How Plume Handled Billions of Operations Per Day Despite an AWS Zone Outage
November 26, 2019
Enterprises deploy YugabyteDB clusters across multiple availability zones (AZs) in order to ensure continuous availability of their business-critical services even when faced with cloud infrastructure failures like zone outages. On November 12, 2019, there was one such outage of an entire availability zone in the eu-central-1 region of AWS. This was reported on the AWS status page on that day, along with an official update.
In this post, we are going to look at how a Yugabyte customer, Plume, survived this recent AZ outage without any application impact. We’ll also dive into how the incident played out in their environment and what had to be done to recover from the outage.
What’s Plume? Plume enables ISPs to offer smart home and related services to their customers. Its platform powers millions of smart homes that generate over 27 Billion operations per day served by YugabyteDB.
How the AWS outage played out for Plume
12:07am PST: Although Plume’s operations team was already aware of the AZ failure, Yugabyte Platform alerted them based on pre-configured monitors. This was even before the AWS status page was updated!
12:16am PST: About 30 minutes after the first alerts were fired, the AWS status page was finally updated to reflect the outage.
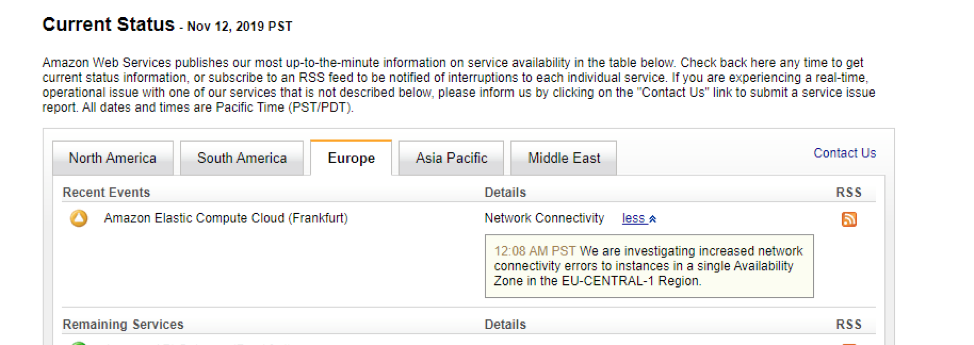
1:04am PST: Yugabyte support team gets on a call with Plume to review the status of the database clusters. Plume confirmed that multiple clusters had simultaneously lost all the nodes present in the zone that experienced the outage. Since all of these clusters were multi-AZ deployments, the database itself was not affected by the outage in terms of serving reads/writes and data consistency.
Around this time, the network connectivity of the instances was mostly restored. However, this did not immediately lead to normal status across all clusters.
- The clusters running on local attached disks (instances of the i3 type) recovered automatically once the AZ failure was fixed by AWS.
- The clusters running on nodes with EBS volumes (instances of the c5 type) were still experiencing issues because the impact to this service was not yet resolved.
AWS posted an update about this only an hour later at 2:15am PST.
