Performing Flexible IO Testing in YugabyteDB
March 18, 2022
ybio is a PL/pgSQL based load generator for PostgreSQL and YSQL. This YugabyteDB-specific IO testing toolkit performs flexible IO testing to specific parts of the YugabyteDB infrastructure with no client installation. And because this toolkit is PL/pgSQL-based, it can also work on native PostgreSQL.
ybio is strongly inspired by Kevin Closson’s SLOB and pgio. Yugabyte Developer Advocate Franck Pachot took pgio and turned it into ybio. As a result, my work expands and updates what Franck has already created.
This tool differs from PostgreSQL’s pgbench since pgbench provides statistics for the client side of execution. On the other hand, ybio concentrates on performing one or a few (select/update/delete) actions intensely to stress test the database server side. It doesn’t try to perform an application execution pattern. It focuses solely on stress testing specific parts of the database.
In this post, we walk through how to perform flexible IO testing in YugabyteDB with ybio. We’ll also provide some advanced setup and configuration options when running tests on your own.
Downloading, installing, and deinstalling ybio
For starters, you can obtain ybio here:

The install script will install the orafce extension. The orafce extension is available by default in YugabyteDB.

When deinstalling the toolkit, please keep in mind that the below uninstall script will not uninstall the orafce extension. In addition, this script will not uninstall the numbered benchmark schemas (ybio<nr>).

Creating a run configuration for flexible IO testing
The ybio tool lives in a schema called ybio in the YugabyteDB database. A table called ybio.config stores the central configuration, and is empty after installation:

All the fields have default values. This means that in order to create a row, the only thing you have to do is insert at least one field, such as ‘rows’:

This results in:
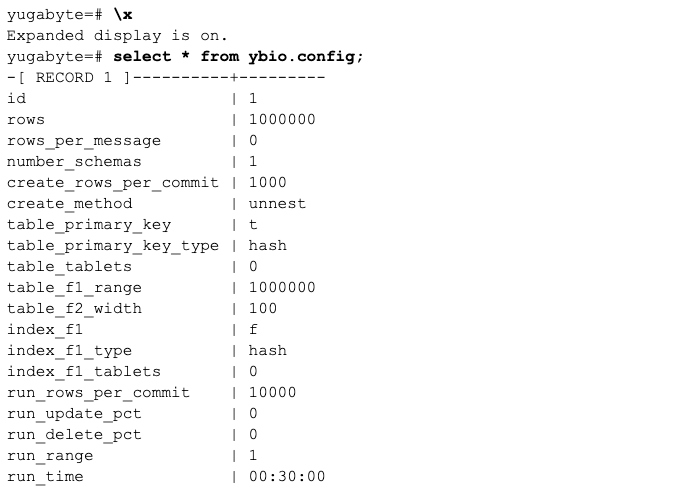
Preparing for setup
Once a configuration exists, it can be set up. This can be a test itself, or a setup for running select, update, and delete.
Setup—at a minimum— takes the ybio.config.id of the ybio.config table as an argument:

The default setup will drop and recreate the ybio<schema nr> schema for the benchmark_table.
Setup and multiple schemas for flexible IO testing
If a configuration has a number of schemas (number_schemas) modified from the default value of 1, running it in this way will create the different schemas and table. It will also insert the number of rows into the table sequentially. You can optionally run the setup (inserting the rows) for a single schema by explicitly specifying the schema number in the following way:
![]()
This also allows multiple setup and insert procedures at the same time.
It will not be a performance problem if one of the YSQL nodes runs the ysqlsh client. The ysqlsh client does not take a significant amount of resources because a majority of the resource usage is in the backend.
Setup and specifying a tag for a run
The table ybio.results records every run (where setup also counts as a run). By default, setup uses the tag ‘insert’:

