Distributed SQL vs. NewSQL
January 28, 2020
Our previous post in this series “What is Distributed SQL?” highlights the common architectural principles as well as the business benefits of distributed SQL databases. In this post, we compare distributed SQL databases against NewSQL databases so that we can better understand their differences.
Before we dive into NewSQL, it is important to understand why NoSQL databases like MongoDB and Apache Cassandra came into prominence in the mid-to-late 2000s. They too were originally positioned as alternatives to SQL databases but fell short of their goal. SQL databases were monolithic at that time and the distributed nature of NoSQL was attractive to applications looking for scalability and resilience. Since the various NoSQL languages focused on single-row (aka key-value) data models and gave up on the relational/multi-row constructs of the SQL language, these databases could no longer be categorized as “SQL” databases. Hence, the name “NoSQL” was adopted. NoSQL was originally coined as “No support for SQL” but later on evolved to “Not only SQL” once users realized that NoSQL databases have to coexist alongside the SQL databases rather than replace them entirely. The primary reason for continued need of SQL databases was the need for relational data modeling with support for single-row consistency as well as multi-row ACID transactions. Eventually-consistent NoSQL databases follow the Available and Partition-tolerant (AP) side of the CAP Theorem and hence are architecturally unfit for serving such consistency-first needs.
Given the above limitations with NoSQL, large-scale OLTP workloads where both data correctness and scalability were important continued to suffer even after the advent of NoSQL. NewSQL databases were introduced starting early 2010s to solve this problem. 451 Research’s Matthew Aslett coined the term in 2011 to categorize these new “scalable” SQL databases. NewSQL database systems come in two distinct flavors.
- The first flavor simply provides an automated data sharding layer on top of multiple independent instances of monolithic SQL databases. For example, Vitess addresses this problem in the context of MySQL while Citus (aka Azure DB for PostgreSQL – Hyperscale) does the same for PostgreSQL. Since each independent instance is still the same old monolithic database, fundamental problems such as native failover/repair and distributed ACID transactions that span shards either remain impossible or perform poorly for real-world use cases. Worst of all, developers lose the agility that comes with interacting with a single logical SQL database.
- The second flavor includes the likes of NuoDB, VoltDB and Clustrix that built new distributed storage engines with the goal of keeping the single logical SQL database concept intact.
