Getting Started with Distributed Backups in YugabyteDB
November 19, 2018
YugabyteDB is a distributed database with a Google Spanner-inspired strongly consistent replication architecture that is purpose-built for high availability and high performance. This architecture allows administrators to place replicas in independent fault domains, which can be either availability zones or racks in a single region or different regions altogether. These types of multi-AZ or multi-region deployments have the immediate advantage of guaranteeing organizations a higher order of resilience in the event of a zone or region failure. However, it is still a good idea to have a reliable and repeatable backup strategy. For example, as an administrator you may need to restore a database to undo a logical data corruption caused by an application bug.
YugabyteDB is a distributed database that delivers efficient, multi-TB backups and restores under heavy read and write workloads compared to eventually consistent databases like Apache Cassandra.
In this post, we review the distributed backup architecture in YugabyteDB as well as the configuration and results of multiple backup/restore operations on a multi-AZ, single region cluster.
- Backup #1: A 1.6 TB backup of a 6 node cluster to AWS S3 during a write-heavy workload.
- Restore #1: A restore of backup #1 from S3 to a 5 node cluster.
- Backup #2: A 3.6 TB backup of a 6 node cluster to AWS S3 during a read-heavy workload.
- Restore #2: A restore of backup #2 to the original 6 node cluster.
A follow up post covers distributed backups in the context of multi-region deployments.
Distributed backup architecture
The backup process in an eventually consistent database such as Apache Cassandra must read from all the replicas for the backup to have a coherent copy of the data. This limitation often leads to bottlenecks caused by the system’s demand for increased system resources (disk, IO, CPU). Unlike eventually consistent databases, YugabyteDB uses strongly consistent replication that’s based on Google Spanner’s per-shard distributed consensus architecture. This architecture enables very efficient backups and restores. YugabyteDB’s distributed backups read data only from the leaders of various shards and do not involve the replicas at any time in the process.
Additionally, YugabyteDB’s Log Structured Merge (LSM) storage engine design enables a very lightweight checkpoint mechanism. A checkpoint is taken for each shard at the leader without requiring any expensive logical reads of the data. The compressed on-disk storage files from the leader of each shard are copied in a steady, rate-limited manner, to the backup store with minimal impact on the foreground operations.
YugabyteDB currently supports table level backups and restores. The backup stores themselves can be a cloud object storage endpoint such as AWS S3 or an NFS storage location.
Configure a backup store
YugabyteDB can be configured to have an Amazon S3 or an NFS endpoint as a backup store. In our example, we use an S3 bucket that’s been configured for the us-east-1 region (the same region where our YugabyteDB cluster will be created). Note that this backup store is now available to all clusters managed using the same YugabyteDB Enterprise Admin Console.
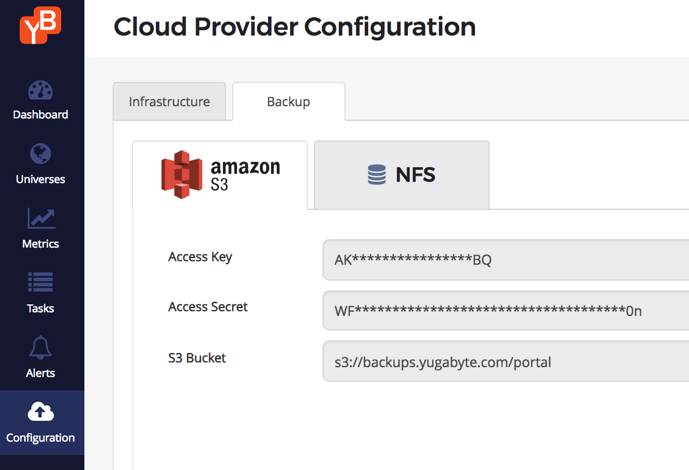
Create a source cluster
We first create a 6 node cluster on AWS with replication factor 3. The configuration details of this cluster are noted below.