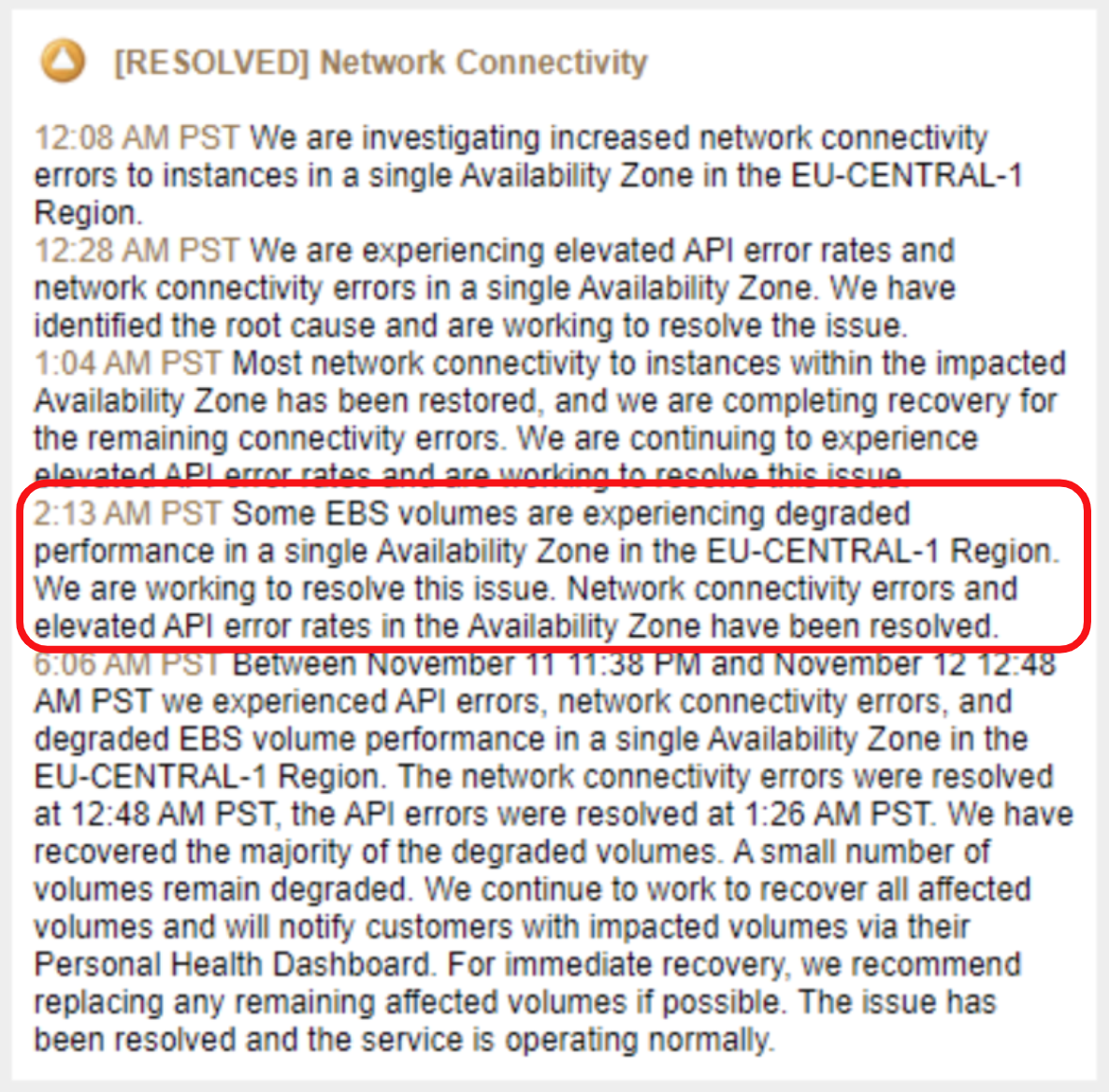
2:30am PST: The issue with EBS volumes seem to have been fixed on the AWS side. However, not all instances recovered fully, the unhealthy instances were automatically flagged by the Yugabyte Platform. Upon digging deeper, the following surfaced:
- One node with EBS disks had recovered but the disk itself was not mounted, and hence this node was not a part of the cluster. Since the number of nodes operational was lower than the number of nodes desired, Yugabyte Platform triggered a new alert. Mounting the disk had to be done manually, after which the automatic re-replication of data in YugabyteDB brought the cluster back to normalcy.
- Another node was not reachable via ssh even though the AWS console showed it to be healthy. But by this point, all of the data in this unreachable node was already safely replicated to the other nodes in that AZ. With just a couple of button clicks from the Platform UI, the unresponsive node was decommissioned and replaced with a newly provisioned one. Once again, the cluster automatically rebalanced itself fully soon after.
3:23am PST: All the alerts were resolved, the Plume services and the entire fleet instances running YugabyteDB were confirmed to be running smoothly. This concluded what needed to be done to fix the outage, including posting the summary of the incident!
No data was lost, and the database tier was running and available to perform read or write queries the entire time including when the az-outage had happened.
How does YugabyteDB handle zone outages?
