Presentation Recap: The Art of the State: Serverless Computing and Distributed Data – Joe Hellerstein, UC Berkeley and Trifacta
December 8, 2020
We were delighted to have Joe Hellerstein, professor of Computer Science at UC Berkeley and co-founder and Chief Strategy Officer at Trifacta, give the day 2 opening keynote at this year’s 2020 Distributed SQL Summit.
If you weren’t able to attend or want a refresher, here’s the summary and playback of his keynote presentation.
Joe presented the the art of the state serverless computing and distributed data in four chapters:
- 1. The state of serverless computing today
- 2. A key issue in performance and correctness of distributed systems—avoiding coordination
- 3. The CALM theorem, which describes when exactly you can correctly avoid coordination
- 4. Current, practical work happening in the Rise Lab at Berkeley, the Hydro project, to address topics like stateful, serverless computing, and more
We recap the presentation by each chapter below.
Serverless Computing
Joe explains that historically in computer science, every platform eventually inspires a programming model to unlock the true power and potential of that platform.
Examples include: C and UNIX unlocked the power of the minicomputer; the Chapel language did the same for supercomputers; the WIMP interface helped unlock the potential of graphical programming and personal computers; and most recently new programming environments (like Swift and Android) have made it easy to develop applications for mobile, unlocking new experiences that few would have predicted would even be possible on a telephone.
Although the cloud as a platform arose around the time of mobile, Joe explains, “somehow the cloud doesn’t have a programming environment that is native to it that enables people, third-party developers, to produce things we never would have expected.”
Why? Joe states, “Distributed programming is really hard.” Add autoscaling into the mix and it becomes even harder. But now, the idea of programming the cloud—serverless computing—is becoming tremendously popular.
Joe defines serverless computing as, “it’s usually presented to users in the form of functions-as- a-service. It’s an idea for allowing developers outside of the cloud platform to program the cloud, give them access to thousands of cores, petabytes of RAM, and allow them to have programs that have fine-grained resource usage and efficiency as their application needs change.”
Here’s an example of a Python function-as-a-service (FaaS) from AWS:
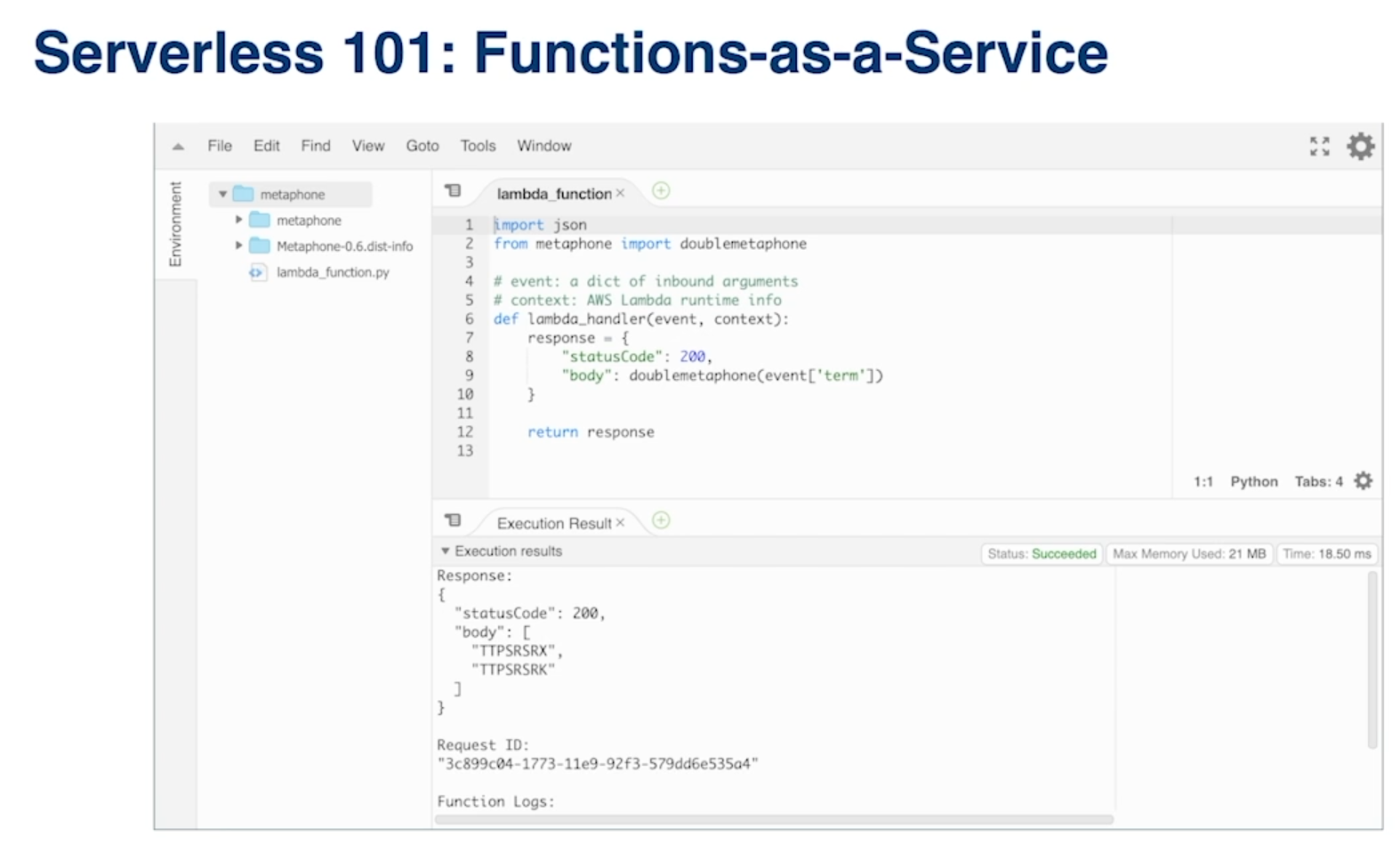
It’s a step forward in that it solves the autoscaling problem; it’s also two steps back in that several things are still missing. As noted in the CIDR 2019 paper and explained by Joe, “You can’t get access to massive amounts of data and you can’t build unbounded, distributed computing programs with the current state of FaaS.”
