How Does the Raft Consensus-Based Replication Protocol Work in YugabyteDB?
August 8, 2018
Editor’s note: This post was originally published August 8, 2018 and has been updated as of May 28, 2020.
As we saw in ”How Does Consensus-Based Replication Work in Distributed Databases?”, Raft has become the consensus replication algorithm of choice when it comes to building resilient, strongly consistent systems. YugabyteDB uses Raft for both leader election and data replication. Instead of having a single Raft group for the entire dataset in the cluster, YugabyteDB applies Raft replication at an individual shard level where each shard has a Raft group of its own. This architecture is similar to how sharding and replication work in Google Spanner, Google’s proprietary distributed SQL database. This post gives a deep dive into how YugabyteDB’s Raft usage works in practice and the resulting benefits.
YugabyteDB is an open source, high-performance distributed SQL database for internet-scale, globally-distributed apps. Features include PostgreSQL compatibility, ACID transactions, automated sharding, replication and rebalancing across availability zones and regions, all without compromising high performance.
Under the Hood of a YugabyteDB Cluster
The figure below highlights the architecture of a three-node YugabyteDB cluster configured with a Replication Factor (RF) of three. Sharding and replication are automatic in YugabyteDB. Tables are auto-sharded into multiple tablets. Each tablet has a Raft group of its own with one leader and a number of followers equal to RF-1. YB-Masters, whose number equals the RF of the cluster, act as the metadata managers for the cluster which includes storing the shard-to-node mapping in a highly available and durable manner. YB-TServers are the data nodes responsible for serving read and write requests. Raft is used for leader election and data replication in both YB-Master and YB-TServer.
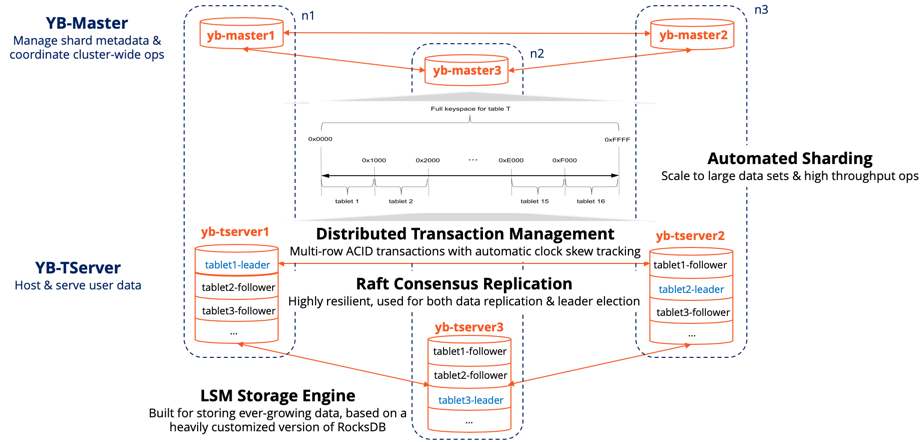
Three Node RF3 YugabyteDB Cluster
Benefits of YugabyteDB’s Replication Architecture
This section highlights the benefits of Raft-based replication in YugabyteDB.
Strong consistency with zero data loss writes
Raft along with Hybrid Logical Clocks (HLC) enables single-row, single-operation ACID in YugabyteDB. Thereafter, YugabyteDB builds on this foundation to implement distributed ACID transactions.
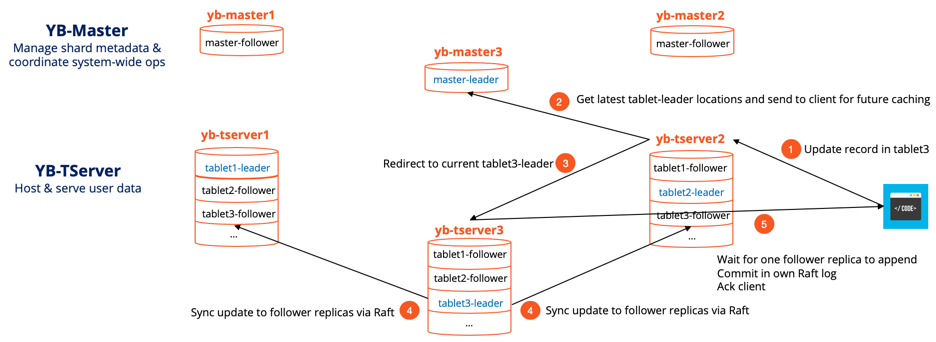
Zero Data Loss Write Path
Here’s how a single-row write operation works in YugabyteDB.
- Let’s say an application client wants to update a row in tablet3 and yb-tserver2 is where this request lands for the first time.
- It gets automatically re-directed to the current master-leader, yb-master3 to get the node location where tablet3’s leader resides. This location is now cached in the client driver so that future requests do not involve the master-leader.
- The actual request now gets redirected to the node that has tablet3-leader which is yb-tserver3 in this case.
