Can Distributed Databases Achieve Transactional Consistency on Async Standbys? Yes, They Can.
February 21, 2023
When users configure an async standby of their active cluster, they also expect certain transactional guarantees on the standby. If the active cluster fails and the promoted standby yields a partially committed transaction, it would be a disaster!
In this blog post, we discuss how to maintain transactional read guarantees on an async standby configured through cross cluster replication. This feature impacts any user who runs a transactional application in a distributed setup. We think that applies to many people reading this blog.
YugabyteDB is a distributed SQL database with clearly defined transactional guarantees and semantics on the read and write path. To our knowledge, we are the first distributed database to solve this problem, and we are very excited to share our approach!
Note on availability: The xCluster feature on transactional guarantees described in this blog is available as a preview feature in YugabyteDB 2.17.1+.
What is an Async Standby?
Before we go further, we need to understand what an async standby is in the context of databases.
An async standby is a read-only database that mirrors the active database, with some lag. If the active database fails, the standby is promoted (with some data loss depending on the lag) and starts taking writes. In YugabyteDB, async standbys are configured per-database, using cross cluster replication.
Cross-Cluster Replication
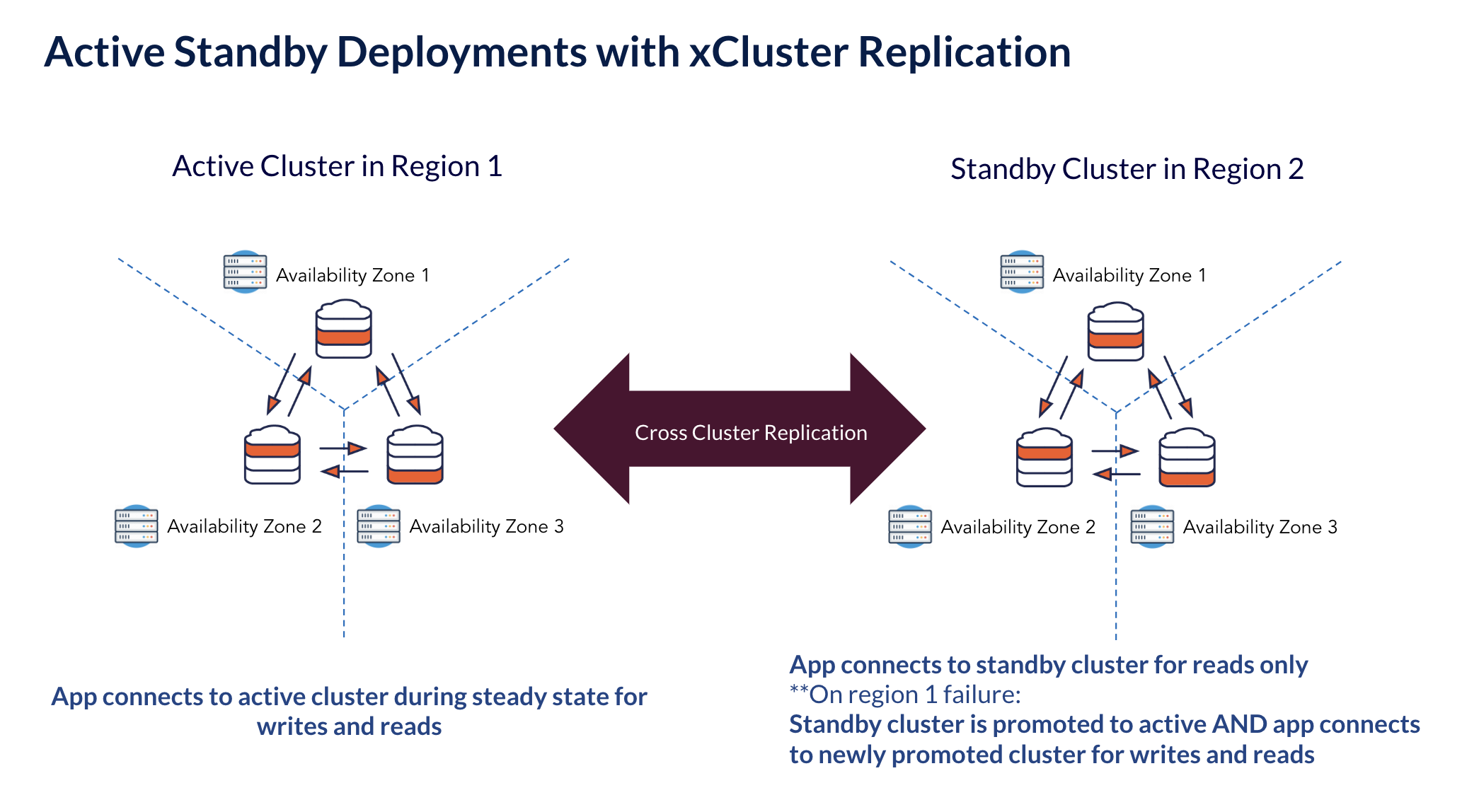
Replication is enabled at the database level and uses a polling-based mechanism to fetch all the writes recorded since the last time polled. To accomplish this, the active cluster uses its write ahead log (WAL), an ordered list of records per shard, and keeps track of a checkpoint in the log.
