How to Avoid Cloud Outages with YugabyteDB for Python Apps
October 26, 2022
Cloud environments provide benefits in terms of scalability and ease of use. They are easy to scale because you can add more resources when necessary. They’re easy to use and quick to build thanks to the ecosystem of cloud services and frameworks. However, in many other ways, a cloud environment is quite complex. The more complex the system, the more likely it is to fail. For example, starting in 2011, AWS has had a major outage at least once a year (not counting minor incidents). On average, it took 4+ hours to recover from those incidents. This means that your apps could also go offline for over four hours.
Cloud outages can be caused by many things, including hardware or software failures, power outages, network problems, and human error. When a cloud outage occurs, it has a significant impact on businesses that rely operationally on the cloud. For example, an e-commerce company that uses the cloud for its website will lose sales during an outage. A company that uses the cloud for email will be unable to communicate with customers or partners.
Although “zero downtime” and “always-on” may seem like ideal states, it is important to remember that all systems fail at some point. Whether it’s a small website or a large cloud hosting thousands of applications, eventually something will go wrong. Instead of fixating on unattainable standards, it’s more realistic to focus on achieving high levels of availability.
“Everything fails, all the time” this famous quote from AWS CTO, Werner Vogels sums up the simple truth—your system or application will eventually fail, and usually sooner than later. The question is how to sustain failures/outages without impacting your users, and how resilient is your system in terms of failures.
That said, what can we do to protect workloads in case of an availability zone failure? Well, with YugabyteDB, you can write application code that is resilient to outages.
YugabyteDB is a high-performance, distributed SQL database built on a scalable and fault-tolerant design. It’s architected to provide the benefits of both relational databases and NoSQL databases. It’s also designed to be highly available, scalable, and fault-tolerant. YugabyteDB handles outages gracefully. It is built on a shared-nothing architecture and uses a Raft consensus algorithm to ensure data is replicated safely across multiple nodes. In the event of a node failure, YugabyteDB can automatically fail over to another node without loss of data. It’s the perfect database for Python applications that require high performance and availability.
In this blog, we will show how YugabyteDB for Python (Django) app can achieve high availability (HA) and handle a cloud outage. To do so, we will simulate an outage in Google Cloud Platform (GCP) on one of the Yugabyte database nodes to see how YugabyteDB handles the downtime.
Note: In the example, we will be using YugabyteDB Anywhere deployed on GCP. You can achieve the same result with YugabyteDB Managed as well.
- Django is a high-level Python framework that enables rapid development of web applications. It includes a wide range of features, such as an ORM, template engine, URL routing, and authentication system.
- PubNub is a global Data Stream Network (DSN) providing real-time messaging and streaming APIs. It is the perfect choice when building applications that require real-time data streaming.
The application uses Celery task queue to ingest the real-time market data stream to YugabyteDB. Celery is distributed task queue which can process data in the background, offloading work from the application web server. It allows asynchronous task processing, especially useful when dealing with large amounts of data.
You can follow setup instructions from the project repository to run the application with YugabyteDB or check out How to Build a Scalable Streaming App with Django, Celery & YugabyteDB for a detailed explanation of the application and its setup.
Set Up YugabyteDB Anywhere
I am using YugabyteDB Anywhere for my application staging environment with three nodes deployed on GCP.
YugabyteDB Anywhere gives you the simplicity and support to deliver a database at scale, across any cloud platform or on-premise. It also has UI, which is used in a highly-available mode, allowing you to create and manage YugabyteDB clusters on one or more regions across public clouds and private on-premises data centers.
My YugabyteDB cluster has three nodes deployed on GCP under the asia-east region with three availability zones.
