YugabyteDB: The Data Backbone for Thousands of Agents
June 22, 2026
“By 2028, AI agent ecosystems will enable networks of specialized agents to dynamically collaborate across multiple applications, allowing users to achieve goals without interacting with each application individually.” (Gartner, August 2025)
Just one year later, Gartner has sharpened the forecast: by 2028, the average Fortune 500 enterprise will run over 150,000 AI agents, up from fewer than 15 today.
However, AI applications rarely fail because teams can’t get started. They fail because the tools that got them started can’t scale when they succeed.
In our 2026.1 launch post, we introduced a vision: a PostgreSQL database for every agent. This post covers what makes that vision practical.
YugabyteDB 2026.1 eliminates the growth cliff by collapsing the distance between prototype and production. Teams start on YugabyteDB AMP (Agentic Multitenant PostgreSQL), a serverless Postgres tier with scale-to-zero economics and a consolidated multi-model data stack. When workloads outgrow serverless, they transition to YugabyteDB Dedicated with no migration, no rewrite, and no change in how agents connect. The data is already on YugabyteDB, and the platform simply grows around it.
This post walks through how this works, from getting started with AMP, to scaling into Dedicated, to securing agent access across both tiers.
Why Legacy Infrastructure Fails to Meet Modern Demands
Getting a single agent to work has never been easier.
Agent SDKs and frameworks have made prototyping fast, but a production-grade agentic application needs far more from its data layer than a prototype:
- Relational storage (for operational data)
- Vector index (for retrieval)
- Graph layer (for relationship reasoning)
- Event-driven pipelines (to react to change)
- Persistent memory (so agents do not start from scratch each session)
In the prototype phase, teams stitch together lightweight, single-purpose tools: Managed Postgres here, hosted vector database there, a separate graph service, and custom ETL glue. It works and demos well, so the proof of concept gets funded.
The application succeeds, but hits a wall:
- The lightweight database underpinning it was never meant to be distributed.
- The vector store has no tenant isolation.
- The graph layer cannot share knowledge across agents without crossing security boundaries.
- The ETL pipelines become brittle and impossible to operate.
- Each element scales differently.
That cobbled-together pattern got you started, but wasn’t designed for enterprise-grade operations at scale. So, although your application is delivering value, your IT team faces a painful rebuild of the entire data infrastructure to ensure it can succeed in the long term.
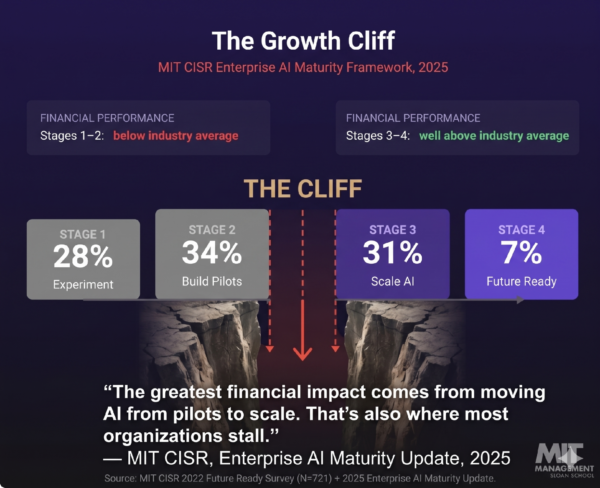
Gartner terms this “agent sprawl.” At Yugabyte, we adopted the term “The Growth Cliff.” These lightweight tools helped you clamber up the first mile, but result in a costly migration at the final peak.
One Platform: From Getting Started to Enterprise Scale
YugabyteDB has spent a decade proving itself as a distributed, enterprise-grade PostgreSQL platform. Global banks, SaaS companies, and mission-critical applications rely on it to run at scale. What 2026.1 changes is the starting point.
YugabyteDB is not a lightweight tool that will eventually need to be replaced. It is a proven distributed database that, with our new offering, meets you where you are, whether that is a single idle agent or a fleet of thousands operating across multiple regions and environments.
That continuity adds huge long-term value. Every 2026.1 feature is designed to make it simple and painless to manage and run your AI agents on YugabyteDB.
Why YugabyteDB AMP is Where You Start
The conventional wisdom says: start lightweight, migrate later if you need to. That advice made sense when “later” had a predictable growth curve and a planned migration window. In the agentic world, “later” arrives without warning, and the migration it demands lands at the worst possible moment.
But the real question is: What if starting on the right foundation didn’t require the tradeoffs that made that advice necessary in the first place?
YugabyteDB AMP is not a distributed database dressed up as a starter tier. It is Postgres.
You connect to it the way you connect to any Postgres instance. Your ORM, your driver, and your extensions work unchanged. The experience at the start is indistinguishable from the lightweight alternatives teams already reach for, with one critical difference…
The infrastructure underneath doesn’t hit a ceiling.
YugabyteDB AMP (Agentic Multitenant Postgres) starts free, charges by fractional CPU per minute as you grow, and costs virtually nothing while your agent sleeps. There are no pass-through fees or surprise bills. This is prototype-stage economics on an enterprise-grade foundation.
