Introducing New YugabyteDB Functionality for Ultra-Resilient AI Apps
July 22, 2025
It’s tempting to consider AI-powered applications as being fundamentally different from traditional enterprise software. Augmenting apps with GenAI functionality is, after all, pretty new and unique. The AI app-building landscape is changing by the week, and dreaming about possible benefits is part of the fun.
In this blog, we examine the current and future AI landscape and share the benefits of the new and enhanced AI functionality introduced in the latest release.
Rapid AI Innovation
Many of us are focused on new and innovative AI projects, especially as more organizations request that employees investigate which AI tools they can use (or build) to be more productive. This might include:
- Rapid prototyping
- Spinning up practical examples of agentic AI
- Using a new MCP server to merge business with GenAI functionality
This “AI Experimentation” stage is all about trying new things and seeing what works. But what happens when one of these experiments succeeds and needs to become “real” enterprise software? And what happens when an existing, mission-critical application needs to be modernized to include GenAI functionality?
Yugabyte co-founder and co-CEO, Karthik Ranganathan, addresses these topics in his recent Distributed SQL Summit keynote, but one thing is crystal clear: the experimental phase of AI is tapering off, and the era of production-ready, enterprise-grade AI applications is beginning.
The RAG Challenge: Why Standalone Vector Databases Fall Short
Many AI-powered application innovations utilize a Retrieval-Augmented Generation (RAG) architecture. By combining the power of large language models (LLMs) with your organization’s proprietary business data, RAG functionality using powerful vector search modernizes applications that require GenAI or Agentic AI.
However, as organizations move beyond proof-of-concept to production, the limitations of the standalone vector databases that many teams adopt to build these apps become painfully clear.
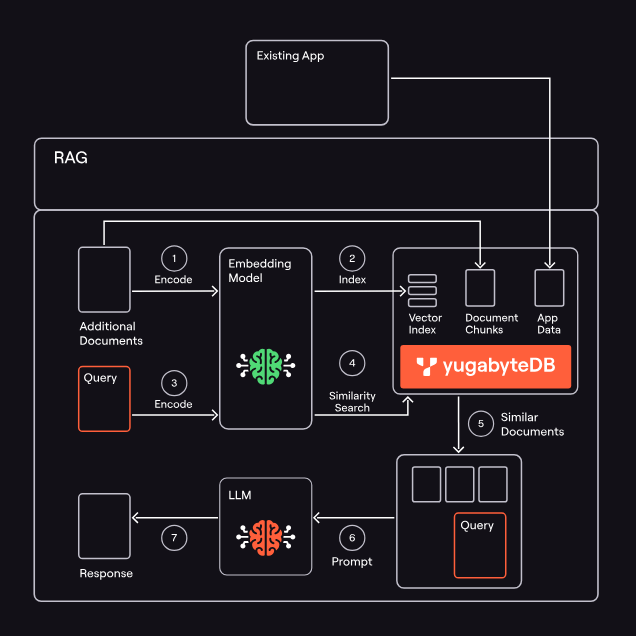
Standalone vector databases often operate through APIs, creating a constant risk of data drift between your operational database and your vector store. When your business data updates in PostgreSQL but your vector embeddings lag behind, you’re not just dealing with stale data; you’re potentially serving incorrect information to your AI applications. As users demand accurate, non-hallucinogenic LLM-derived information, introducing additional data errors leads to customer complaints and reputational damage.
Compliance and Security Issues
Most standalone vector databases were purpose-built for similarity search, which they do fairly well. However, they lack many fundamental database features that enterprise applications require. Without ACID compliance, you can’t ensure data consistency across transactions. Without row-level security, you can’t meet compliance requirements. Without proper backup and recovery mechanisms, you’re one system failure away from losing critical embeddings that may have taken hours, days, or even longer to generate.
Performance at Scale
Performance becomes another concern at scale. While standalone vector databases might deliver impressive query times in isolation, they introduce challenges when your application needs to join vector search results with relational data. In a RAG application, this isn’t just a nice-to-have…it’s essential. Your AI application doesn’t just need to find similar documents; it needs to join that information with user permissions, content metadata, and business context stored in your relational database.
