Creating a Centralized Consent Database for 80M Citizens Across 100k+ Companies
April 20, 2021
At this year’s Distributed SQL Summit Asia 2021, Cetin Yalcin Gulec, Shivam Arora, and Cem Aladogan from Softtech presented the talk, “Creating a Centralized Commercial Consent Database for 80M Citizens Across 100k+ Companies.” In this post you can find a summary of the talk, some of the presentation highlights, as well as links to this talk and others from the event.
A Quick Introduction to Softtech
Cem kicked things off with a quick introduction to Softtech. Softtech is a 1,500+ person, Turkey-based technology company with offices in San Francisco, Frankfurt, Istanbul, and Shanghai. Their clients span multiple industries including banking, retail, healthcare, insurance, and logistics.
The Use Case for a New Database
Next, Cetin presented the details concerning the core requirements of their use case, which included:
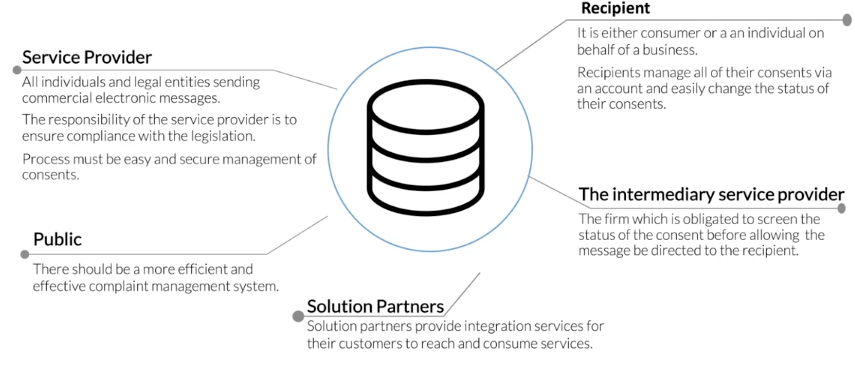
- Create a centralized database to manage the consent for over 80M “receivers” to receive messages from over 100k companies
- All these companies doing business in Turkey will need to register these consent preferences in the database
- It is the responsibility of the service providers to keep the database up to date
- Intermediary service providers have to check the database (read-only) to see if they can send an SMS or email message to the individual
- These same intermediary service providers will read this information using microservices located in their data centers
- All personal information encrypted and audited
Technical Requirements
The technical requirements for this database included:
- The data needs to be distributed across 5 datacenters
- The system must be available to encrypt and write 1 million records in 60 seconds
- The system must be available to read and decrypt 5 million records in 60 seconds

Database Requirements
With the use case and technical requirements defined, Shivam next walked us through the database requirements. These included:
- Strongly consistent yet horizontally scalable
- Support for very high throughput while delivering very low read latency
- Support for a multi-data center deployment
- Ability to support ad-hoc queries against 30TB of data
- Support for multi-region replication for a subset of data
- Open source
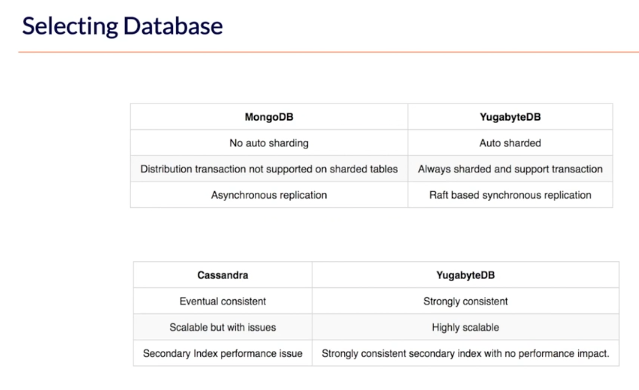
Softtech explored MongoDB and Cassandra, in addition to YugabyteDB, as possible solutions, and compared support for sharding, transactions, replication, consistency, scalability, and secondary indexes across databases.
Production Architecture
In the next portion of the talk, Shivam shared the final design of their architecture. The design could be characterized as one that is highly scalable, microservices-based, and event-driven with end-to-end monitoring built in.
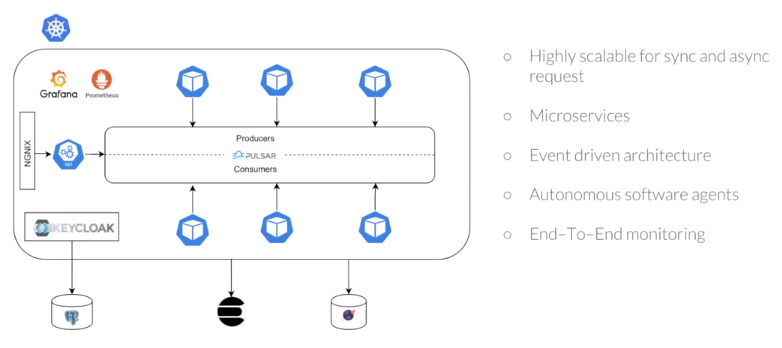
The architecture brings together a variety of components including:
- YugabyteDB
- Elasticsearch
- Keycloak
- Pulsar
- Kubernetes
- NGINX
- Grafana
- Prometheus
Shivam next described the typical API flow of the system, as well as the implementation of Yugabyte’s xCluster Asynchronous Replication which allows Softtech to selectively replicate subsets of data to the data centers of other service providers.
Technical and Business Outcomes
In the final slide of the talk, Shivam highlighted some of the technical and business outcomes they achieved with YugabyteDB.

These outcomes included:
- 500 million transactions per day
- 10 million transactions per minute at peak times
- Management of over 5 billion “consents”
- 110 million unique phone numbers stored
- 150 million unique emails stored
- 1 million users have logged in to date to manage their consent preferences
What’s Next?
To view this talk, plus all twenty-four of the talks from this year’s Distributed SQL Summit Asia event make sure to check out our video showcase for the event on our Vimeo channel.
Ready to start a conversation about how Distributed SQL can help accelerate your journey to cloud? Join us on YugabyteDB Community Slack to get the conversation started.