The following sequence explains how a multi-AZ deployment of YugabyteDB works, and what happens when a zone fails.
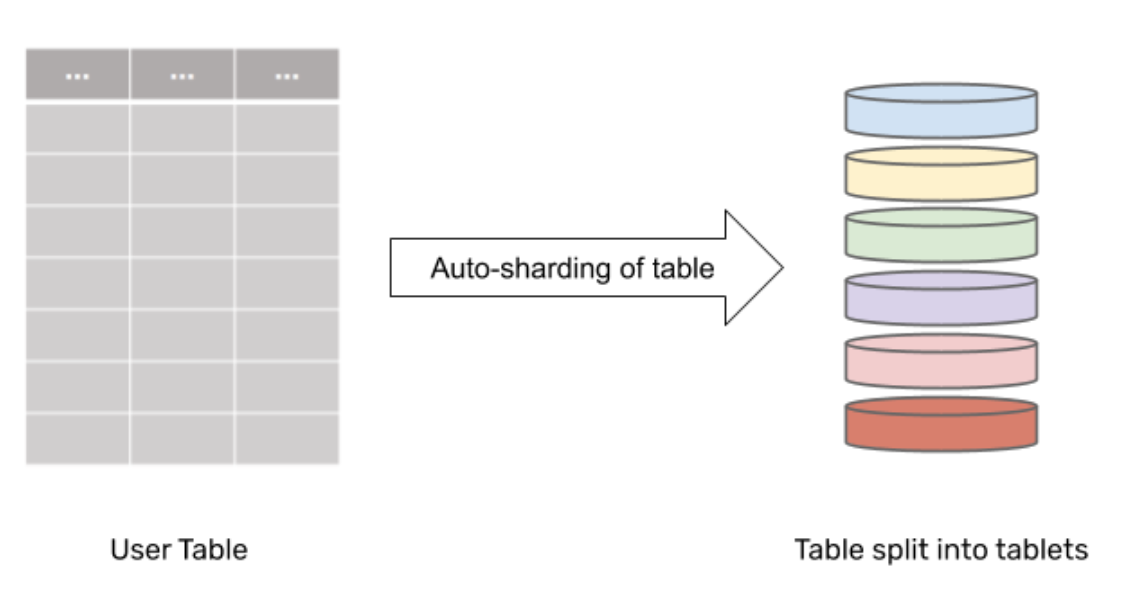
1. Automatic data sharding
YugabyteDB transparently shards the data of any table into multiple tablets, each tablet containing a subset of rows from the table.
2. Raft-based replication
The data in each of these tablets is replicated across multiple AZs using the Raft consensus algorithm. All the read and write