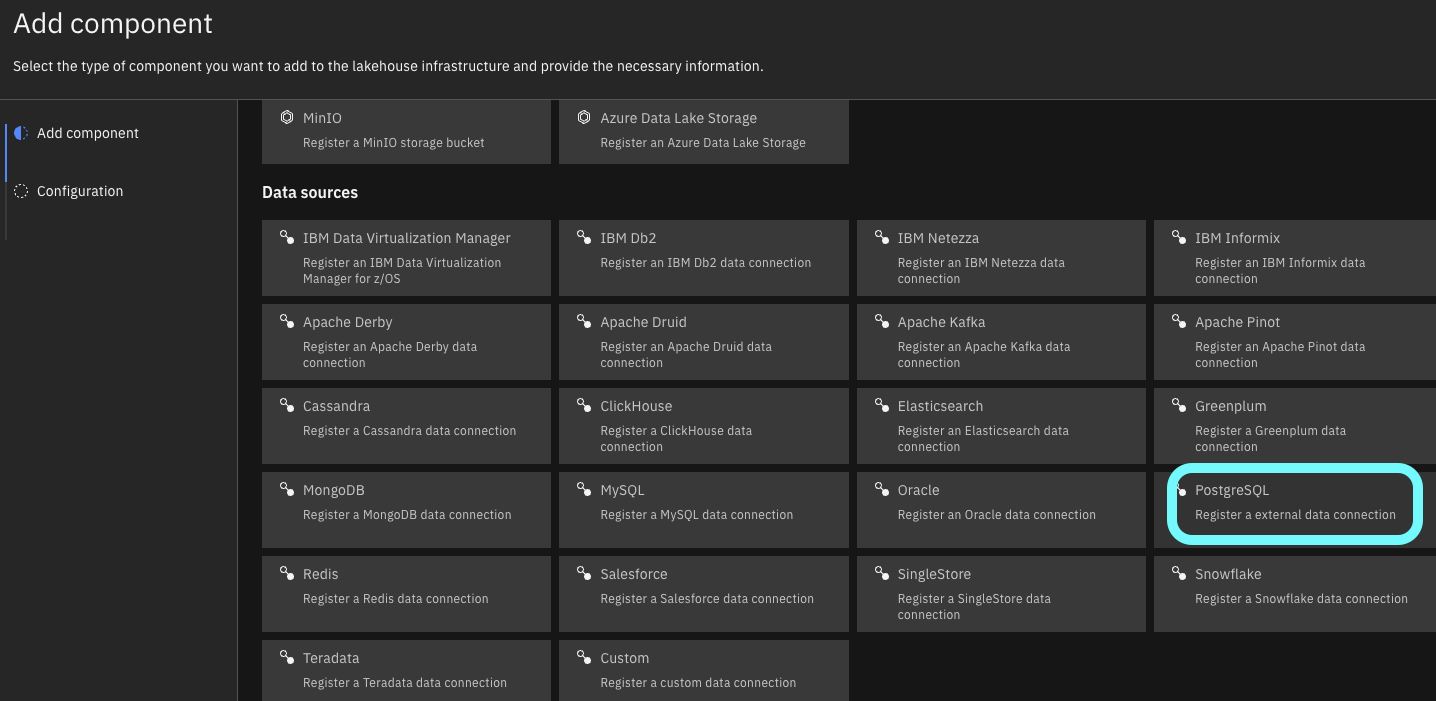
Figure 2 – Infrastructure Manager in Watsonx.Data - Click ‘Add component’ and choose the data sources as ‘PostgreSQL’
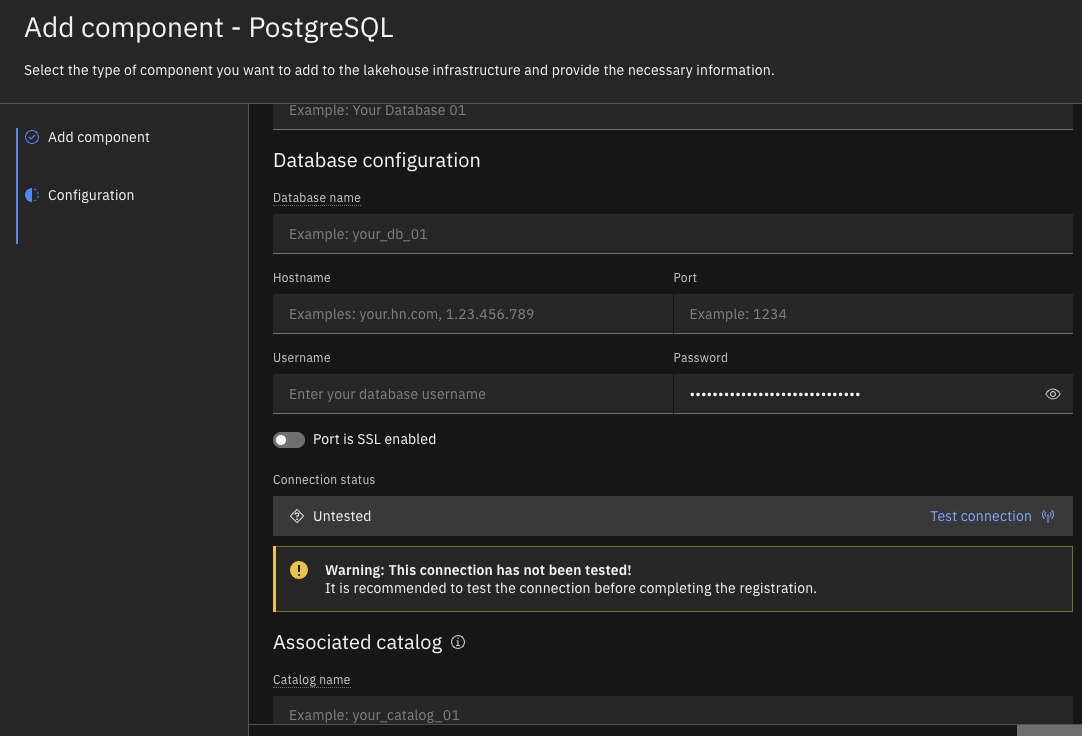
Figure 3 – Data Source – PostgreSQL - Enter the YugabyteDB credentials, In this example, we have used YugabyteDB Aeon hosted in AWS.
Figure 4 – Data Source – YugabyteDB Connection Details (using PostgreSQL) Note: SSL is enabled here and we also uploaded the root.crt.