AI Workload Complexity
Perhaps most critically, standalone vector databases struggle with the operational complexity of modern AI workloads. As your vector collections grow from thousands to millions to billions of vectors, managing multiple database systems becomes exponentially more complex. You’re not just scaling one system; you’re scaling multiple systems that must remain in perfect synchronization.
Enhance Your AI App Development With New YugabyteDB Functionality
YugabyteDB addresses these challenges by combining the familiarity of PostgreSQL with enterprise-grade vector search capabilities in a single, ACID-compliant system. This architectural approach not only simplifies your infrastructure but also:
- Ensures data consistency
- Provides robust security features
- Delivers the performance needed for complex AI workloads that require joining vector search results with relational data at scale.
We’ve added several new features to make AI app development easier and more flexible with YugabyteDB.
Expanded AI Ecosystem
Yugabyte recently launched powerful new Vector Search functionality for YugabyteDB, architected for 1+ billion vectors. We’ve also been busy building connection points to the larger AI ecosystem, adding integrations for LangChain, OLLama, LlamaIndex, AWS Bedrock, and Google Vertex AI.
YugabyteDB MCP Server
The YugabyteDB MCP Server is an open-source MCP server that makes it easy for teams to build RAG applications using YugabyteDB. This lightweight, Python-based server allows LLMs like Anthropic’s Claude to interact directly with your YugabyteDB database.
You can read more in this blog, ‘Introducing the YugabyteDB MCP Server: A Hands-On Demo of Claude Interacting With YugabyteDB.’ The YugabyteDB MCP Server is also available on the AWS Marketplace in the new AI Agents and Tools category.
YugabyteDB MongoDB API
This new multi-modal app dev capability (in Beta) is powered by Microsoft’s DocumentDB extension and made possible by YugabyteDB’s enhanced PostgreSQL compatibility. Teams now have even more options when building cloud native and AI-powered modern applications. Discover more in this recent blog, ‘Getting Started with MongoDB API in YugabyteDB.’
The “Halfgres” Trap: Avoiding Low Postgres Compatibility
“Leadership asked us to add AI to our application, and we don’t know where to start.”
We’ve heard this, or a variation of this, from many YugabyteDB customers and prospects. Some of the organizations we’ve talked to have turned to databases that promise a certain level of PostgreSQL compatibility, plus some vector capabilities.
On the surface, this seems like the perfect solution. You get a familiar PostgreSQL experience combined with the scalable vector search capabilities you need for AI applications.

So, What’s the Catch?
Karthik’s DSS Asia keynote highlights the significant difference between syntax compatibility and true PostgreSQL runtime compatibility.
When you’re building next-gen AI-powered applications, any added burden on developer and operations teams hinders your ability to build and iterate quickly. This is a non-starter in the hyper-competitive markets in which we all now compete. It’s doubtful that the “add AI to our application” mandate includes time rebuilding functionality (and not innovating).
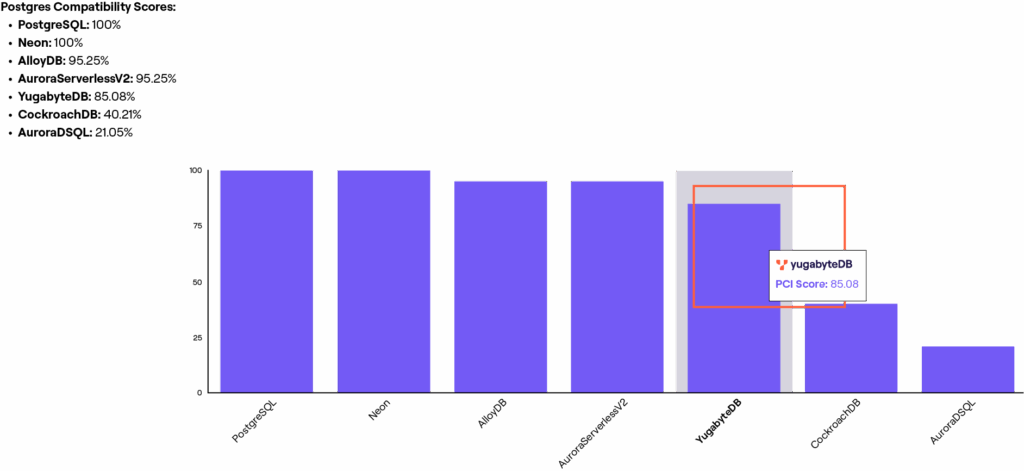
You can think of “halfgres” as a database that claims to be Postgres-compatible, but actually has low Postgres compatibility. The halfgres problem manifests in several ways. Some databases can parse PostgreSQL syntax but execute it differently, leading to subtle behavioral differences that can break existing applications. Others support basic PostgreSQL features, but handle advanced capabilities differently, creating unexpected failure modes when you most need high performance.