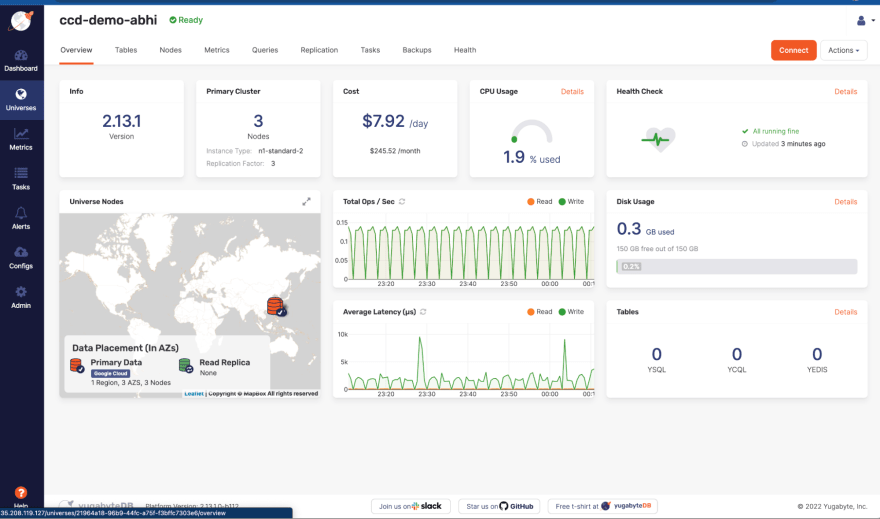
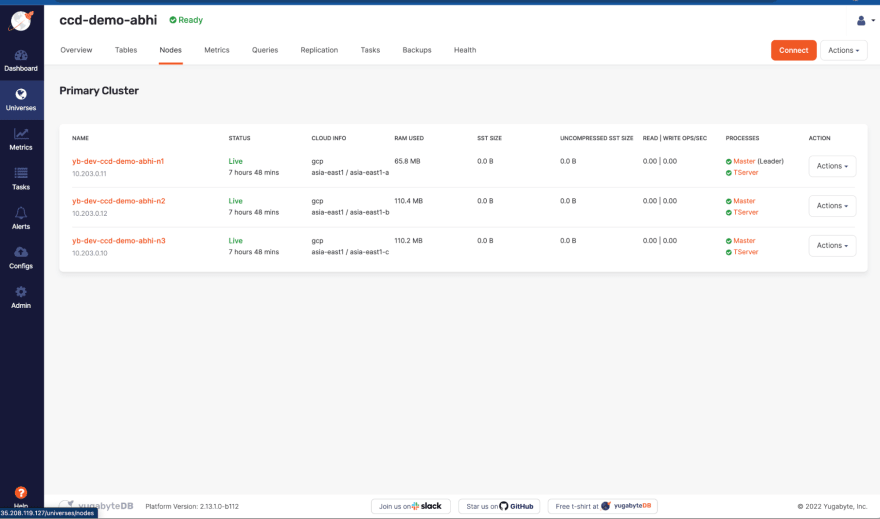
As you can see all nodes are deployed in different availability zones (asia-east1-a, asia-east1-b, asia-east1-c), depicting a multi-zone deployment pattern. The database read/write request will be distributed across these nodes. See read/write ops/sec column.

The image above shows that the YugabyteDB nodes are running on dedicated virtual machines on GCP. These nodes are created by YugabyteDB Anywhere when you set up a database cluster. You can configure a number of nodes in your cluster while setting up a cluster. In this case, it’s three.
Application Connectivity
Once the cluster is created it’s time to connect your application to the database.
YugabyteDB has its own smart database driver with additional features. You can use these drivers in your application for database connectivity rather than traditional drivers.
For Python applications, Yugabyte Psycopg2 Smart Driver is recommended since it supports auto load balancing within a cluster. It’s a fork of Psycopg2 with a cluster-aware connection load-balancing and other features on top of it.
The following is an example connection string for connecting to YugabyteDB.
conn = psycopg2.connect(dbname='yugabyte',host='localhost',port='5433',user='yugabyte',password='yugabyte',load_balance='true')
YugabyteDB smart driver also supports the popular ORM frameworks.
For the Django app, you can update the database connection string with the cluster IP address in the .env file and run the application to test.
You can also write your custom database router class to support automatic database routing amongst the node for the Django application.
Database routers let your application decide which query needs to know which database to use, it calls the base router, providing a model and a hint. You can check out this example to set up multi-node DB config in the `settings.py` of your Django application.
Now it’s showtime!
Once the application is set up with the multi-node database cluster, let’s simulate the node outage by taking one of the YugabyteDB nodes down in the GCP platform.
Stopping the node
As you can see the application is running with the 3-node cluster, with equal read/write request distribution across all the nodes.
Let’s go to the GCP compute engine service and stop one of the database nodes.