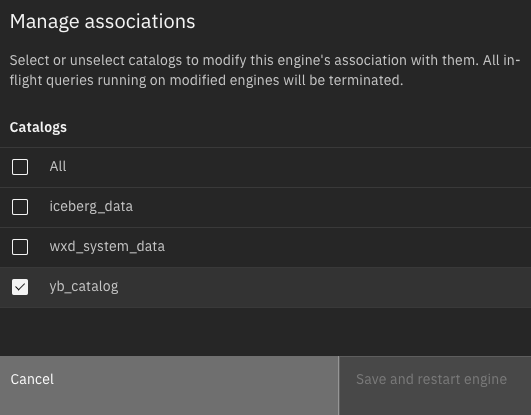
- We need to associate the catalog with Presto Engine to process the query from different catalogs (in our case YugabyteDB is one of the catalog sources).
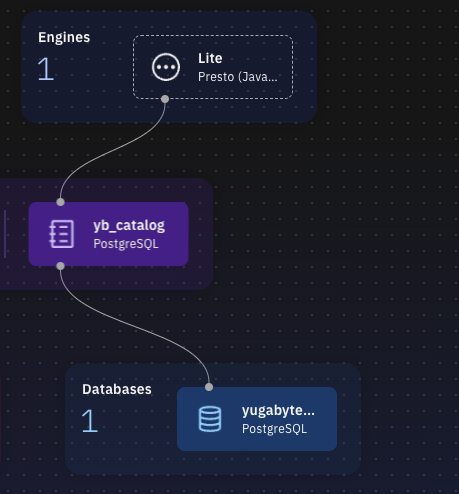
Figure 5 – Catalog Association – e.g. yb_catalog - Post association, we can see the Presto Engine is associated with catalog and data sources as shown below.