Additionally, there is the view ybio.results_overview. This view groups the runs by tag (ybio.results_run_tag) and shows additional computed statistics, such as run time in seconds, average number of rows per second, and the average latency of a row:
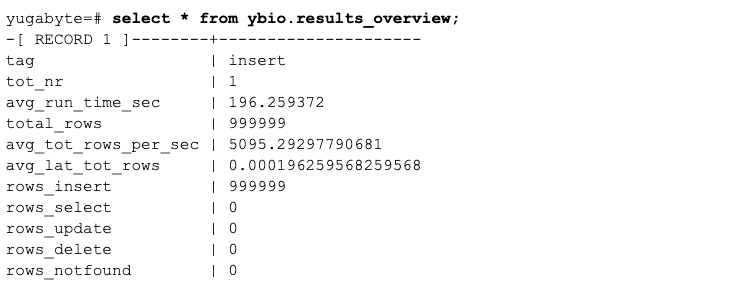
If setup runs again, it will use the same tag ‘insert’, and the results_overview view will sum the statistics. This does not make sense for multiple, independent setup or insert runs. However, it does make sense when multiple setup or runs execute from multiple nodes in a YSQL cluster at the same time.
Setup and specifying an additional run
When the setup procedure executes in parallel, it requires setting the schema number as the second argument. As a result, it will create and insert the data into an independent table in an independent schema (i.e., ybio1.benchmark_table or ybio2.benchmark_table).
However, sometimes you want to test running inserts into the same table. The additional run number as the fourth argument gets this done:

The number for ‘additional run test’ sets the starting id number. The starting number calculates as additional_run_number * ybio.config.rows. This means that in an already setup schema, the first usable number is 2 to get id values that are higher than what already exists. Using existing id values would throw a primary key violation error by default.
Running the flexible IO test
Now that the test table (ybio<nr>.benchmark_table) exists in one or more schemas, we can perform testing. By default, a test will run for 30 minutes with selects only. This is because of the defaults of the fields in the ybio.config table. The number specified is the ybio.config.id number.
This is what it looks like:

Run a flexible IO test for a schema number
By default, the ybio.run procedure requires the ybio.config.id number to tell it what to do. The run by default will take place in schema number 1 (ybio1). If you have specified multiple schemas for a configuration in ybio.config.number_schemas, you can run ybio.run for a different schema in the following way:

Obviously, this only makes sense if the schema is already set up.
Run a flexible IO test with a runtag set
It’s hard to get an overview if you run multiple database sessions. However, the ybio.results table saves performance figures of every run. ybio.run can be executed with a third argument, which is the runtag:
![]()
The runtag sets the ybio.results.run_tag field for the results of the run. The view ybio.results_overview aggregates the results based on the run_tag field. This means it shows the average of the figures for all the runs with the same tag.
Removing the benchmark schema
If you want to remove the benchmark schemas of a configuration (ybio<schema nr>), you can run the ybio.remove procedure. This procedure takes the ybio.config.id value to determine which schemas to remove:

By default, please keep in mind the setup procedure will also remove the schema prior to creating it.
Description of ybio.config options for flexible IO testing
Below are a series of different config options for running various IO tests.
config rows (default: 1000000)
The ybio.config.rows field determines the number of rows inserted during setup. ybio.run takes this number as the amount of rows that should exist. When a row doesn’t exist when running ybio.run, it will count as ‘notfound’.
config rows_per_message (default: 0)
The ybio.config.rows_per_message field sets the number of rows after a message prints the progress for both setup and run. The value of 0 means it takes the create_rows_per_commit or run_rows_per_commit value. The number rounds to the next value if it’s lower or not an exact multiple of create_rows_per_commit or run_rows_per_commit.
config number_schemas (default: 1)
The ybio.config.number_schemas field determines the number of schemas created for this configuration. If ybio.setup is called without perform_schema_nr set or set to zero, it will create the benchmark table in all the schemas. If perform_schema_nr is set to a non-zero number, it will create that schema number, but will be limited to number_schemas.
config drop_before_insert (default: true)
The ybio.config.drop_before_insert field determines if the inserted table gets dropped and recreated if it exists already. If this is set to false, it allows the (ybio<nr>.benchmark_table) table to be pre-created. This can be useful if you want to test a specific configuration of the table.
config create_rows_per_commit (default: 1000)
The ybio.config.create_batch_size field determines the number of rows before a commit executes during setup. This is also the number of rows after which a NOTICE row prints with statistics of the insertion during that time.
config create_method (default: unnest)
The ybio.config.create_method field determines the way the number of rows appear in the benchmark_table table. Current options are:
- unnest: an array is created in plpgsql, which is used with insert into unnest(array).
- row: every row executes as an insert statement.
config table_primary_key (default: true)
The ybio.config.table_primary_key field determines a primary key. It can be set to false to not define a primary key.
config table_primary_key_type (default: hash)
The ybio.config.table_primary_key_type field determines the type of the primary key. Besides hash, it can be set to ‘asc’ or ‘desc’ to create a range index.
config table_tablets (default: 0)
The ybio.config.table_tablets field determines the number of tablets for the table. If it’s set to 0, no number of tablets is specified during creation. However, if it’s left to YSQL—when set to 1 or higher—the table is defined with the configured number of tablets.
config table_f1_range (default 1000000)
The ybio.config.table_f1_range field determines the range of values in the numeric field benchmark_table.f1. This controls the selectivity for this field.
config index_f1 (default: false)
The ybio.config.index_f1 field determines a secondary index during the creation of the benchmark_table. As a result, it needs to be maintained during insertion.
config index_f1_type (default: hash)
The ybio.config.index_f1_type field determines the type of the index on benchmark_table.f1. Besides hash, it can be set to ‘asc’ or ‘desc’ to create a range index.
config index_f1_tablets (default: 0)
The ybio.config.index_f1_tablets field determines the number of tablets for the index on benchmark_table.f1 field. If it’s set to 0, no number of tablets is specified during creation. However, if it’s left to YSQL—when set to 1 or higher—the table is defined with the configured number of tablets.
config table_f2_width (default: 100)
The ybio.config.table_f2_width field determines the width. This means the number of random characters put in the benchmark_table.f2 field. A text field defines the benchmark_table.f2 field. This controls the size of the records.
config run_rows_per_commit (default: 1000)
The ubio.config.run_batch_size field determines the number of rows during the execution of ybio.run following a performed commit.
config update_pct (default: 0)
The ybio.config.update_pct field determines the procentual amount of update statements during the execution of ybio.run. The fields f1 and f2 are changed or updated by the update statement. The amount that is left by 100 – (update_pct+delete_pct) is executed as a select statement.
config delete_pct (default: 0)
The ybio.config.delete_pct field determines the procentual amount of delete statements during the execution of ybio.run. The amount that is left by 100 – (update_pct+delete_pct) executes as a select statement. When using delete_pct, it is possible the deleted row gets chosen again during the run. This is because it originally should exist within the range of the rows as set by ybio.config.rows. Therefore, a statistic ‘notfound’ exists during runit.
config run_range (default: 1)
The ybio.config.run_range field determines the amount of rows requested with select, update, and delete during ybio.run. The value of 1 will request id = NR, but a higher value will request an id between NR and NR+run_range.
config run_time (default: ’30 minutes’)
The ybio.config.run_time field determines the time that the procedure ybio.run will run. This is an internal, so you can specify it as ‘1 minute’ or ‘1 hour’.
Conclusion
ybio is different than most database benchmark tools for flexible IO testing. It’s different because it tries to stress the database maximally, instead of following a fixed pattern to mimic a use case. One of the reasons ybio can stress the database maximally is that it’s written in PL/pgSQL, and runs inside YSQL. Therefore, it’s not bound by client tool network limits.
Finally, ybio’s settings perform a very board range of actions to test all parts of the database. These include:
- Using a primary key (or not)
- Setting the type of the index underneath the primary key (hash, ascending, descending)
- Setting the number of tablets
- Using a secondary index on the f1 field or not (and it being hash, ascending, descending and the number of tablets)
- Setting the range for the f1 field (and thus by lowering the table_f1_range increasing the number of identical values)
- Setting the width of the “other” fields, where the “other” fields are the fields f2, f3, f4, f5, f6, f7, f8, f9, f10.
- Establishing a range for any run action (which is a bad idea when the primary key index is set to hash), to provide an indication of the flexibility.
Take YugabyteDB for a spin by downloading the latest version of the open source. Any questions? Ask them in the YugabyteDB community Slack channel.