More fundamentally, many PostgreSQL-compatible databases weren’t designed to meet the cloud-native, distributed architecture demands of modern AI applications. They might offer some vertical scaling and basic high availability, but they can’t deliver the horizontal scalability, multi-region distribution, and zero-downtime operations that enterprise AI applications require.
Avoiding the Trade-offs
So, do you compromise on PostgreSQL compatibility to get cloud-native scalability?
Doing this can be painful if you’re migrating an existing application. From assessment to schema to data migration, additional time spent resolving compatibility issues is time you’re not spending on new AI functionality.
Your software teams should not need to compromise on scalability, resilience, or PostgreSQL compatibility when developing AI-powered applications. YugabyteDB has several new features that ensure they don’t have to.
Enhance Scalability, Resilience, and PostgreSQL Compatibility with New YugabyteDB AI Functionality
New PostgreSQL Compatibility Features (GA)
Several new Postgres compatibility features are now generally available in YugabyteDB, including generated columns, foreign keys on partitioned tables, and multi-range aggregates for enhanced data modeling and querying. You can read more about these features here.
Online Upgrades and Downgrades Across Major PostgreSQL Versions (GA)
We’re announcing the GA of online upgrades and downgrades across major PostgreSQL versions. This means you can stay current with the latest PostgreSQL innovations – including new AI-related extensions – without downtime or complex migration projects. You can read more about these features here.
YugabyteDB offers superior PostgreSQL compatibility by reusing PostgreSQL’s query layer code. This approach allows YugabyteDB to retain all the power and familiarity of PostgreSQL, pairing its trusted API with a precision-engineered, distributed, cloud-native architecture.
Essentially, YugabyteDB provides you with distributed PostgreSQL for AI-ready, cloud-native applications.
A Sneak Peek at Yugabyte’s Vision for the Future
In his DSS Asia keynote, “Hello from the Year 2027,” Yugabyte CEO Karthik Ranganathan (and a surprise guest) takes you on a journey through the AI application architecture of the (not-too-distant) future. Drawing from his experience scaling Facebook’s database infrastructure and leading YugabyteDB’s evolution, Karthik reveals why the current experimental phase of AI is ending and what comes next.
He addresses some of these practical (and maybe existential?) questions:
- How many applications will need to be updated for AI-readiness?
- How will LLM models evolve and be regulated?
- What is the practical impact on developers/operators?
- Is the RAG architecture here to stay (spoiler: maybe not?)
- What happens when we need to scale apps in seconds, not months?
- Can ops keep up with manual performance tuning requirements?
- What options will be available for users who want to switch apps?
Planning For Tomorrow, Today!
As we look toward the future, one thing is clear: the AI applications that will dominate the market won’t be data science projects anymore. They’ll be built on platforms that can deliver true PostgreSQL compatibility, enterprise-grade resilience, and the scale needed for billion-vector workloads.
You’ll be able to quickly build robust AI applications that scale from thousands to billions of vectors using familiar PostgreSQL and powerful vector search capabilities, without architectural changes.
We are excited about AI’s potential to improve efficiency, accuracy, and innovation. In the spirit of embracing the future, we are just about to run our own internal hackathon, which will focus on building better AI functionality for our customers and internal teams.
So, let’s raise a toast to the current (and perhaps already past) age of AI experimentation. It was fun for a while!
The future of AI applications will be more than just having the right models; it will be about building a data infrastructure that doesn’t compromise on Postgres compatibility, resilience, or scale.

Learn more about the latest YugabyteDB in our press release, ‘YugabyteDB Extends its Vector Search Functionality and PostgreSQL Compatibility for AI App-Developers.’