Configuration of the 6 node “Backup Source” cluster
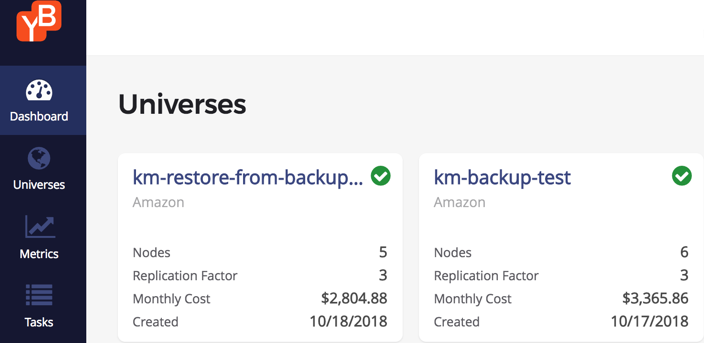
- Backup Source: “km-backup-test”
- Cluster Configuration: 6 nodes, i3.2xlarge (8-vcpus, 61 GB RAM, 1 x 1.9TB nvme SSD per node)
- Cloud Provider: AWS
- Replication Factor: 3
- Final Dataset: 3.6 TB data set across 6 nodes (about 600 GB per node)
- Key + Value Size: ~300 Bytes
- Key size: 50 Bytes
- Value size: 256 Bytes (deliberately chosen to be not very compressible)
- Final Logical Data Set Size: 4 Billion keys * 300 Bytes = 1200 GB
- Final Raw Data Including Replication: 1200 GB * 3 = 3.6 TB
- Final Expected Data Per Node: 3.6 TB / 6 = 600 GB
Initialize a write-intensive workload
Next, we spun up a process to load data into the source cluster at a steady rate using the CassandraKeyValue sample application.
$ java -jar yb-sample-apps.jar -workload CassandraKeyValue --nouuid \
--nodes $CIP_ADDR --value_size 256 \
--num_unique_keys 4000000000 --num_writes 4000000000 \
--num_threads_write 200 --num_threads_read 1
The YB-Master Admin UI below shows all the YB-TServer data nodes and their real-time read/write performance under the workload. It also highlights additional cluster details such as:
- The IPs of the tablet servers
- The number of tablets on each server
- The number of tablet leaders
- The size of the on-disk SSTable files.
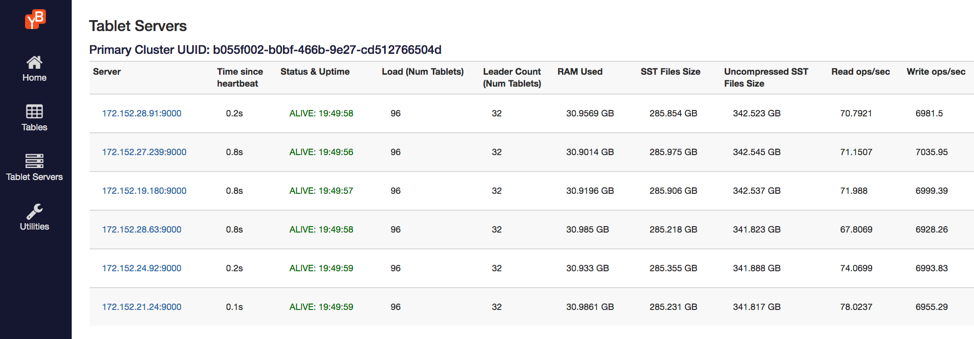
The screenshot above was taken when the data load process was about 50% done, or 2 billion records loaded. Each node has about 290 GB at this point of time.
Collect baseline stats for the load phase
The system stats below serve as a baseline for comparing the effect of performing a backup on a cluster that’s actively executing write intensive workload. Note that the system is performing about 40K insert operations/second and CPU is about 70-75%.