Figure 6 – Integration with Presto Engine (using YugabyteDB and its catalog) - Validate the data in Watsonx.Data Query Workspace
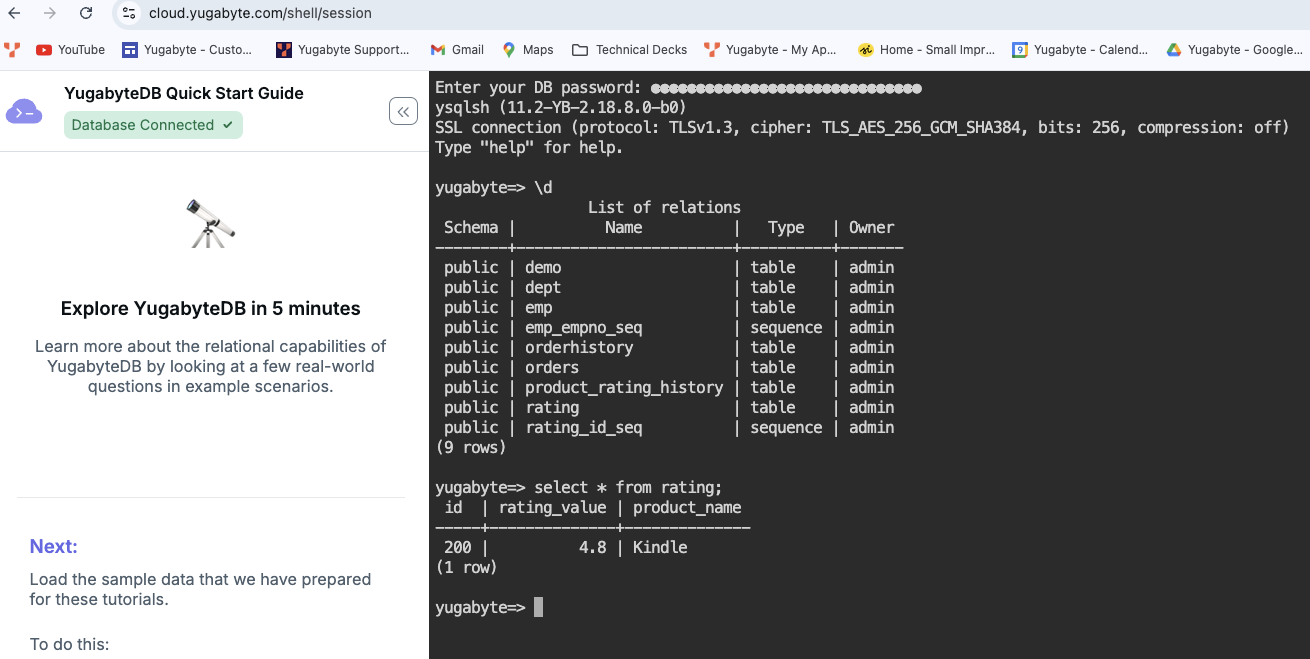
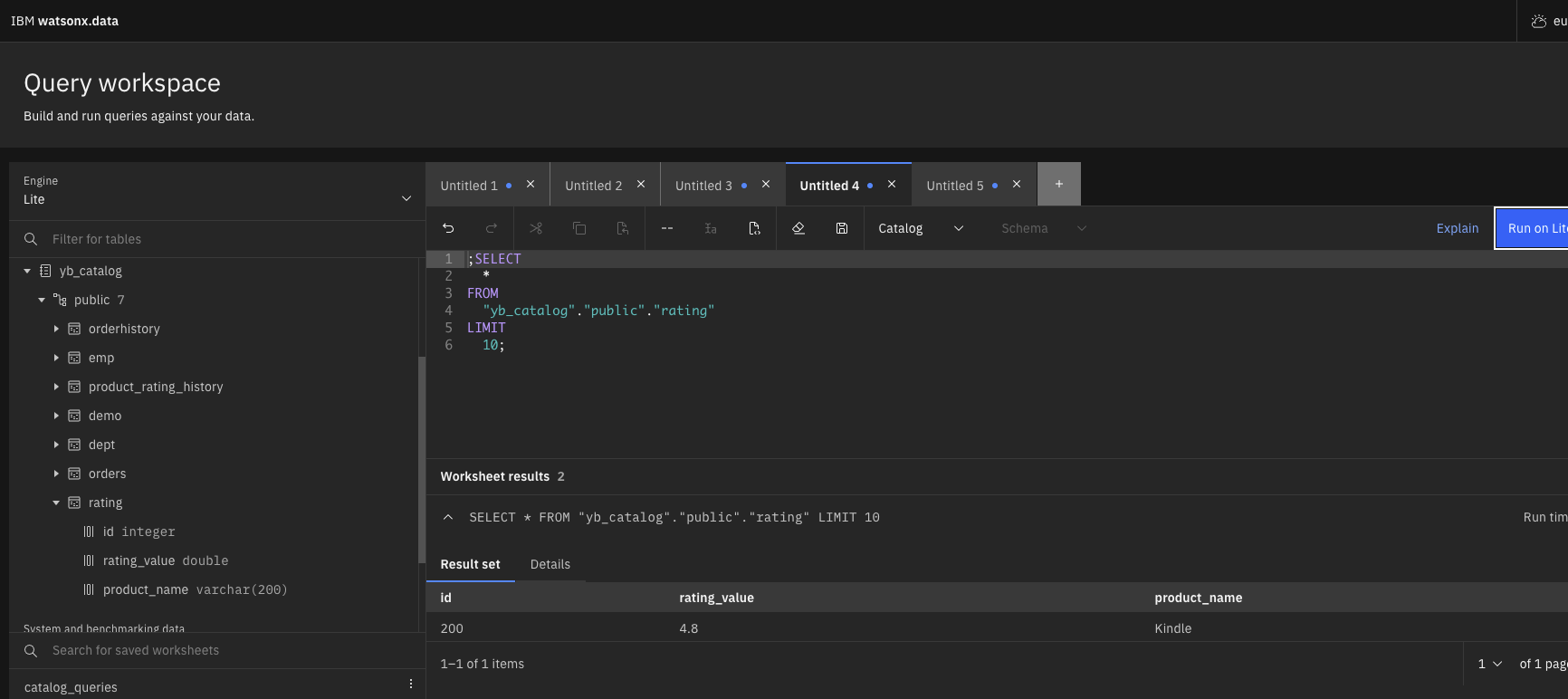
Below we show the list of tables in YugabyteDB (database) and public schema and also queried the rating table.Figure 7 – YugabyteDB Aeon – Cloud Shell (to display the objects) - Now we can query the tables that we configured with yb_catalog (in Watsonx.Data).