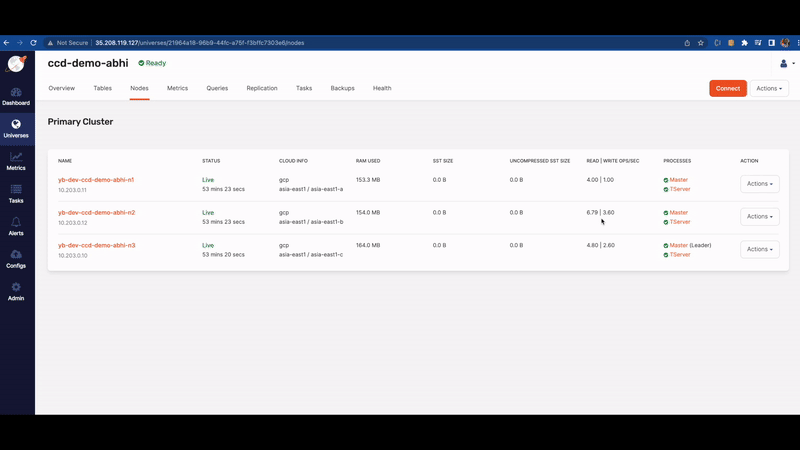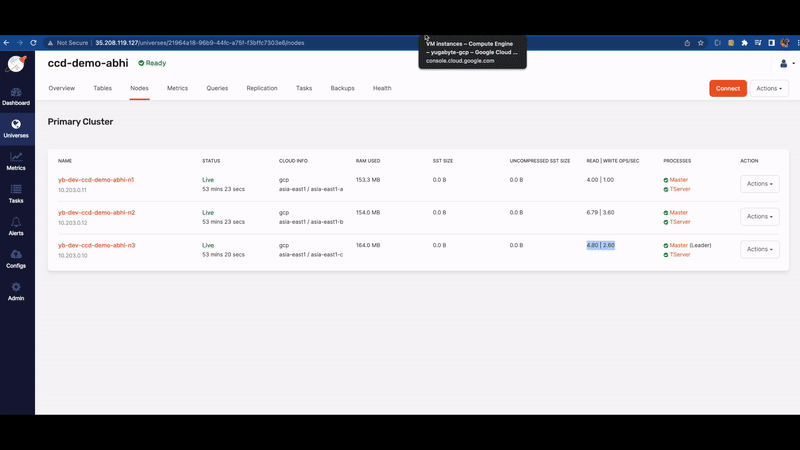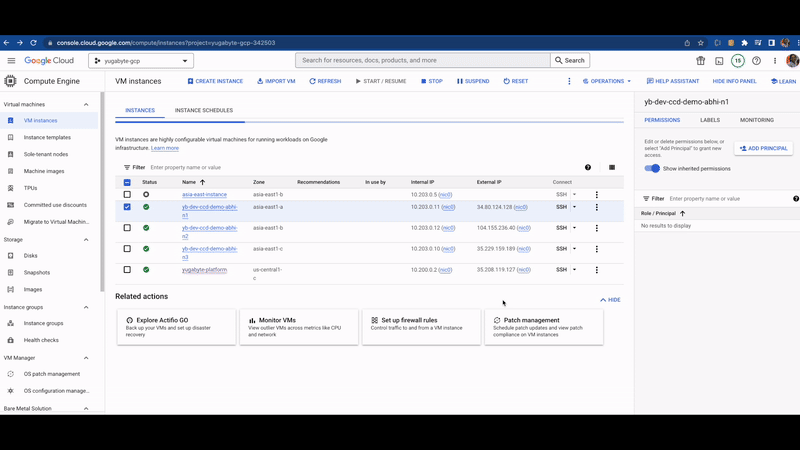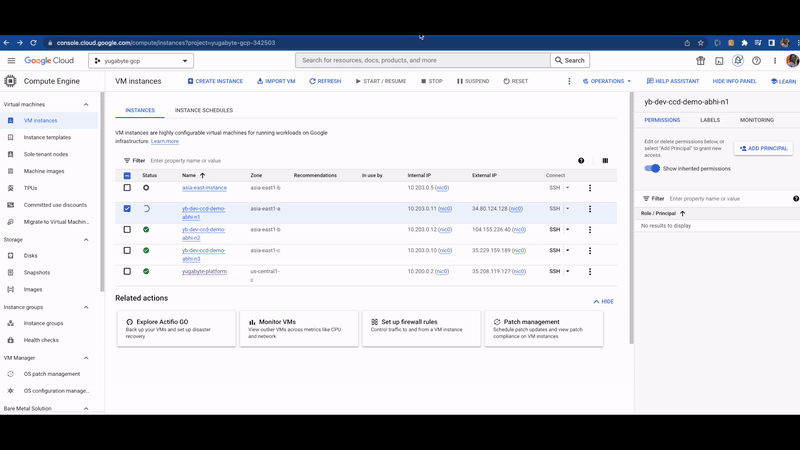
We can see in image 2 that node n1 is unreachable (as shown in YugabyteDB Anywhere UI), immediately database read/write requests have been distributed to the other 2 nodes i.e. node n2 and node n3. That’s the magic of YugabyteDB!

