Five Benefits to Running a Distributed SQL Database in Kubernetes
April 7, 2022
A distributed SQL database is a single logical relational database deployed on a cluster of servers. The database automatically replicates and distributes data across multiple servers. These databases are strongly consistent and support consistency across availability and geographic zones in the cloud.
At a minimum, a distributed SQL database has the following characteristics:
- A SQL API for accessing and manipulating data and objects
- Automatic distribution of data across nodes in a cluster
- Automatic replication of data in a strongly consistent manner
- Support for distributed query execution so clients do not need to know about the underlying distribution of data
- Support for distributed ACID transactions
But should you run a distributed SQL database in Kubernetes? In this post, we examine the five reasons why it’s worth it for your company.
1. Better resource utilization
In a modern application, many companies are moving to adopt microservices architectures. As a result, this shift tends to propagate a lot of smaller databases. And companies often have a finite set of nodes on which to place those databases. So, when companies decide to manage these databases, they’re left with a sub-optimal allocation of databases onto nodes. However, running Kubernetes allows the underlying system to determine the best places to put the databases while optimizing resource placement on those nodes.
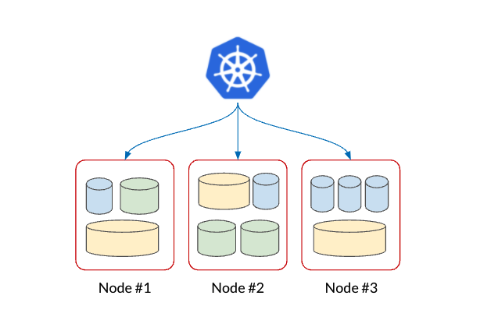
Kubernetes is best utilized when running a large number of databases in a multi-tenant environment. In this deployment scenario, not only do companies save on costs, they need fewer nodes to run the same sort of databases. These databases also have different footprints, CPU resources, memory, and disk requirements.
2. Elastic scaling of pod resources dynamically
The Kubernetes orchestration platform has the ability to resize pod resources dynamically. More specifically, to scale a database to meet demanding workloads, you can modify memory, cpu, and disk. Kubernetes makes it easy to scale up automatically without incurring any downtime through its horizontal pod autoscaler (HPA) and vertical pod autoscaler (VPA) operators. However, for VPA, it’s worth noting a database would need to have more than one instance to avoid downtime.
 A distributed SQL database provides a scalable and resilient data store for connecting applications. It takes care of migrating data between pods after a pod moves to a new node. It does this behind the scenes without any form of operator intervention.
A distributed SQL database provides a scalable and resilient data store for connecting applications. It takes care of migrating data between pods after a pod moves to a new node. It does this behind the scenes without any form of operator intervention.
3. Consistency and portability between clouds, on-premises, and edge
Companies want to be consistent with the way they build, deploy, and manage workloads at different locations. They also want the capability to be able to move workloads from one cloud to another, if needed. However, most organizations have a large amount of legacy code they still run on-premises and they’re looking to move these installations up into the cloud.
Kubernetes allows you to deploy your infrastructure as code, in a consistent way, everywhere. This allows you to write a bit of code that describes the resource requirements deployed to the Kubernetes engine and the platform will take care of that. You now have the same sort of control in the cloud that you would have on bare metal servers in your data center, or edge.
4. Out-of-the-box infrastructure orchestration
With Kubernetes, if a pod crashes, then it automatically restarts. Typically, pods can start anywhere, as the platform has the capability to say, “I want to move this workload from this pod to this node onto another node.” This allows it to do optimal resource allocation and utilization, but it’s really good for stateless workloads.
A microservice can deploy in a Kubernetes pod with 10 different instances of that pod serving traffic. The platform doesn’t care if one goes down and moves to a different node since it has no state. However, for a database, this becomes a bigger challenge when dealing with stateful workloads. This means you need to set up specific policies in Kubernetes to ensure it addresses this challenge.
For example, you may want to set up anti-affinity that allows you to specify in code the rules Kubernetes should follow. These include not wanting two instances of the same database on the same node. This allows your system to suffer a hardware failure without taking down multiple copies of database instances. You don’t want to lose multiple copies of the same piece of data.
 A distributed SQL database functions as a single logical database deployed as a cluster of nodes. This means the database cluster takes care of sharding, replication, load balancing, and data distribution. Therefore, a distributed SQL database keeps your database up and running even if there’s a pod, node, or underlying infrastructure failure. The database cluster is able to detect the failure, handle it, and recover without any loss of data or access by the application.
A distributed SQL database functions as a single logical database deployed as a cluster of nodes. This means the database cluster takes care of sharding, replication, load balancing, and data distribution. Therefore, a distributed SQL database keeps your database up and running even if there’s a pod, node, or underlying infrastructure failure. The database cluster is able to detect the failure, handle it, and recover without any loss of data or access by the application.
5. Automated Day 2 operations
Kubernetes allows periodic backups and database software upgrades. You want these operations automated so they can stay up-to-date. Even better, doing these updates across a database cluster is easy. Therefore, if a security vulnerability surfaces, and you want to patch it across the cluster, Kubernetes makes this very simple.
However, when using a traditional RDBMS with Kubernetes, you’re going to have a couple copies of the data. As a result, if you lose a pod, there’s another copy elsewhere. But you’re still responsible for migrating the data between those two pods and resyncing it for the failed instance when it comes back online. Kubernetes handles this asynchronously. This is why having automated Day 2 operations can be complicated for a traditional RDBMS.
For example, if you’re migrating data manually, you would check to see that the cluster isn’t under heavy load. You’ll need to wait until the load mitigates before moving the data to another node. But if you’re migrating data in an automated fashion, then you need to be careful to have those checks built in. Otherwise, if you take down a primary copy of data under heavy load, your replica may think it has the data when it really doesn’t. This means there could be two different copies of the data. It also creates the potential for data loss and inconsistencies.
Conclusion
Kubernetes has been a paradigm shift in the way enterprises build and deploy applications to cater to the needs of an increasingly cloud native world. There is no one-size-fits-all database reference architecture that works for all applications in this environment. Depending on the requirements of the application and tradeoffs involved, enterprises will choose different topologies to meet their needs, and change the topologies when needs change.
A distributed SQL database offers a powerful and versatile data layer for running applications in both the cloud and Kubernetes environments. Check out this free white paper to explore a real-world solution for ensuring Kubernetes deployments are always resilient and continuously available.
Download Now