Figure 8 – Query Workspace – to Query the data from YugabyteDB using yb_catalog with Presto Engine
Store Data
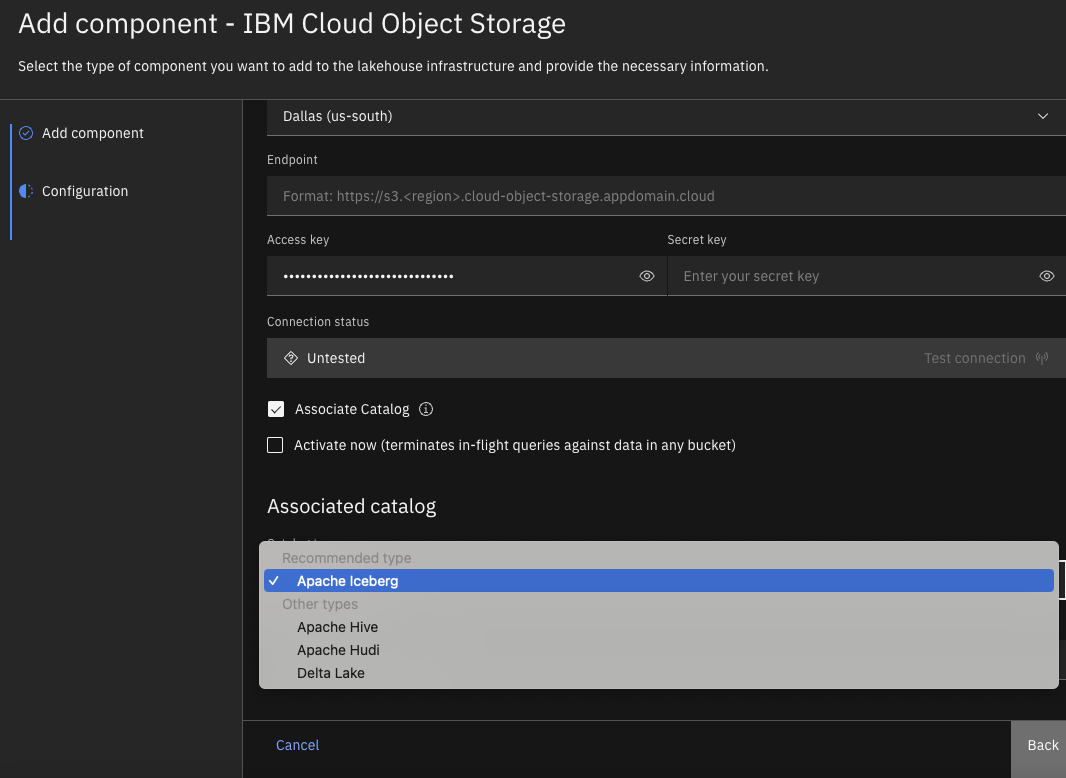
- Now, we will add a component in Infrastructure Manager of Watsonx.data to store data in the lakehouse with Apache Iceberg format. We can also store data in different formats including Apache Hive, Apache Hudi, and Delta Lake.