The next section evaluates both these flavors of NewSQL using the distributed SQL criteria we previously established in the “What is Distributed SQL?” post.
Evaluating NewSQL Databases Using Distributed SQL Criteria
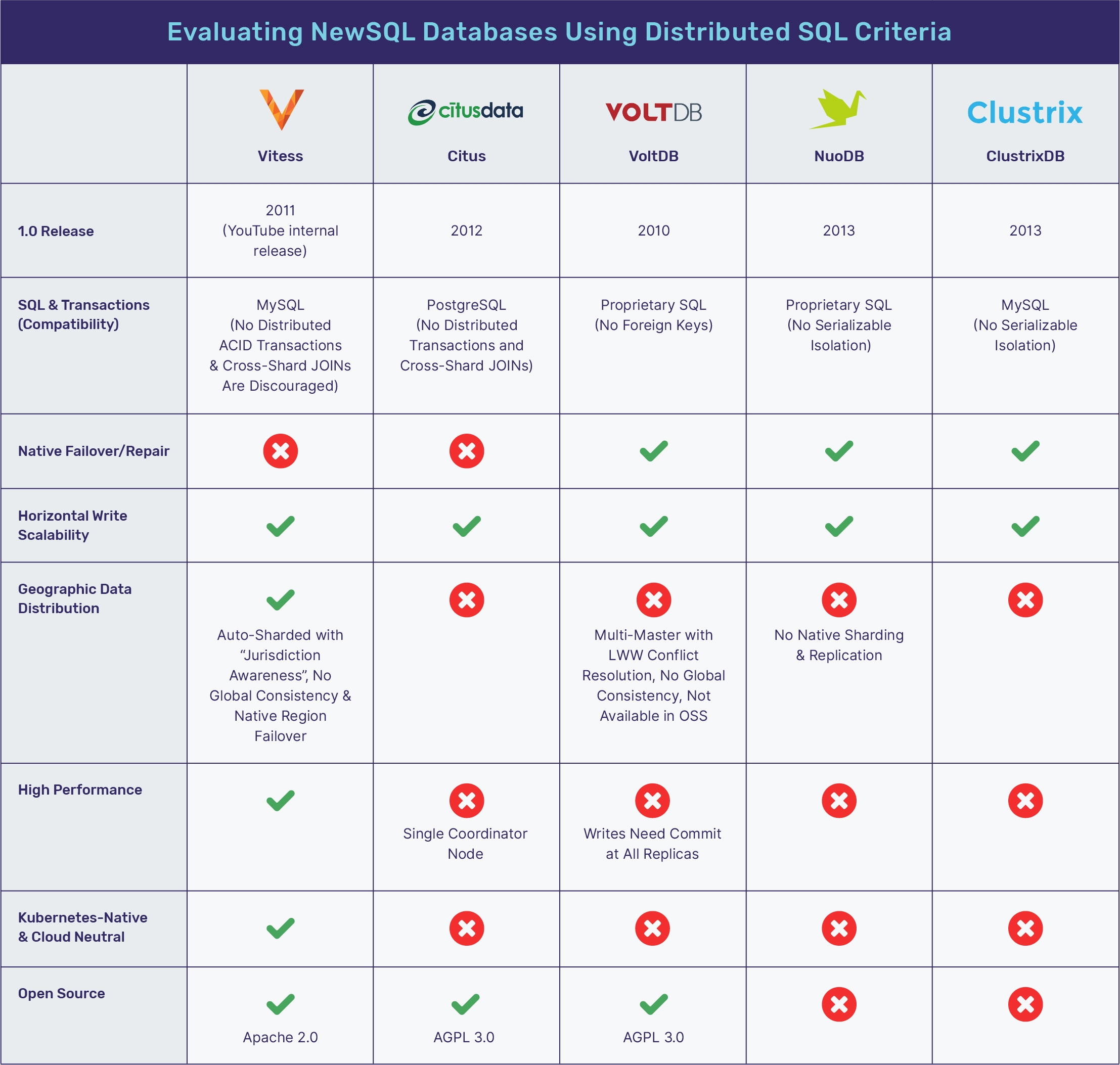
Vitess
Vitess is an automated sharding solution for MySQL. Each MySQL instance acts as a shard of the overall database. It uses etcd, a separate strongly consistent key-value store, to store shard location metadata such as which shard is located on which instance. Vitess uses vtgate, a special set of coordinator nodes, to accept application client queries and then route them to the appropriate shard based on the mapping stored in etcd. Each of these instances uses standard MySQL master-slave replication to account for high availability.
SQL features that access multiple rows of data spread across multiple shards are discouraged in Vitess. Examples of such features include global secondary indexes (that require distributed ACID transactions) and cross-shard JOINs. Note that true distributed ACID transactions are not even supported since no isolation guarantee can be provided for cross-shard transactions. This means a Vitess cluster loses the notion of a single logical SQL database in practice. Application developers have to be acutely aware of their sharding mechanism and account for this while designing their schema as well as while executing queries.
Citus
In simplest terms, Citus is the PostgreSQL equivalent of Vitess. Packaged as an extension to the monolithic PostgreSQL DB, Citus essentially adds horizontal write scalability to PostgreSQL deployments through transparent sharding. The installation begins with, say, n nodes of PostgreSQL with each node also having the Citus extension. Thereafter only 1 of these n nodes becomes the Citus coordinator node and the remaining n-1 nodes become the Citus worker nodes. Applications interact only with the coordinator node and are unaware of the existence of the worker nodes. The replication architecture to ensure high availability under failures is still master-slave (based on Postgres standard streaming replication). There are obvious performance and availability bottlenecks arising from a single coordinator node architecture. Slowdown at the coordinator node slows down the entire cluster even though the worker nodes themselves may all be functioning normally. Outages at the coordinator node makes the entire cluster unavailable. The fact that worker nodes are not able to interact with client applications directly means that there is no way to make client drivers smart by caching the current shard metadata.