- tablet3-leader appends this update to its own Raft log and replicates it to the Raft log of the two followers. It waits for one follower to successfully append the update to its Raft log, in addition to itself.
- tablet3-leader now marks the update as committed in its own Raft log, applies the update to the memtable of its RocksDB-based local store, and acks the client noting the update as successful. Note that there is no additional write-ahead-log (WAL) in the local store. More details on how the local store functions can be found in “Enhancing RocksDB for Speed & Scale”.
The end result is that the update above is now available for all future reads (strongly consistent reads from leader and timeline consistent reads from followers) and is also resilient against failure of one node or disk (see next section on Continuous Availability). Resilience against more failures is achieved by simply increasing the RF from three to five or seven.
Continuous availability with self-healing leader election
YugabyteDB uses Raft to heal the cluster automatically by electing new leaders for those tablet-leaders that get lost for any reason.
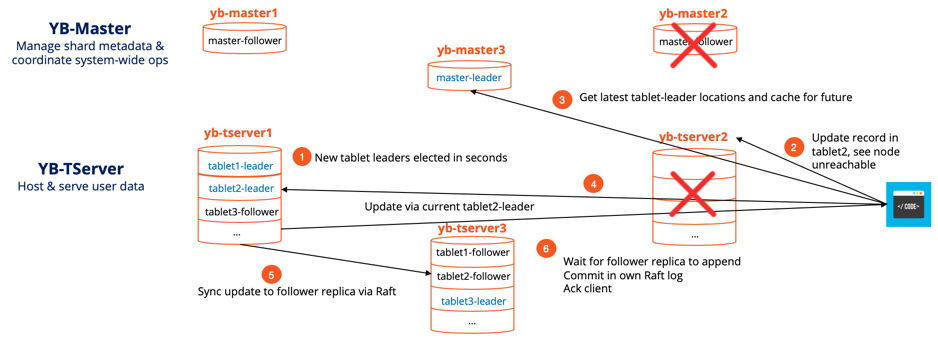
Continuous Availability Even Under Node/Disk/Network Failures
- Let’s assume node2 crashes and as a result we lose both yb-master2 and yb-tserver2. This means tablet2-leader, located on yb-tserver2, is also no longer available. This leads to the automatic leader election for tablet2 among the two remaining replicas. Let’s assume that the tablet2 follower on node1 now becomes the tablet2-leader. The master-leader is updated of this change. Note that tablet1 and tablet3 that lost only followers because of node2 death had no impact on their availability.
- The application client now tries to update a record in tablet2 but finds yb-tserver2 unreachable.
- It finds the latest location for tablet2-leader from master-leader and caches the information.
- Update request is sent to tablet2-leader on node1.
- tablet2-leader now synchronously replicates this update to tablet2-follower on node3, the only follower that’s alive.
- After tablet2–follower acknowledges the update, tablet2-leader updates its own record and acknowledges the client noting the update as successful.
So the loss of one node in a RF3 cluster leads a very short write unavailability (of ~3 seconds) during which leader election for the impacted tablets takes place. This is by design since accepting new writes on those tablets can lead to data loss (since there are not enough replicas available for quorum). The system continues as normal after the leader election completes and tablets rebalance to the old node whenever it comes back.
Rapid scale-out and scale-in with auto-rebalancing
Raft enables dynamic membership changes with ease. Removal of nodes boils down to re-running Raft leader election for only those tablets that are impacted followed by a YB-Master-led re-creation of replicas to achieve full replication. Addition of nodes becomes a leader-and-follower tablet rebalancing task initiated by the YB-Master. Let’s review what exactly happens when a new node is added to a cluster that has three nodes with four tablets. The node n1 has two leaders, tablet1-leader and tablet4-leader.
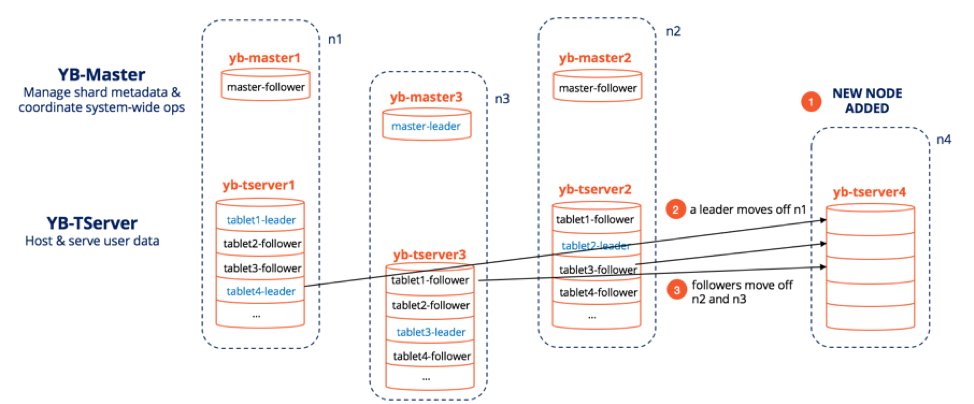
New Node Added to a Three Node YugabyteDB Cluster
- New node n4 is added to the cluster.