Figure 9 – Data Lake Storage Format – IBM Cloud Store In this example, we have selected Apache Iceberg as the storage format and also associated the catalog.
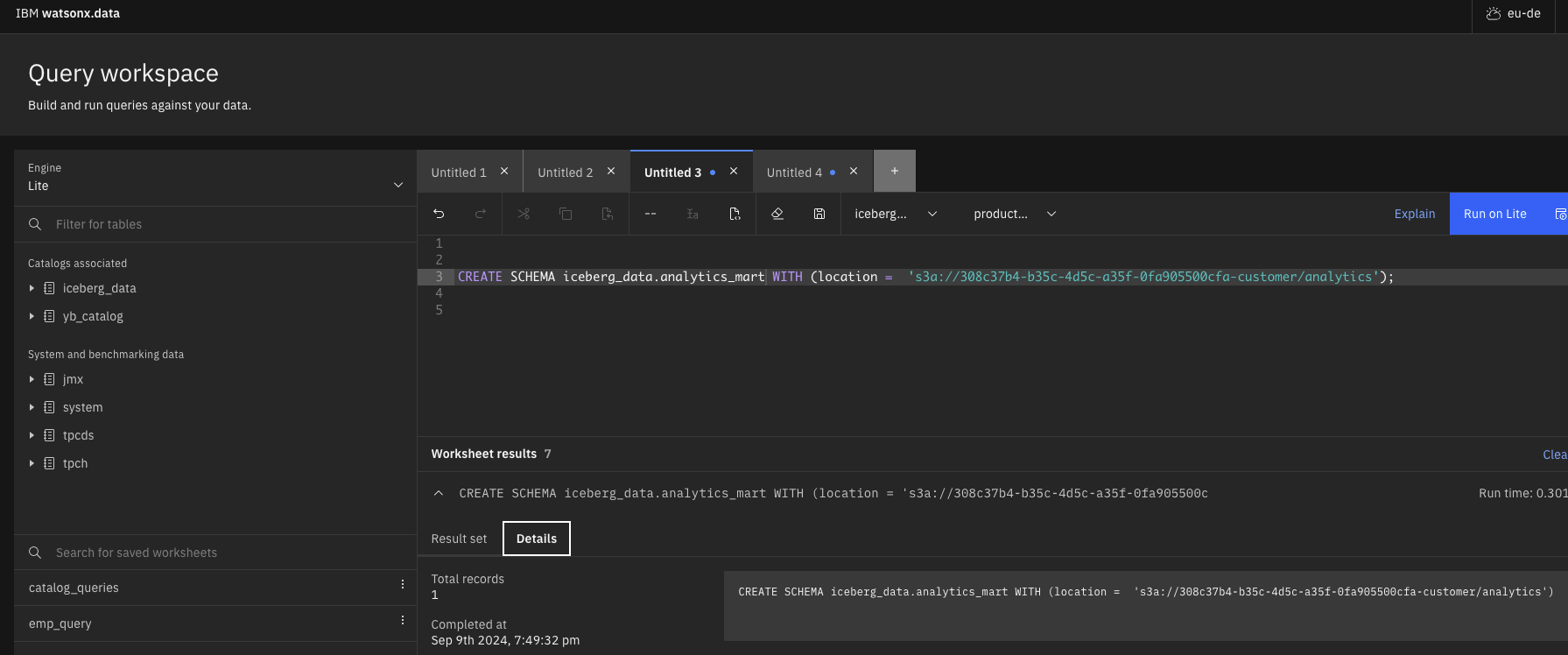
- Create Schema in Iceberg Data Catalog as shown below
Figure 10 – Query Workspace – (Creation of Schema in Data Lake using Apache Iceberg Catalog) CREATE SCHEMA iceberg_data.analytics_mart