Rapid Data Recovery: Restore a 15TB YugabyteDB Database From an Amazon S3 Backup in 30 Minutes
April 9, 2024
Efficiency and reliability are crucial in database management. Every minute of downtime can cost the company a lot of money and negatively impact its reputation. Robust backup and recovery solutions are essential for mitigating data loss and enabling swift operational recovery. In this blog post, I will demonstrate how to restore a massive 15TB YugabyteDB database from an Amazon S3-based backup in less than 30 minutes.
When Disaster Strikes: The Importance of Rapid Data Recovery for Databases
In situations where hardware failures, human errors, data center outages, or regional outages compromise essential data, rapid data recovery is paramount to avoid financial losses and reputational damage. YugabyteDB, a distributed PostgreSQL database engineered for massive workloads and high availability, provides advanced backup and restore capabilities. Its distributed architecture ensures data is restored swiftly, minimizing downtime and disruption when disaster strikes.
How YugabyteDB Database Ensures Rapid Data Recovery
Configuring the Cluster
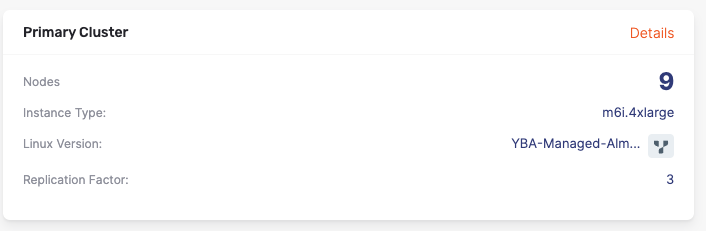 To begin, I created a database cluster using our self-managed deployment of YugabyteDB(i.e. YugabyteDB Anywhere) consisting of nine M6i.4XLarge EC2 instances spread across 3 availability zones, each having a 3 TB EBS volume configured with 6000 IOPS and 1000 MB/sec throughput. This distributed configuration ensures data redundancy and fault tolerance, crucial for maintaining data integrity and availability. The database itself has 3 tables (shown below).
To begin, I created a database cluster using our self-managed deployment of YugabyteDB(i.e. YugabyteDB Anywhere) consisting of nine M6i.4XLarge EC2 instances spread across 3 availability zones, each having a 3 TB EBS volume configured with 6000 IOPS and 1000 MB/sec throughput. This distributed configuration ensures data redundancy and fault tolerance, crucial for maintaining data integrity and availability. The database itself has 3 tables (shown below).

Swift Restoration: Leveraging yb-controller for Rapid Data Recovery
In this scenario, a disaster or critical event has resulted in the loss of the original cluster. However, thanks to the backup strategy leveraging S3 storage, administrators can confidently initiate the recovery process.
I created the 9-node cluster in 6 minutes and, utilizing the yb-controller, restored a 15 TB Yugabyte database across the 9 nodes in just 30 minutes and 52 seconds (see screenshot below). This highlights YugabyteDB’s scalability and demonstrates its ability to handle massive datasets and recover swiftly from backups stored in the cloud. Adding cluster creation time, RTO (Recovery Time Objective) is approximately 37 mins. Notably, the data is fully restored without the need for background rehydration, meaning that the database is ready to go back into production with no performance loss.
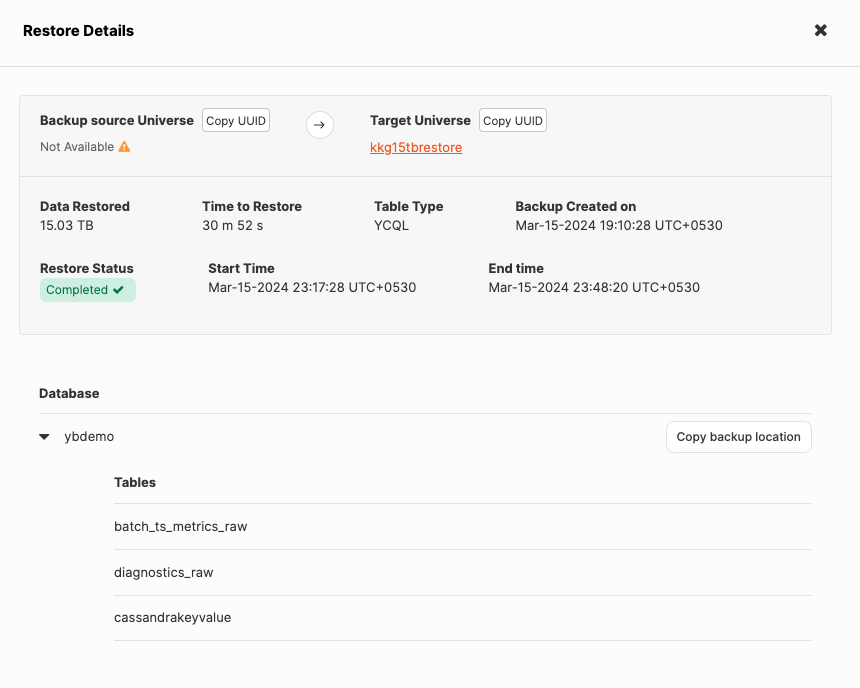
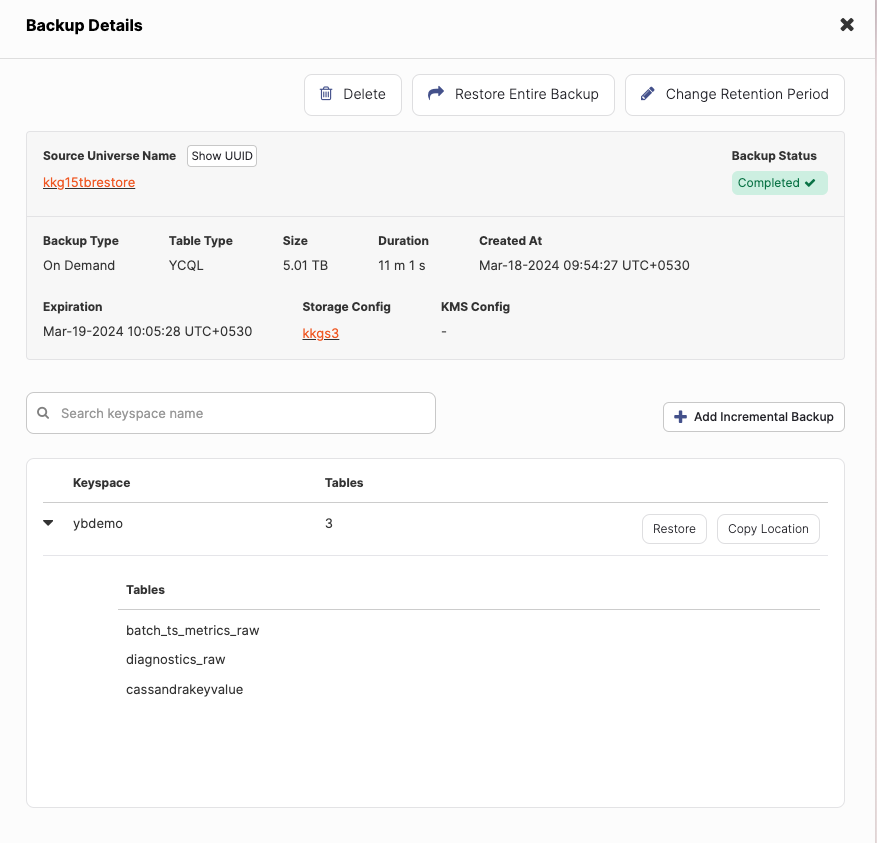
Database Backup in a Flash: Securing Data in 11 Minutes
But what about the backup process itself? When it comes to data management, speed and efficiency are crucial to minimize potential disasters. YugabyteDB enables database administrators to quickly create backups, ensuring readiness for any scenario.