Key limitations include:
- Very large I/O bottlenecks for FaaS functions
- 15 minute lifetimes means functions don’t have session context across these short lifetimes (Joe explains “when your function goes down and it comes back up, which it will do, it’s forgotten everything it ever knew”)
- There is no inbound network communication allowed for these functions. According to Joe, “This is probably the most critical limitation. So these functions cannot actually talk to each other over the network.”
There is a workaround to these limitations (as stated on Joe’s slide – “‘communicate’ through global services on every call”), but it is slow and expensive due to the I/O bottleneck limitation.
Avoiding Coordination
Joe shifts gears and talks about fundamentals today around avoiding coordination. A first step in improving FaaS functions is to make them stateful, which Joe describes “to allow them to have state that persists across runs; so of course, program state is really data.” Managing data in distributed, autoscaling systems has a couple challenges, the more challenging one is distributed consistency—ensuring that distant agents will or eventually will agree on common knowledge.
Classical mechanisms exist to fix consistency issues and are found in a category called coordination. Coordination examples include consensus protocols like Paxos, and two-phase commit in database systems.
With Paxos, programming it into an application is very tricky, and therefore not suitable for broad use. Instead, Joe quotes one of the heroes of modern computing:

Having to program coordination into an application introduces significant application delays as services wait for coordination to occur. The delays can further cascade in large distributed, cloud-based systems as more and more services wait for each other, and should therefore be avoided when building and developing applications in the cloud. On the path to the solution is this idea Joe proposes, “to … raise the level of abstraction from I/Os to application semantics.”
Ideally, coordination-free programs should be freely built and run in the cloud; and all other programs requiring coordination, application teams need to be, as Joe states, “very careful with these programs to make sure that we don’t try to scale them in ways that they won’t scale.”
Now the question is, how can we tell what programs are coordination-free vs not coordination-free and therefore require implementing Paxos or other coordination mechanisms? The answer to this is found in the CALM theorem.
CALM Theorem
Joe defines CALM as follows:

Joe defines monotonicity: “Pretty simply, monotonicity is the property that if the input to the program grows, then the output to the program grows. And in particular, what that means is that if you’re running a program and it gets more input, it only will produce more output. In particular, it will never need to retract an output that it gave the subset of the input.”
To help us better understand monotonicity, Joe describes programs that are non-monotonic, and then compares the two: “non-monotonic programs have to wait till they get their complete inputs to decide what are legal outputs. By contrast monotonic programs can start producing outputs immediately when they get inputs. Intuitively, then this is why monotonic programs can run without coordination.”
More details can be found in the article by Joe Hellerstein and Peter Alvero featured in CACM September 2020, “Keeping CALM: When Distributed Consistency Is Easy”.
Why should you care about the CALM theorem? Joe explains, “if you really embrace monotone programming, you could build some crazy fast, infinitely auto-scaling systems because when there’s no coordination, when no thread ever waits for any other thread, you get insane parallelism and very smooth scalability.”
For those who are familiar with the CAP theorem, Joe describes the relationship between CAP and CALM: “the CAP result is all about non-monotone programs—about the full space of potentially non-monotone programs; but the CALM programs, the ones that are monotone, actually can enjoy all three of consistency, availability, and partition tolerance at the same time.”
In addition, there is a distributed programming language called Bloom that allows you to check for monotonicity. Finally, you can read more on all of these concepts in the CACM article.
Current Work at Berkeley: Hydro, a Platform for Programming the Cloud
In Joe’s research group at Berkeley, they are working on a multi-component stack that they’ve been building bottom-up to help make programming the cloud easier.