WITH (location = 's3a://308c37b4-b35c-4d5c-a35f-xxx-customer/analytics');
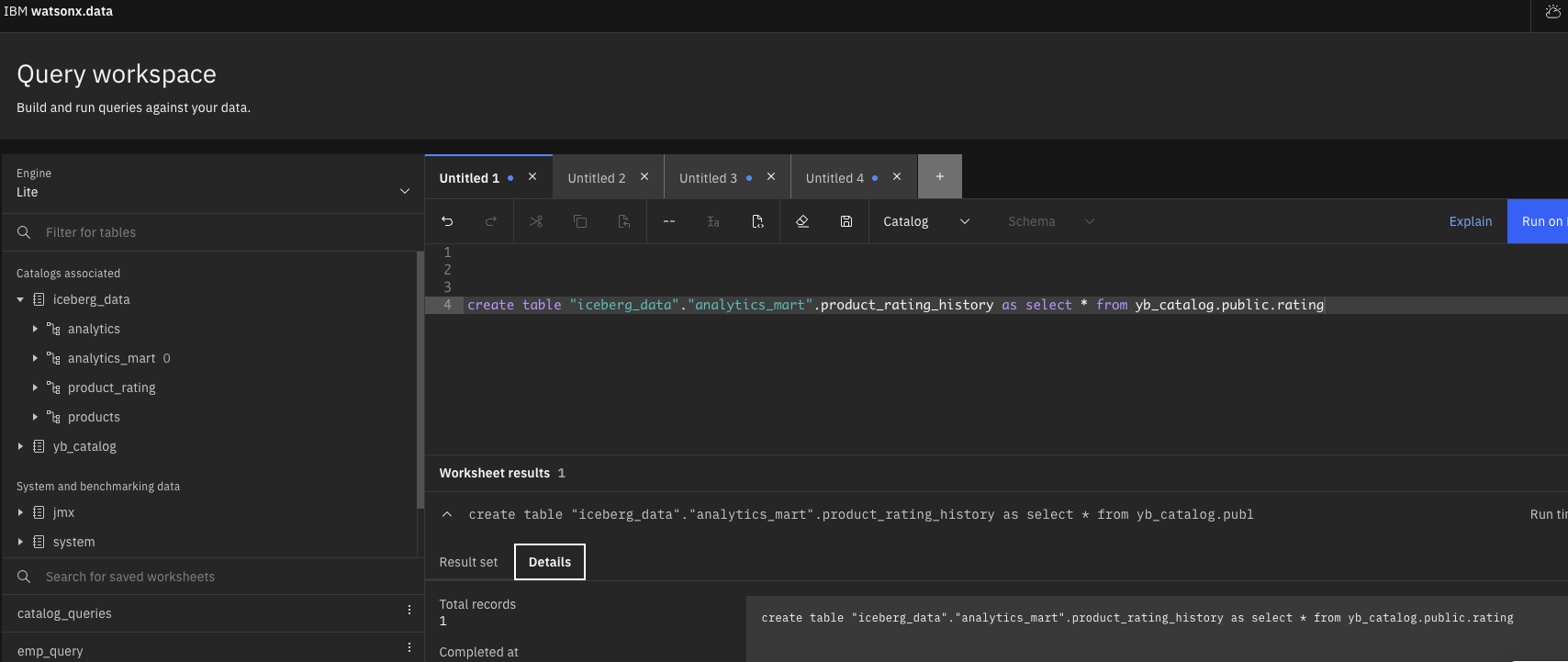
- Create tables in Data Lake using IBM Cloud Storage with Apache Iceberg format and store the data from YugabyteDB catalog (yb_catalog). It helps to integrate the data from YugabyteDB catalog to Data Lake catalog (iceberg_data) through SQL Queries.