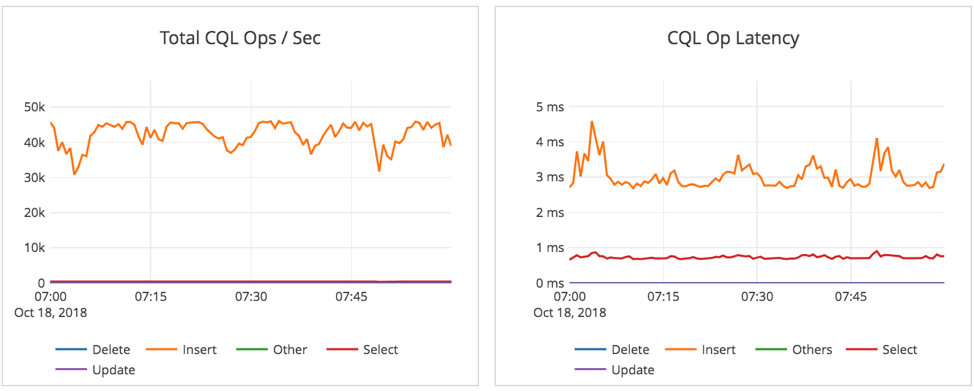
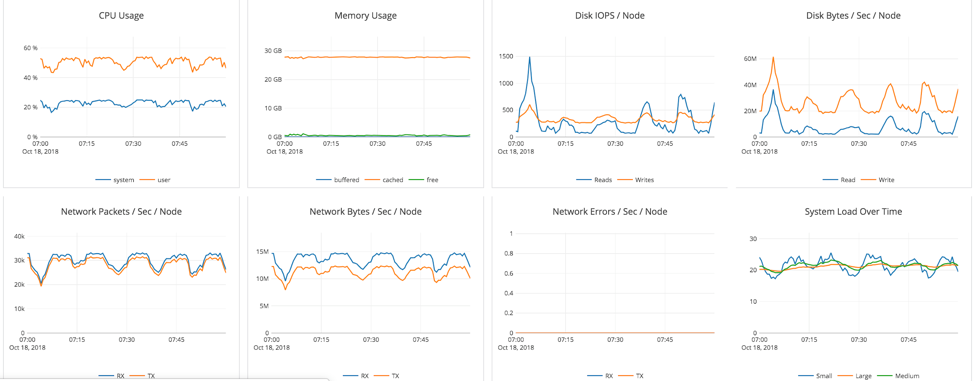
Backup #1 during write-intensive workload on 1.8 TB data
- Workload: Backup was initiated during a “write-heavy” workload, with 50% of the data having been written (1.8 TB)
- Elapsed Time: 1 hr 5 mins
- Results: No major impact on foreground operations (see below)
Identifying backup’s impact on cluster performance
At the start of the backup operation, we see a brief dip when every tablet is being flushed and a checkpoint was taken. Aside from that, we see that throughput does not drop much when backups are underway. CPU usage remains about the same but disk and network activity is higher. This is expected since backups have to transfer the data from disk over the network to the target (S3).
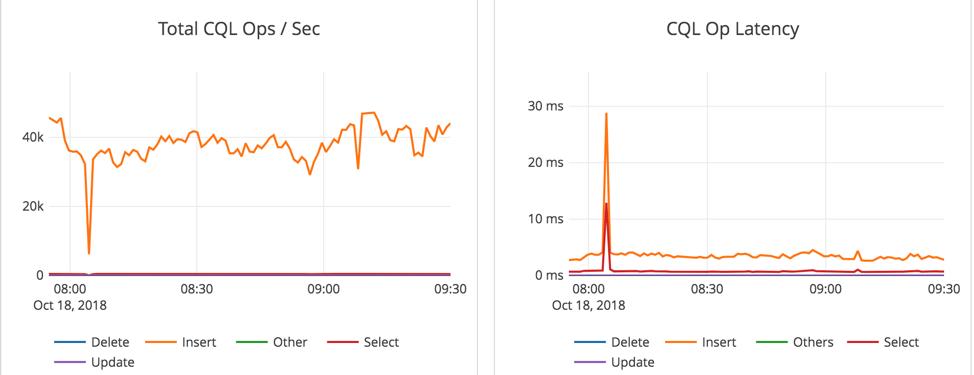
Restore #1 into a separate cluster
We should recall that our backup source cluster was a 6 node cluster. With YugabyteDB, restore destinations can have different node counts or host configurations than the backup sources. In this example, we created a 5 node cluster to restore our 6 node cluster backup.