- The master-leader is aware of this change to the cluster and initiates re-balancing operations which involves a leader (say tablet4-leader) moving off n1. Note that this move may involve tablet4-leader to temporarily give up its leadership to one of the other replicas and then taking it back on after the tablet4 becomes available at n4.
- For a perfectly balanced cluster, some followers will also move from n2 and n3 to n4. Note that all the moves are undertaken in such a way that no single existing node bears the burden of populating the new node — all nodes in the cluster chip in with their fair share and as a result the cluster never comes under stress.
- The figure below shows the final, perfectly balanced cluster where each node has one leader and three followers.
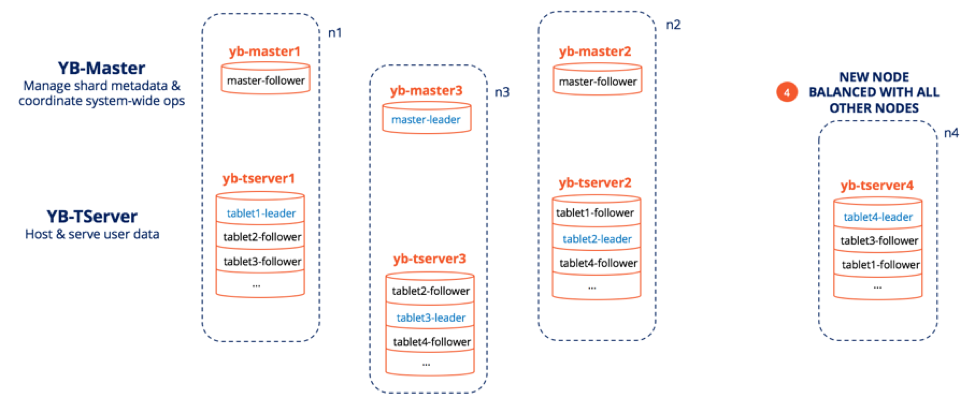
A Balanced Four Node YugabyteDB Cluster
High performance with quorumless reads and tunable latency
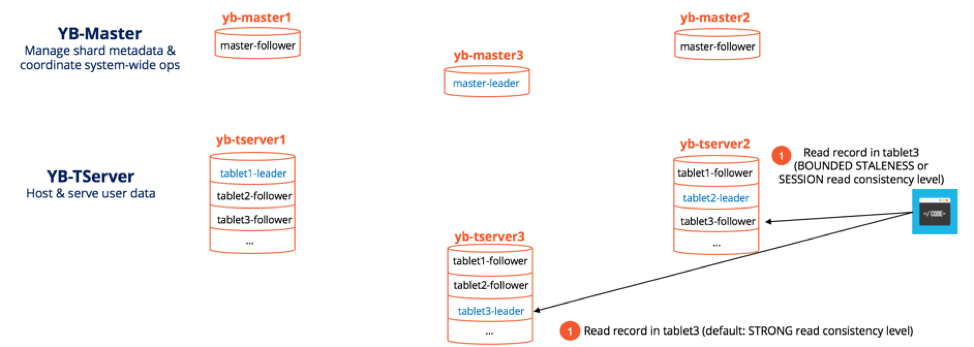
Given the important task of ensuring consistency is already completed at write time, YugabyteDB’s Raft implementation ensures that read requests can be served with extremely low latency without using any quorum (where other replicas have to be consulted). Additionally, it allows the app client to choose from reading the leader (for strongly consistent reads) or from the followers (for timeline-consistent reads).
YugabyteDB even allows reading from Read Replicas which are asynchronously updated from the leaders/followers and do not participate in the write path. Reading from followers and read replicas allows the system to increase throughput significantly since there are more followers than leaders and can even reduce latency if the leader happens to be in a different region.
Summary
Traditional monolithic SQL databases such as MySQL and PostgreSQL are essentially single shard solutions with master-slave replication that require application downtimes in presence of failures. This means they cannot serve mission-critical online services with large data needs. Legacy NoSQL databases such as Amazon DynamoDB and Apache Cassandra solve the sharding and availability problem but are prone to data loss upon failures given the use of peer-to-peer replication as opposed to consensus-based replication such as Raft. YugabyteDB frees up application developers from these age-old compromises by delivering strong consistency, continuous availability, rapid scaling, and high performance in a single database. It does so through a unique combination of automated sharding and Raft-based replication.
What’s Next?
- Read: “How Does Consensus-Based Replication Works in Distributed Databases?”
- Compare YugabyteDB to databases like CockroachDB, Google Cloud Spanner, and MongoDB.
- Get started with YugabyteDB.
- Contact us to learn more about licensing, pricing, or to schedule a technical overview.