Figure 11 – Creation of data lake table in analytics_mart schema create table "iceberg_data"."analytics_mart".product_rating_history as select * from yb_catalog.public.rating
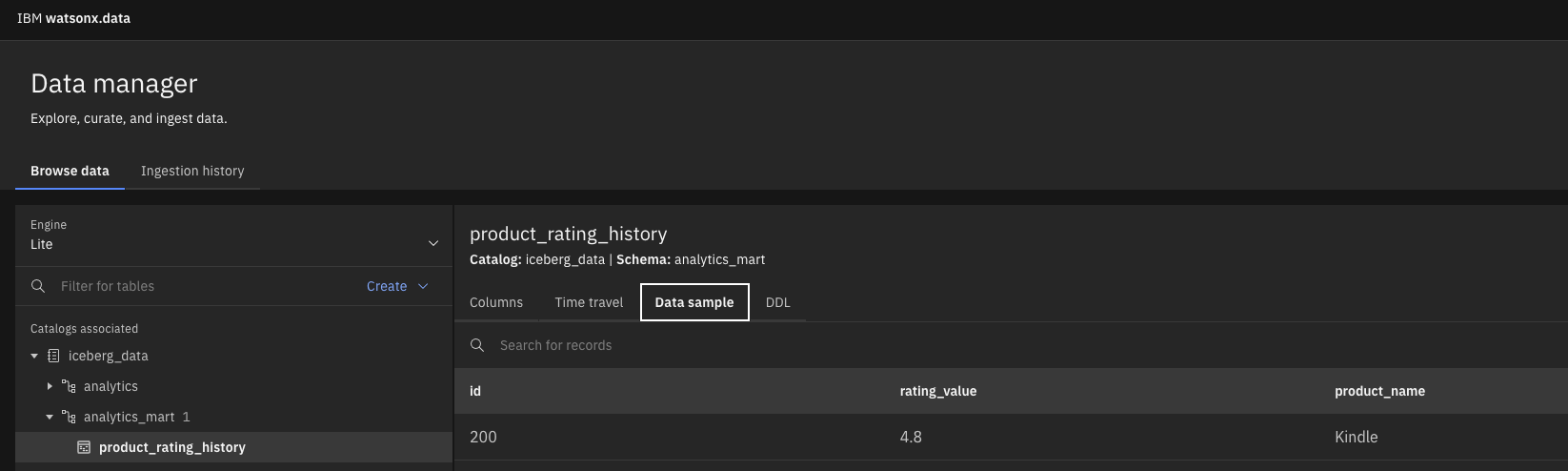
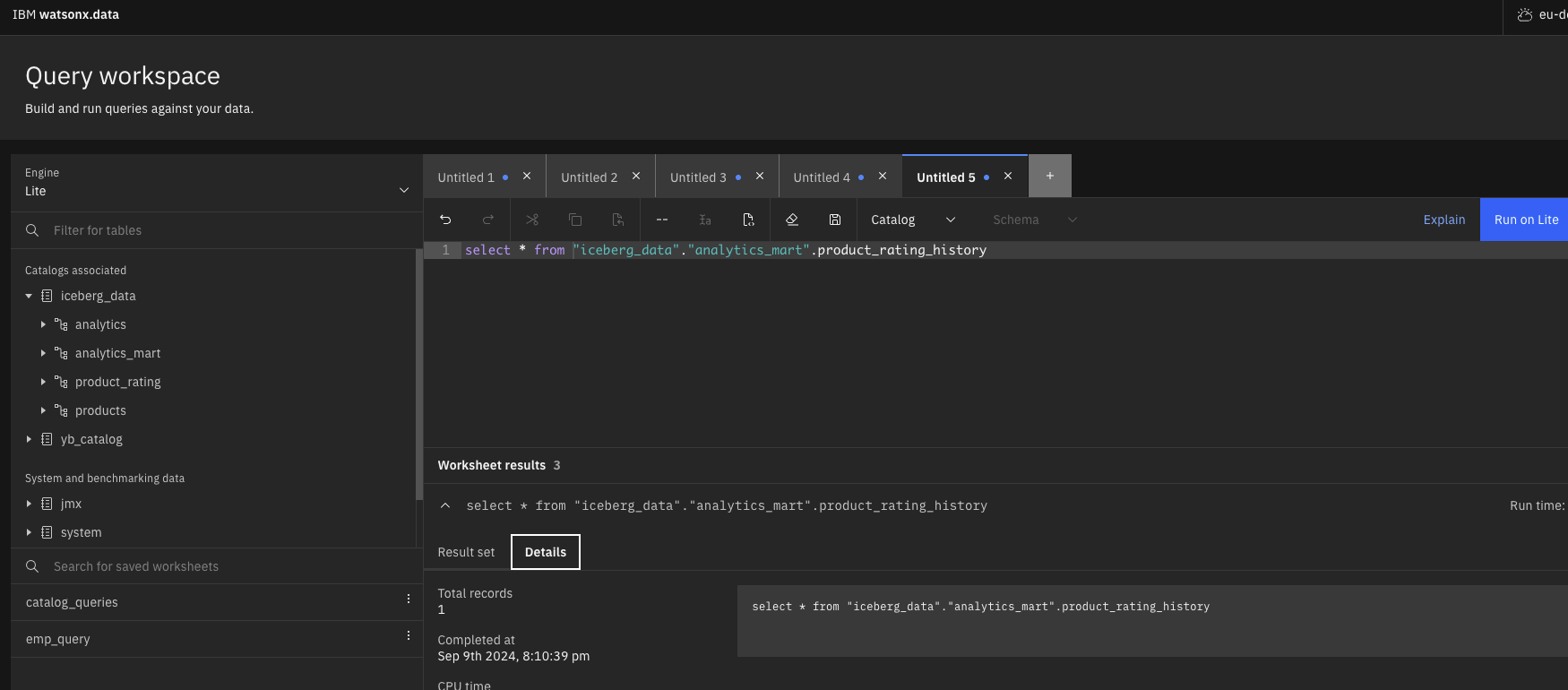
- Query the data from the data lake.
Figure 12 – Data Manager – To browse the catalog structure (e.g. product_rating_history) Figure 13 – Query Workspace to query the data from data lake table (product_rating_history)
Next Steps: To orchestrate the Watsonx.data catalog refresh and data ingestion from different sources, IBM Cloud Pak for Data provides a comprehensive platform for data analytics and AI workloads.
Orchestrating and Scheduling Data Refresh
To orchestrate and schedule data refresh in Cloud Pak for Data with watsonx.data, follow these steps:
- Set Up Data Connections:
- Establish connections to your data sources using the Data Virtualization or Data Refinery services in Cloud Pak for Data.
- Ensure that these connections are configured to access the necessary data for refresh operations.
- Create Data Pipelines:
- Use Watson Studio to create ETL (Extract, Transform, Load) pipelines. These pipelines will define the data flow from source to destination, including any necessary transformations.
- Scheduling with Watson Studio:
- Watson Studio provides built-in scheduling capabilities. You can create jobs that run your data pipelines at specified intervals.
- Define the schedule (e.g., daily, weekly) and the triggers for the data refresh process.
- Automation with Apache Airflow:
- For more complex orchestration, consider using Apache Airflow, which can be integrated with Cloud Pak for Data.
- Create DAGs (Directed Acyclic Graphs) in Airflow to define your data workflows, including dependencies, retries, and notifications.
- Monitoring and Alerts:
- Set up monitoring for your data refresh processes using Cloud Pak for Data’s built-in monitoring tools or integrate with external monitoring solutions.
- Configure alerts for failures or performance issues to ensure timely resolution.
- Data Governance and Quality Checks:
- Implement data quality checks and validations within your pipelines to ensure the accuracy and reliability of refreshed data.
- Use Cloud Pak for Data’s governance features to maintain data lineage and compliance.
The diagram below shows the IBM Cloud Pak for Data Services that we configured.
Conclusion
Integrating YugabyteDB with Watsonx.Data and Cloud Pak for Data offers a robust and scalable solution for enterprises seeking advanced data management, analytics, and AI capabilities.
By leveraging YugabyteDB’s high-performance distributed SQL database and the powerful analytics and AI capabilities of IBM’s Watsonx.Data and Cloud Pak for Data, organizations can unlock significant value from their data.