Configuration of the 5 node “Resource Destination” cluster
- Restore Target: AWS S3 to “km-restore-from-backup”
- Cluster Configuration: 5 nodes, i3.2xlarge (8-vcpus, 61 GB RAM, 1 x 1.9TB nvme SSD per node)
- Replication Factor: 3
- Elapsed Time: 2 hrs
- Results: During the restore there was no noticeable performance penalty impact worth mentioning because the table isn’t live and typically there are no application operations running until the restore is complete.
Time taken to restore
Restoring into the new 5-node cluster took 2 hrs (from 5:21 pm to 7:20 pm). Restore operations are indeed going to take longer than the original backup because the restore has to create 3 copies of data whereas the backup only has to transfer 1 copy of the data. However, there is an additional detail worth pointing out.
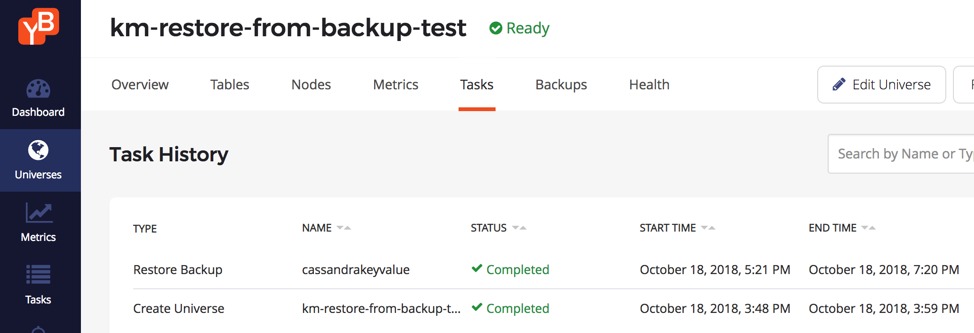
According to above screenshot, the backup finished at 7:20pm. However, much of the disk write activity related to the restore was already complete by 6:35pm.
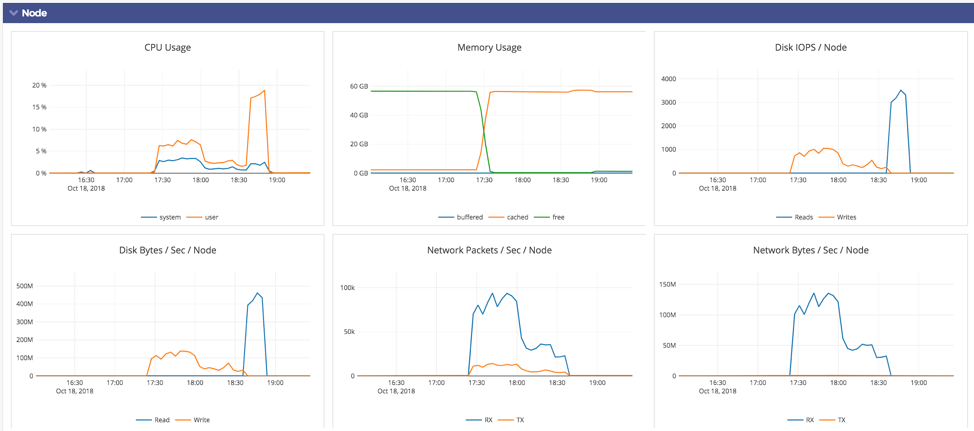
The disk read spike after this phase is for the checksum verification step. This test identified an obvious opportunity for optimization. We intend to improve/smoothen this spike by doing checksum verification when the files are copied over rather than all at the end.