What makes AMP different from yet another serverless Postgres is what ships alongside it from day one. The full multi-model data stack, already consolidated:
- YugabyteDB Vector (GA) – embeddings beside operational data, ACID-consistent, no separate store to sync.
- YugabyteDB RAG (EA) – source registration, chunking, and embedding generation, all in SQL. Pulls from S3, URLs, and NFS across JSON, CSV, Markdown, and PDF. Each tenant gets its own isolated pipeline namespace. No external ETL, no separate embedding service.
- YugabyteDB MAGE (TP) – a multi-tenant graph engine based on Apache AGE. Agents get a shared graph layer where relationships stay within or cross tenant boundaries as needed. Combined with vector search, MAGE powers GraphRAG: relationship-aware retrieval that vector search alone cannot match.
When Your Agents Outgrow Serverless
Success fundamentally alters your infrastructure requirements. An agent that began its life as a simple prototype may suddenly find itself processing sustained production traffic across multiple regions. At this stage, the workload is no longer bursty or idle; it has become business-critical and must coexist with hundreds of other agents sharing the same vital resources.
YugabyteDB Dedicated is designed for this exact moment, transforming the strategic value of starting on AMP into a concrete operational advantage.
The transition is completely seamless, requiring no painful migrations, data movement, or complex application rewrites.
YugabyteDB simply provisions the full power of a distributed database beneath your existing workload: providing geo-distribution, automated failover, and linear horizontal scaling. While the infrastructure expands to meet demand, your agents remain unaware of the change, and your data stays exactly where it belongs.
Dedicated adds the controls that large-scale agent fleets require.
Resource Governance enables you to establish caps on CPU, RAM, and storage per database. This ensures that a single agent performing heavy embedding tasks cannot starve the others sharing the universe. These governance tools maintain cost predictability while still allowing workloads to burst to full capacity when required. You can manage your entire fleet as a single operation, using built-in quotas to prevent runaway workloads from threatening your overall capacity.
In the lightweight world, this is the moment you hit the Growth Cliff and face a total rebuild. On YugabyteDB, it is simply a configuration change.
Secure Agent Access Across Both Tiers
Regardless of whether your agents reside on AMP or migrate to Dedicated, they interact through a unified, hardened interface.
Every deployment includes the YugabyteDB MCP Server, granting agents structured entry to any database in the ecosystem.
The second iteration introduces the robust security that enterprise fleets demand: OIDC authentication that aligns an agent’s identity with specific database roles. This ensures every query runs with only the permissions granted, no more, no less. To prevent accidents, write-enabled tools remain locked until an administrator intervenes, with strict guardrails on row counts and mandatory WHERE clauses for any sensitive or destructive operations.
The outcome is a system in which agents access critical data under human supervision, ensuring that every action is mapped to a verified identity.
Empowering Agents to Scale Effortlessly
On AMP, your agents use standard PostgreSQL, and it simply works. There are no specialized patterns to master and no steep learning curves, so your current Postgres expertise translates perfectly.
However, as workloads transition to Dedicated, distributed execution brings unique requirements that AMP endpoints aren’t exposed to, such as hash-distributed keys and complex transaction handling across multiple nodes.
We evaluated this performance gap through 350+ evaluations across 17 model configurations. Without proper guidance, AI coding agents frequently struggle with distributed anti-patterns. By introducing a YugabyteDB skill file, a context layer that educates the agent on distributed-native logic, we saw up to 57% improvement in anti-pattern avoidance.
Our subsequent research confirmed that the best results come from a dual approach: a foundation of distributed SQL basics combined with project-specific tuning for your unique schema.
This mirrors the seamless AMP-to-Dedicated evolution. You start on AMP with zero friction and no specialized skills required. As you move to the Dedicated scale, the skill file empowers your agents to master distributed patterns while the data remains securely on YugabyteDB. The infrastructure scales, and your application layer follows suit.
What This Means in Practice
Consider the lifecycle of an agent workload:
- A team builds an agent, connects it to internal documents, and runs it on YugabyteDB AMP. The agent is idle 90% of the time, and scale-to-zero means the team pays nearly nothing.
- Vector search, RAG, and graph reasoning are all available natively. No side stack of third-party services to manage.
- The agent works. Adoption spreads. One team’s experiment becomes a department-wide tool, then a company-wide platform handling thousands of queries a day across three regions.
On a lightweight stack, this is the moment of crisis. The prototype infrastructure cannot handle the load, the isolation requirements, or the compliance demands. The team is rewarded for success with months of re-architecture.
On YugabyteDB, the team transitions to Dedicated. Resource governance protects co-located workloads. Geo-distribution brings data closer to each region. The agent keeps running, and the data stays in place.
The team that built the agent never has to become a database migration team!
Get Started Today
YugabyteDB 2026.1 will be available soon!
Find out more:
- Read the YugabyteDB 2026.1 launch announcement
- Explore YugabyteDB 2026.1 docs (available soon)
- Try fully-managed YugabyteDB Aeon free
- Learn more about Meko, the agent-native data infrastructure for collective memory, shared knowledge, and decision traces