Citus was acquired by Microsoft in 2019 and is now also offered as the Hyperscale option of Microsoft Azure Database for PostgreSQL. While such a managed service can automate some of the tedious replication configuration tasks, it cannot fundamentally alter the core architecture of the database.
VoltDB
VoltDB is an auto-sharded distributed database with a proprietary SQL that has no support for foreign keys. Intra-cluster replication is based on the K-safety algorithm where K refers to the number of additional copies of data stored for each shard. This means the K=2 configuration maps to the default Replication Factor 3 approach of distributed SQL databases like Google Spanner and YugabyteDB.
In VoltDB, all replicas for a given shard are updated synchronously by the client application. This is where VoltDB pays a significant performance penalty for write operations when compared with Raft/Paxos-powered distributed SQL databases. Distributed consensus protocols like Raft and Paxos require writes to be sent to all replicas but commit as soon as a majority of replicas have acknowledged the request. Waiting for all replicas to respond is not necessary since the consensus can be established with a majority. Additionally, VoltDB does not detect network partitions by default and requires a special network-fault-protection mode to be configured. When a node of the cluster gets partitioned, the network-fault-protection mode comes into play. It negatively impacts cluster performance by increasing cluster recovery time for not only accepting writes on the shards whose replica was lost in the node partition but also for repopulating the data on the partitioned node when it joins back the cluster.
Multi-datacenter globally-consistent clusters are not even possible in the VoltDB architecture. And finally, cross-datacenter replication using multi-master architecture is not available in the open source edition since it is reserved only for the proprietary commercial edition.
NuoDB
NuoDB is a proprietary NewSQL database built on a complex architecture of multiple moving parts such as Brokers, Transaction Engines and Storage Managers. It claims to be an elastic, ANSI-SQL compliant database that does not require any form of sharding or strongly-consistent replication altogether. This essentially means that every node of the database cluster stores all the data, leading to significant resource wastage. Additionally, fault-tolerance guarantees have to be handled either at the storage layer (which is impossible in the shared-nothing public cloud) or at the application layer (by ensuring that the multiple copies of the same database are run on multiple hosts). Neither of these options is practical in the cloud-native era we live in today. Additionally, lack of serializable isolation means that the ACID guarantees of transaction processing are significantly weaker than modern distributed SQL databases. The Jepsen analysis of NuoDB from 2013 still stands since the core architecture remains unchanged. It shows that NuoDB is prone to losing data as well as experiencing race conditions and prolonged downtime in the presence of failures.
ClustrixDB
Clustrix, started in 2006, was one of the earliest attempts at building a scale-out SQL database. Unfortunately, it had a tortuous history before getting acquired by MariaDB in 2018. The first product that shipped was a database hardware appliance in 2010 that could be deployed only in a single private datacenter. The appliance used specialized hardware and could not get adoption beyond a dozen deployments. With public cloud and commodity hardware gaining steam, Clustrix pivoted to a MySQL-compatible software-only solution in 2013. However, it continued to rely on a very reliable network for sharding, replication and failover operations. This meant adoption in the public cloud era lagged especially in the context of multi-zone and multi-region deployments.
Summary
NewSQL databases were first created in early 2010s to solve the write scalability challenge associated with monolithic SQL databases. They allowed multiple nodes to be used in the context of a SQL database without making any significant enhancements to the replication architecture. The cloud was still at its infancy at that time so this strategy worked for a few years. However as multi-zone, multi-region and multi-cloud cloud deployments became the standard for modern applications, these databases fell behind in developer adoption. On the other hand, distributed SQL databases like Google Spanner and YugabyteDB are built ground-up to exploit the full elasticity of the cloud and are also designed to work on inherently unreliable infrastructure.