Initialize a read-intensive workload
After 4 billion records (3.6 TB) finished loading into the 6 node cluster, we run the following read intensive workload:
% java -jar yb-sample-apps.jar -workload CassandraKeyValue --nouuid --nodes $CIP_ADDR --value_size 256 --max_written_key 3999999999 -num_threads_write 4 --num_threads_read 128

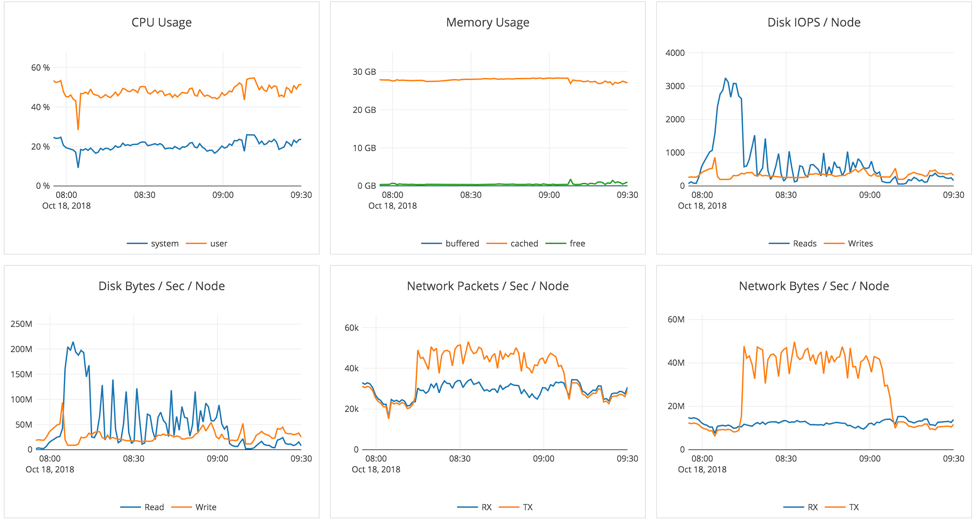
We then initiate a second backup and at this stage, each node had about 570 GB of data. This results in a total compressed on-disk data set of about 3.4TB. (See screenshot above.)
Backup #2 during read-intensive workload on 3.6 TB data
Configuration 6 node cluster
- Workload: Backup was initiated during a “read-heavy” workload, after 100% of the data (3.6TB) was written
- Elapsed Time: 2 hrs
- Workload: During backup, a read-heavy workload was running
- Results: No major impact on foreground operations
Identifying impact of backup on cluster performance
This second backup took about 2 hrs to complete (8 AM-10 AM) as seen from the system graphs below.
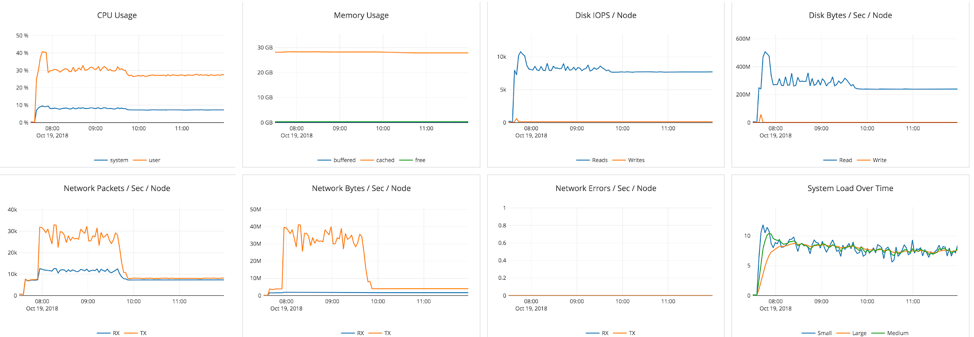
As we can see below, during the 2 hrs there’s hardly any observable dip in traffic:
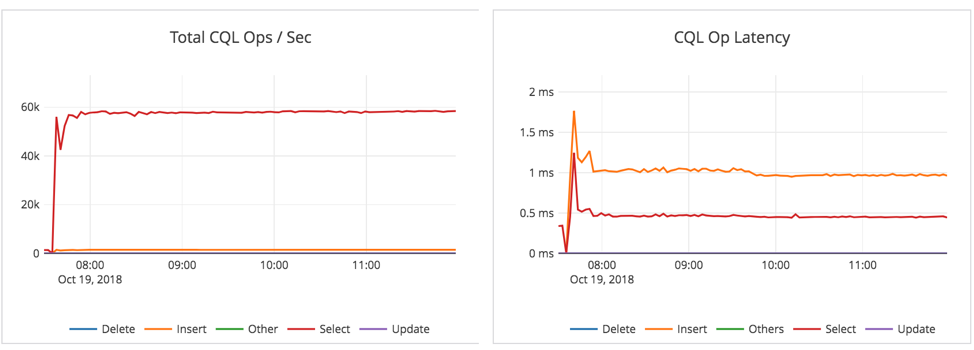
Restore #2 with data integrity verification
After the backup completes, we restore the data back into the original 6 node cluster. The restore takes 3 hours to complete given the data involved is now 2x in size. To verify the integrity of the restore operation we used the CassandraKeyValue sample app (which has built-in data verification) to perform random reads across the key space and verify the correctness of data.