In this kind of outage scenario, the traditional database won’t survive and your application will face downtime. There is a chance that data will be lost as well. But YugabyteDB handles the outages gracefully by rerouting the requests to other nodes (thanks to RAFT consensus algorithm implementation) and your application still runs without any downtime, as shown below:
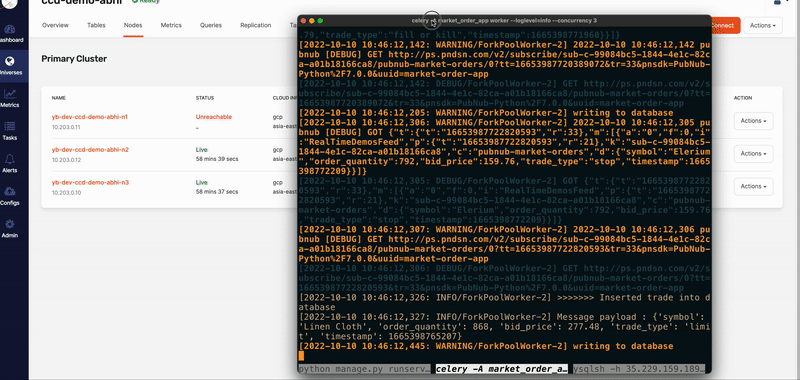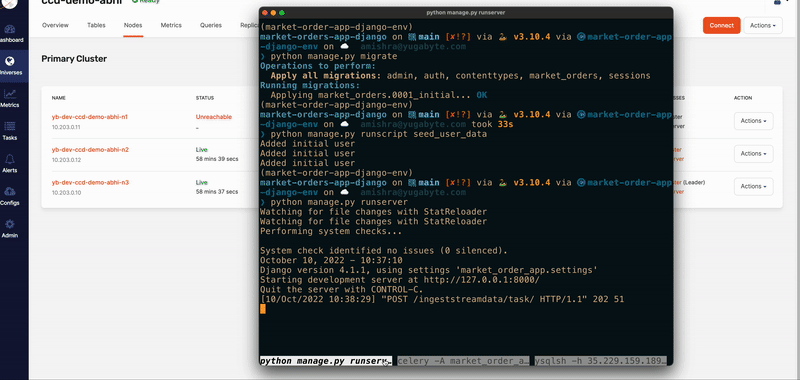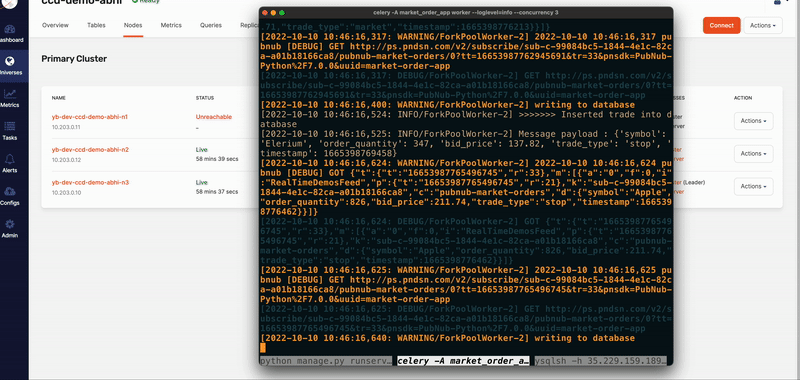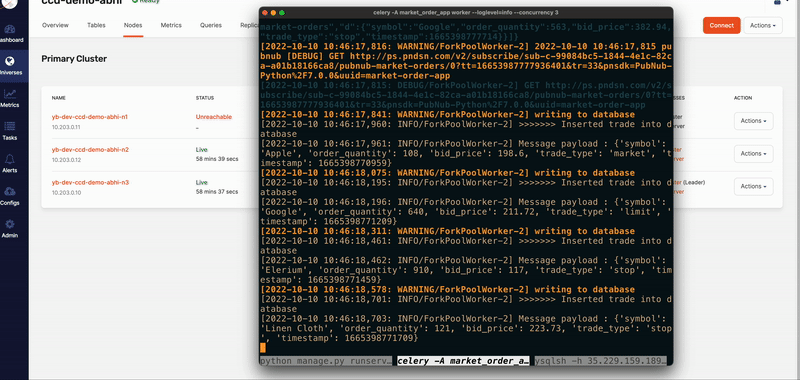
Handling outages at the application level (Django app & Celery) can be done by creating multiple instances of the app (including scaling Celery workers) and deploying it geographically across different regions with a global load balancer. When it comes to the database layer, however, YugabtyeDB is a savior! You don’t need to create multiple instances of the database; YugabtyeDB will take care of it.
Using YugabyteDB on the database layer ensures that you can handle outages and more load with scale. YugabyteDB provides PostgreSQL compatibility and all of the high availability features that are usually only available in commercial databases; they are part of the core of YugabyteDB and are fully open-source.
In one of the real-life cloud outage incidents, a Fortune 500 retailer achieved continuous availability during an outage caused by a natural disaster thanks to YugabyteDB Read more about this incident.
To know more about how YugabyteDB ensures high availability, you can check out its architecture. You can also sign up for a free instance of YuagbyteDB Managed and test it by yourself!
Happy DBing!