queries for the rows that belong to a given tablet are handled by that tablet’s leader.
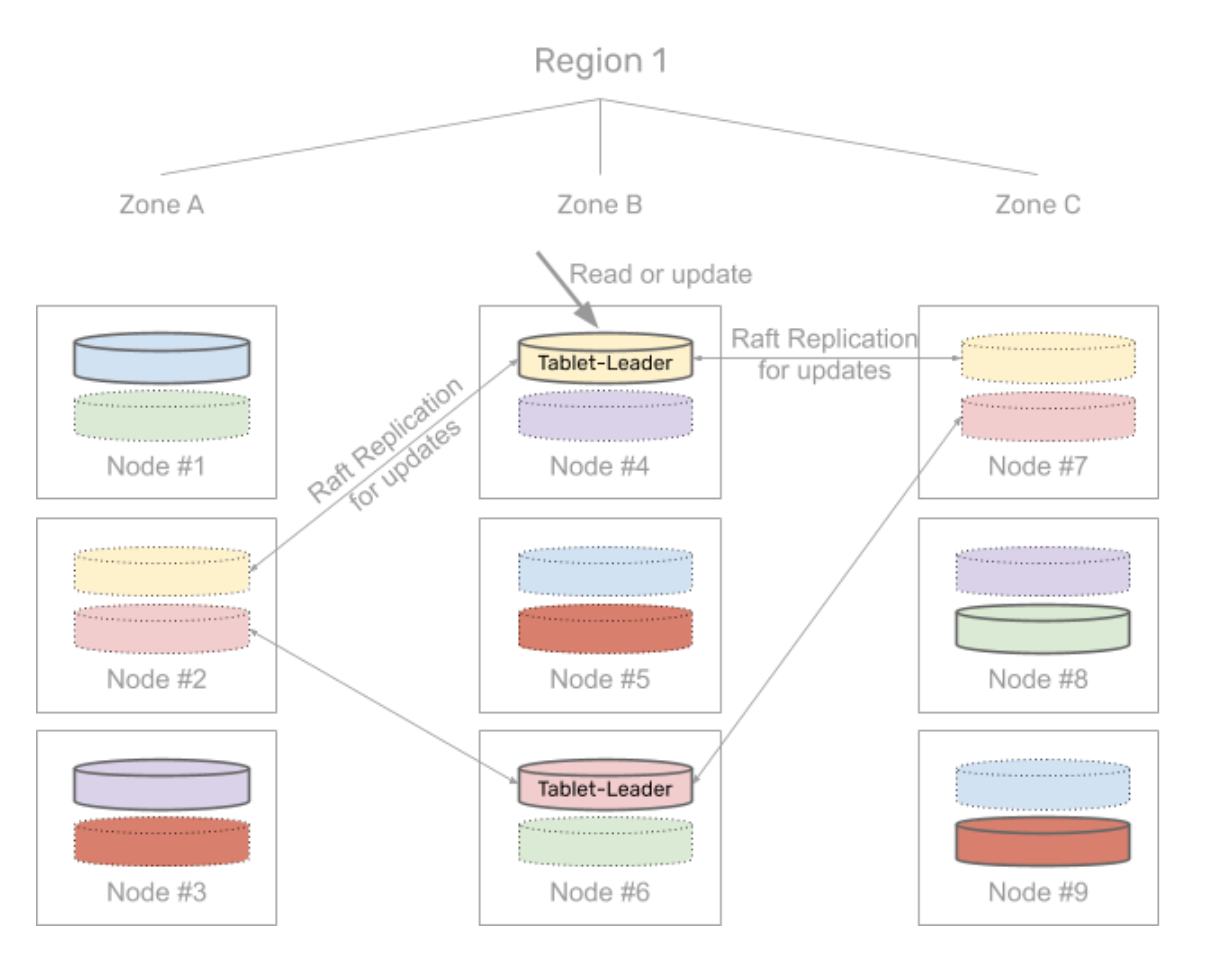
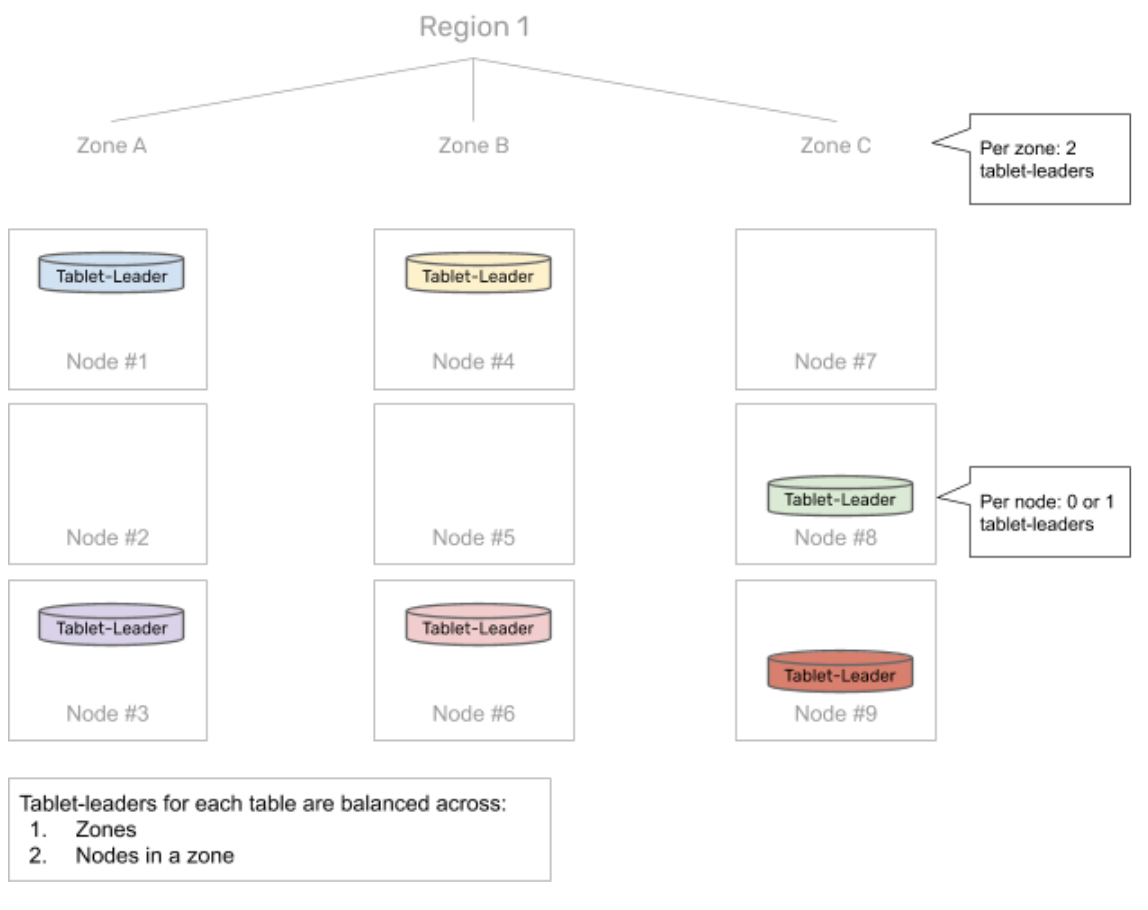
3. Optimal tablet-leader placement
As a part of the Raft replication, each tablet-peer first elects a tablet-leader responsible for serving reads and writes. The distribution of tablet-leaders across different zones is determined by a user-specified data placement policy. The placement policy in the