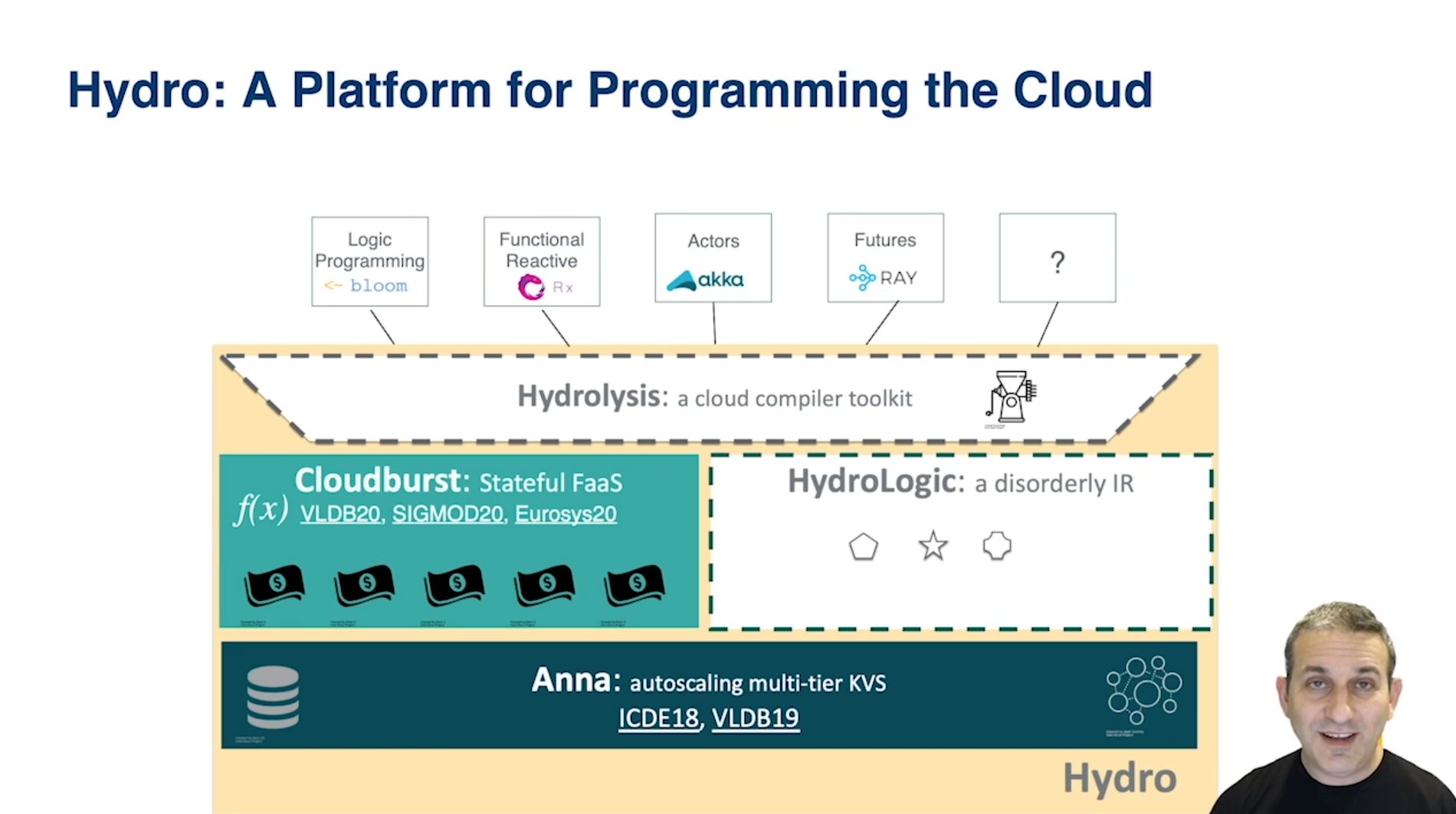
At the bottom is Anna, an autoscaling key value store, an exciting project that bakes CALM consistency into the system, which gives it a lot of advantages including unprecedented performance. Because of it’s coordination-free consistency, under contention Anna greatly outperforms Masstree, Intel TBB, and Cassandra. Why? Anna spends time doing, while the other systems spend time waiting for coordination. You can find the performance comparison starting at 20:52 in Joe’s presentation.
Next, Joe describes Cloudburst, the stateful serverless platform built on Anna, to decouple compute and storage in order to scale each independently, while also maintaining consistency across caches (using a new protocol called Hydro cache). Joe walks us through the performance (latency) numbers of running prediction serving on Cloudburst (basically, running a machine learning model in the cloud) vs other systems (single-node, native Python; AWS SageMaker; AWS Lambda). Cloudburst is second to single-node, native Python and has significantly lower latency than the two AWS systems tested. You can find the performance comparison starting at 24:12 in Joe’s presentation.
Even more work is being done within the Hydro Project on top of Cloudburst and Anna, unlocking the potential for even more innovation, all based on serverless computing at the core.
Finally, even though stateful FaaS is a major step forward in serverless computing, it’s still a limited API that has its own limitations to be worked through. As Joe states, “the real dream is going to take time.”
You can learn more about the Hydro Project, follow along, and join in on GitHub. And make sure to check out Joe’s full Distributed SQL Summit keynote presentation on Vimeo.
Want to see more?
Check out all the talks from this year’s Distributed SQL Summit including Pinterest, Mastercard, Comcast, Kroger, and more on our Vimeo channel.
 Scenarios and the Multi-Tenancy Options That Support Them")

