A Busy Developer’s Guide to Database Storage Engines — The Basics
Learn the basics of database storage engines, incl. B-tree and LSM tree based storage engines that are popular in the context of modern distributed cloud apps

Learn the basics of database storage engines, incl. B-tree and LSM tree based storage engines that are popular in the context of modern distributed cloud apps
In the first post of this two-part series, we learned about the B-tree vs LSM approach to index management in operational databases. While the indexing algorithm plays a fundamental role in determining the type of storage engine needed, advanced considerations highlighted below are equally important to consider.
Monolithic databases, which are primarily relational/SQL in nature, support strong consistency and ACID transactions.
…

Results from the 2018 Kubernetes Application Usage Survey should put to rest concerns enterprise users have had around the viability of Docker containers and Kubernetes orchestration for running stateful services such as databases and message queues. Its exciting to see that nearly 40% of respondents are running databases (SQL and/or NoSQL) using Kubernetes. This number will continue to grow in the months ahead.
…
ACID transactions are a fundamental building block when developing business-critical, user-facing applications. They simplify the complex task of ensuring data integrity while supporting highly concurrent operations. While they are taken for granted in monolithic SQL/relational databases, distributed NoSQL/non-relational databases either forsake them completely or support only a highly restrictive single-row flavor (see sections below). This loss of ACID properties is usually justified with a gain in performance (measured in terms of low latency and/or high throughput).
…

MongoDB’s sharding and replication have improved since it was first an AP database, but it still has limitations for highly scalable and latency-sensitive apps. In this blog, the authors discuss why users switch to YugabyteDB due to distributed ACID transactions and improved scalability.

Updated April 2019.
The famed CAP Theorem has been a source of much debate among distributed systems engineers. Those of us building distributed databases are often asked how we deal with it. In this post, we dive deeper into the consistency-availability tradeoff imposed by CAP which is only applicable during failure conditions. We also highlight the lesser-known-but-equally-important consistency-latency tradeoff imposed by the PACELC Theorem that extends CAP to normal operations.
…
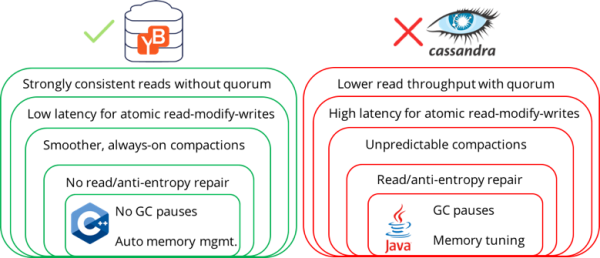
In an earlier blog on database consistency, we had a detailed discussion on the risks and challenges applications face in dealing with eventually consistent NoSQL databases. We also dispelled the myth that eventually consistent DBs perform better than strongly consistent DBs. In this blog, we will look more closely into how YugabyteDB provides strong consistency while outperforming an eventually consistent DB like Apache Cassandra. Note that YugabyteDB retains drop-in compatibility with the Cassandra Query Language (CQL) API.
…

Ever wondered which database Facebook (FB) uses to store the profiles of its 2.3B+ users? Is it SQL or NoSQL? How has FB database architecture evolved over the last 15+ years? As an engineer in FB database infrastructure team from 2007 to 2013, I had a front row seat in witnessing this evolution. There are invaluable lessons to be learned by better understanding the database evolution at the world’s largest social network,
…