scenario described above ensures that in the steady state, each of the zones has an equal number of tablet-leaders.
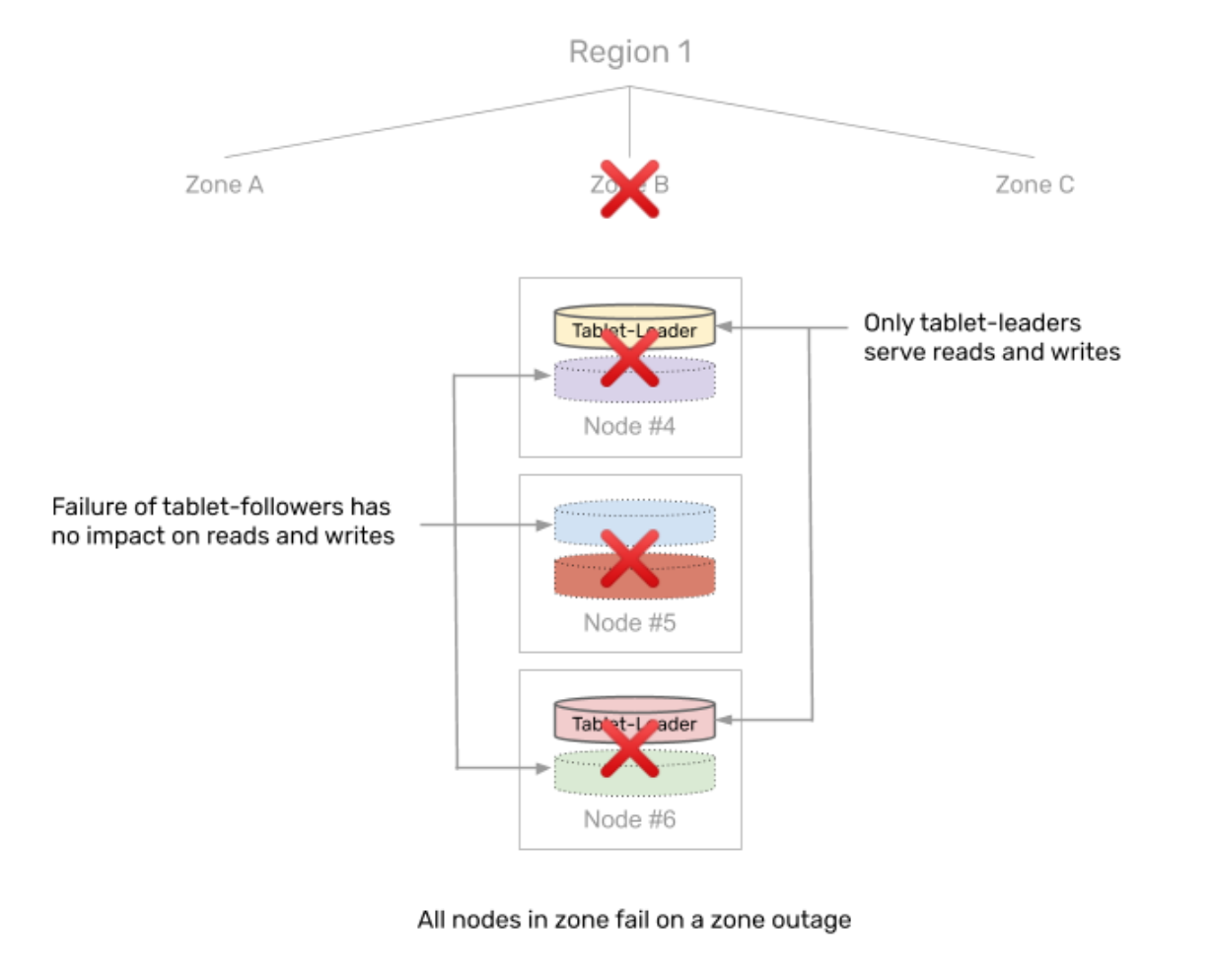
4. Impact of a zone outage
As soon as a zone outage occurs, all nodes in that AZ become unavailable simultaneously. This results one-third of the tablets (which have their tablet-leaders in the zone that just failed) not being able to serve any requests. The other two-thirds of the tablets are not affected.