# Perform random reads on the 4B keys restored from backup.
$ java -jar yb-sample-apps.jar -workload CassandraKeyValue \
--nouuid --nodes $CIP_ADDR --value_size 256 \
--max_written_key 3999999999 \
--read_only --num_threads_read 128
The results showed no errors!
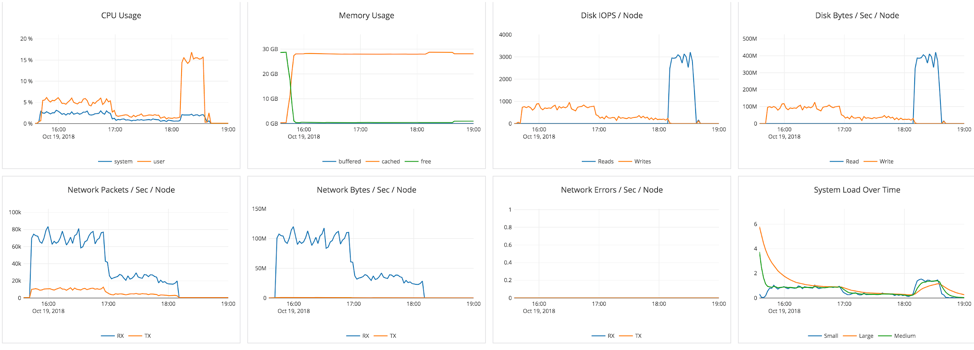
Identifying impact of restore on cluster performance
System stats during the restore operation show a spike in the disk reads towards the end of the three hour process. This spike coincides with the “checksum verification” step we observed in the previous restore operation.
Summary
Backups and restores in YugabyteDB are designed to work on large data sizes (multiple TBs) and that too without any impact to the foreground performance observed by application clients. The core design advantage can be attributed to the per-shard distributed consensus based replication architecture as well as an efficient LSM storage engine. Operations engineers responsible for running mission-critical clusters with zero data loss can be rest assured that the backup/restore operations are highly reliable and repeatable irrespective of the type of workload the cluster is serving.
What’s Next?
- Read our post on how to perform distributed backups in YugabyteDB running on a multi-region AWS cluster.
- Install a local YugabyteDB cluster in minutes!
- Compare YugabyteDB to databases like Amazon DynamoDB, Apache Cassandra, MongoDB and Azure Cosmos DB.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.
 Scenarios and the Multi-Tenancy Options That Support Them")