Let’s illustrate a typical example of a transactional violation that can occur with the following situation on the standby cluster:
- A transaction (txn) spanning shards A and B has been committed on the active cluster.
- The standby has replicated A’s records in txn, but not B’s records in txn.
- A read on the standby will show txn’s records from A but not B, violating atomicity.
Transactional Consistency on a Standby
Let’s clearly define “transactional read guarantees.” We want the following two guarantees when reading from and after the promotion of the standby:
- Atomicity: A cross-shard transaction is either fully visible or not visible.
- Global Ordering: All transactions including cross-shard transactions will be visible in the same order as they were committed on the active cluster.
No Time Like a Safe Time
In a single-cluster case, each read on a database occurs at a point in time. This timestamp is referred to as a “safe time”- a time below which no new writes can enter the system.
Safe time is the bedrock of transactional read consistency, providing a foundation for repeatable reads and transactional atomicity.
So, how can we translate the concept of safe time to the standby cluster? If we keep the same semantics as the single-cluster case, a read on a standby must occur at a time below which no new records from the active cluster can come in.
In other words, any read on a database occurs at the timestamp of the laggiest shard in the database. If we have a standby database with the following shards:
| Shard | Caught Up to Time from Active |
| A | T=80 |
| B | T=60 |
| C | T=40 |
Reads for this database will happen at T = 40. Once this read time advances past the transaction commit time, that transaction becomes visible.
All queries will read transactions atomically because a transaction becomes visible only once all shards have the records from it.
Global ordering of transactions is preserved. If txn1 has a commit time less than txn2, then txn1 will always be visible before txn2.
The Tradeoff for Consistency
The tradeoff for achieving transactional consistency is staleness of reads and data loss on a failover corresponding to the lag between active and standby. This may not be desirable for non-transactional workloads that place more importance on reading the latest and greatest than on reading transactionally consistent data.
Real World Application of These Concepts
Let’s discuss a real-world example that illustrates how these concepts come together in a few simple steps to achieve transactional consistency on an async standby.
Newly formed YugaBank stores a metadata table with the balances of all of its customers, with an active cluster A on the east coast and an async standby B on the west coast serving reads.
I want to create a checking and a savings account with a total of $10,000 among the two accounts.
create table balances(name varchar(100), account varchar(100), balance bigint); INSERT INTO balances VALUES(‘Rahul’, ‘Checking’, 5000); INSERT INTO balances VALUES(‘Rahul’, ‘Savings’, 5000);
I run an application on the active cluster that continually transfers $100 back and forth between the checking and savings account. The total balance across my accounts should always equal $10,000.
for (( ; ; )) do ysqlsh -h <active_ips> -c "BEGIN TRANSACTION; UPDATE balances SET balance = balance - 100 WHERE name = ‘Rahul’ and account = ‘Savings’; UPDATE balances SET balance = balance + 100 WHERE name = ‘Rahul’ and account = ‘Checking’; COMMIT;" done ysqlsh -h <active_ips> -c "BEGIN TRANSACTION; UPDATE balances SET balance = balance + 100 WHERE name = ‘Rahul’ and account = ‘Savings’; UPDATE balances SET balance = balance - 100 WHERE name = ‘Rahul’ and account = ‘Checking’; COMMIT;" done
Why? The bank has a policy that all users must have at least $10,000 across their accounts, and they have an application continually running on the standby to check for this.
for (( i = 0; i < 1000 ; i++ )) do ysqlsh -h $target_ip -w -c "SELECT SUM(balance) FROM balances WHERE name = ‘Rahul’; done
If the value drops below $10,000, the customer that hasn’t met the minimum balance requirement is charged a service fee. Let’s see what happens when no read time is set on the standby cluster:
$9900 count: 194 $10000 count: 632 $10100 count: 163 Restart read count: 11
Now, let’s turn on transactional consistency by setting the read time equal to the minimum caught up time and seeing what happens:
$9900 count: 0 $10000 count: 1000 $10100 count: 0 Restart read count: 0
When the standby safe time is not used, the balance often drops below $10,000. Sadly, this means I would be incorrectly charged. When standby safe time is used, the balance will equals $10,000 and the bank will not charge me.
Conclusion
YugabyteDB is excited to preview transactional consistency on an async standby in our 2.17.1 release. It is achieved by reading at a consistent timestamp equal to the minimum caught up time across all tablets in the database.
But, we are not done. We are planning future work to support active/active setups, hub and spoke topologies, plus full database replication through DDL replication. Stay tuned for upcoming developments!
Additional Resources
This blog provides a brief introduction to cross cluster replication. To learn more, take a deep dive into our overview and documentation pages.
Interested in trying out some of these concepts? YugabyteDB offers a fully managed YugabyteDB-as-a-Service Start a free trial today.