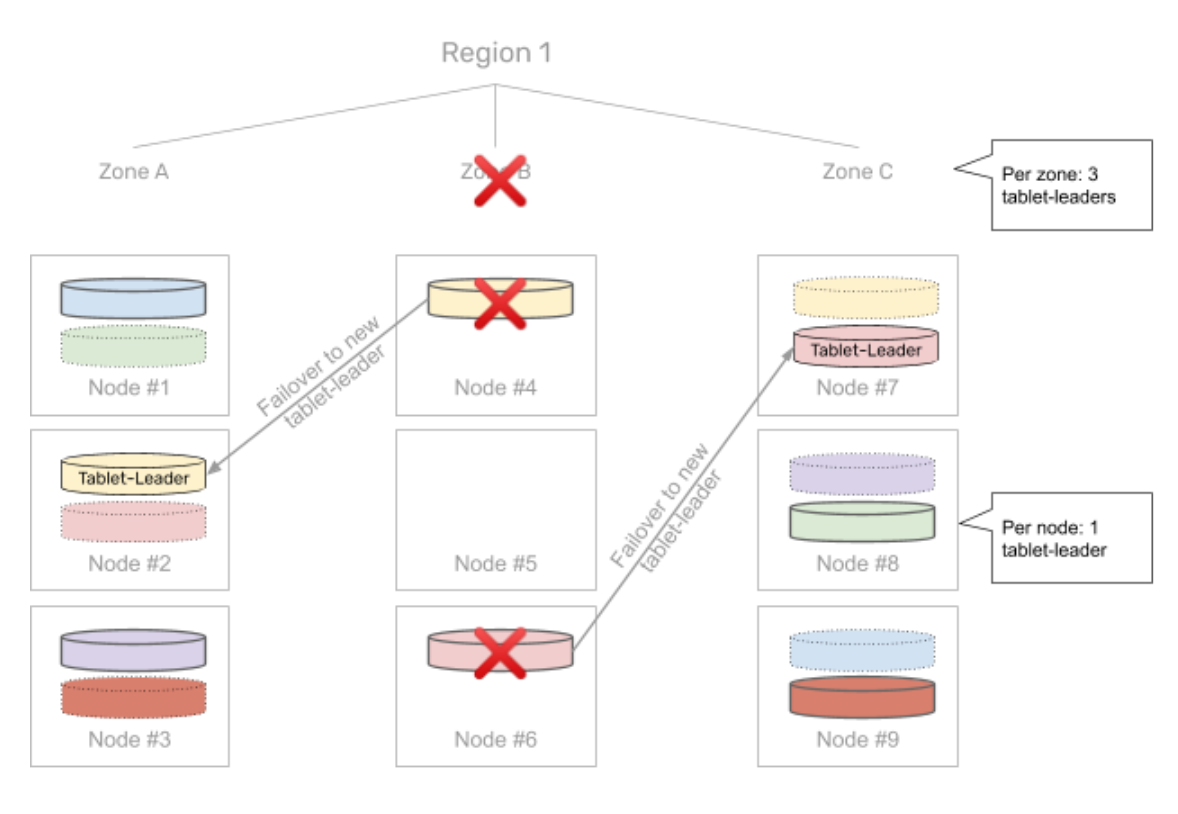
5. Automatic failover in seconds
For the affected one-third, YugabyteDB automatically performs a failover to instances in the other two AZs. Once again, the tablets being failed over are distributed across the two remaining zones evenly.
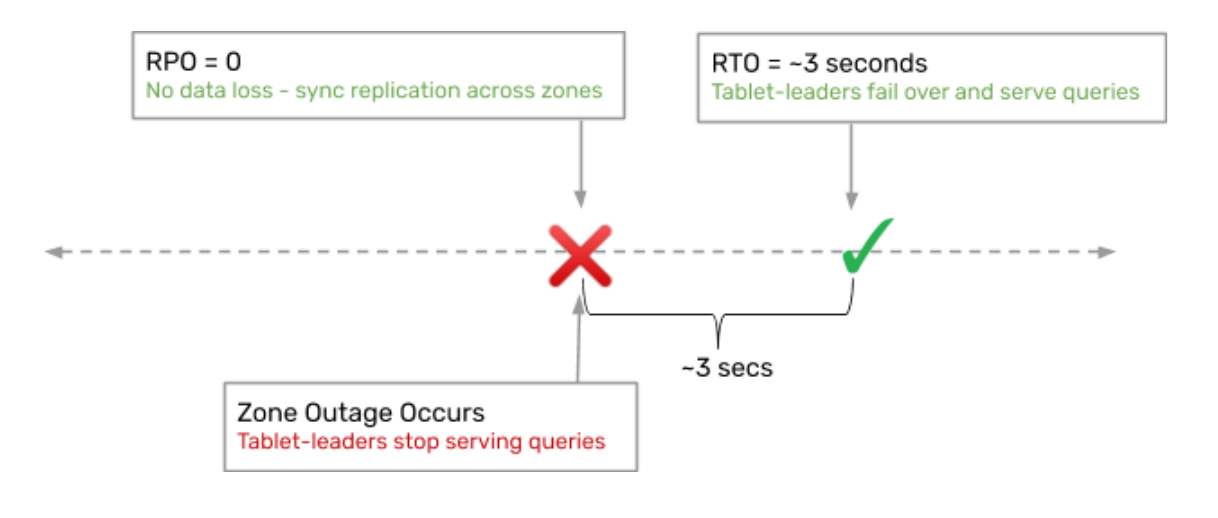
6. RPO and RTO on a zone outage
The RPO (recovery point objective) for each of these tablets is 0, meaning no data is lost in the failover to another AZ. The RTO (recovery time objective) is 3 seconds, which is the time window for completing the failover and becoming operational out of the new zones.
Multi-AZ is just the first step
While multi-az deployments (zero data loss with an RPO of 0 and high availability with an RTO of a few seconds) are fast becoming a necessary requirement for cloud-native databases, they are by no means sufficient. A number of other deployment scenarios are becoming very commonplace, as shown below.
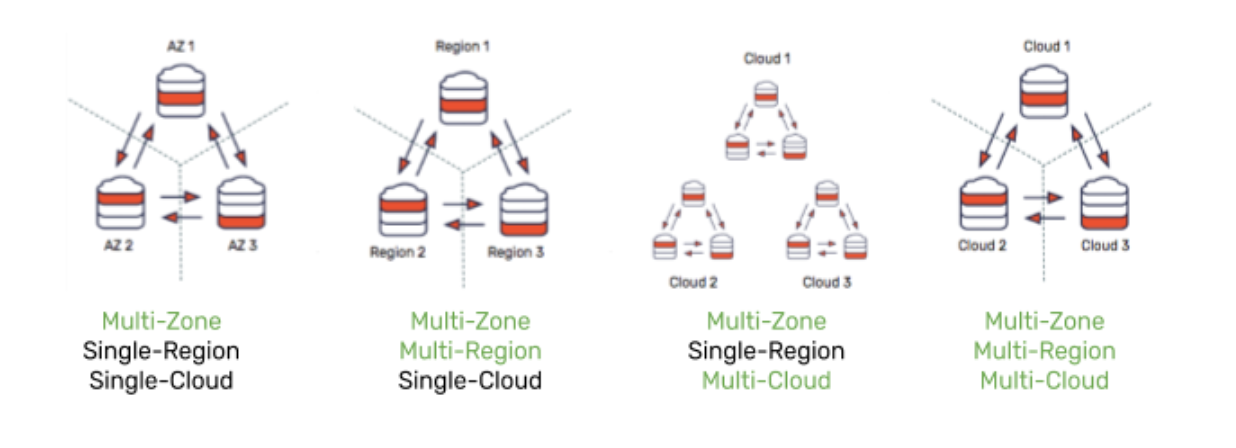
For each of these deployment paradigms, there is also a choice of how to replicate data based on what it needs to guarantee. By default, YugabyteDB chooses synchronous replication ensuring zero data loss.
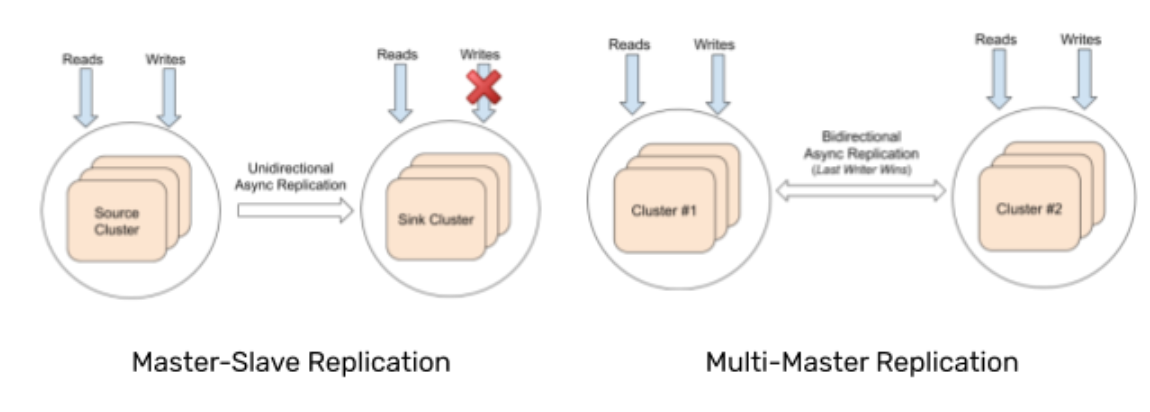
YugabyteDB can also support asynchronous replication schemes between clusters such as active-passive (master-follower) and active-active (multi-master).
What’s Next?
- Compare YugabyteDB in depth to databases like CockroachDB, Google Cloud Spanner and MongoDB.
- Get started with YugabyteDB on macOS, Linux, Docker, and Kubernetes.
- Contact us to learn more about licensing, pricing or to schedule a technical overview.