In my setup, backing up the entire 15 TB database took just 11 minutes, thanks to advanced backup mechanisms and streamlined processes. Note that the size of the backup is 5TB since the replication factor (RF) for this cluster is 3. This rapid backup process securely stores critical data in S3, ensuring immediate availability for retrieval in the event of unforeseen circumstances.
What is yb-controller and How It Enables Unprecedented Efficiency
Now, let me walk you through the technology behind this swift data recovery process: yb-controller. Released with YugabyteDB 2.16, yb-controller brings unparalleled efficiency and reliability to backup and recovery processes.
yb-controller orchestrates the entire data recovery process, leveraging cloud storage and YugabyteDB’s distributed architecture. Its intelligent algorithms and parallel processing capabilities enable swift retrieval and restoration of the 15 TB database from S3 storage across nine instances in just 30 minutes, highlighting its scalability and efficiency in managing massive datasets.
YugabyteDB users can trust yb-controller for complete data protection and quick recovery (within minutes), even in the face of the most challenging scenarios. Whether it’s restoring a 15 TB database from an S3-based backup or creating backups in record time, yb-controller revolutionizes the way businesses approach data recovery.
When the YugabyteDB Anywhere initiates backups, it assigns one of the yb-controllers as the orchestrator, to create snapshots* and identify nodes with tablet leaders. The orchestrator then delegates the upload to each of the yb-controller’s on the nodes that have the respective tablet leaders. A success marker file, containing backup metadata, is uploaded once the backup is completed. During restore, the process is done in reverse, with the addition of writing data for all replicas of each tablet.
*NOTE: The process for taking snapshots, moving them to external storage, and restoring from backups is detailed in the documentation for YSQL and YCQL.
The time needed for restore depends on several factors such as the size of data, the number of nodes, the number of cores per node, the replication factor, the number of tables, the number of tablets in each table, the number of cores in each node, the disk throughput, disk IOPS, etc. Of these, the most important factors are:
- Number of nodes
- Replication factor
- Disk throughput
- Size of backup
In my sample restore, I was able to write the full 15 TB in 30 minutes and 52 seconds. This means I am able to utilize almost all of the disk throughput provisioned, which is 9*1000 MB/sec (8.79 GB/sec). So restoring a smaller database (say with 500 GB of data) would take about 1 minute.
The yb-controller supports data backups to most of the popular object storage including Amazon S3, Google Cloud Storage, Azure Cloud Storage, and NFS. It can also do incremental backups which reduces the time needed for backups and uses an even lower amount of resources.*
Another significant advantage of yb-controller-based backups is that these backups can be restored to a YugabyteDB cluster that has a different replication factor from the source.
*Restore time is constant and does not depend on the number of incremental backups present.
Why Not Do EBS Volume Snapshots?
One of the questions I usually get asked is why not just do EBS volume snapshots since the RTO would be much shorter. Yes, that is true — EBS volume snapshots will have shorter RTO, but there are some significant drawbacks. These include:
- Significantly higher costs.
- The inability to backup and/or restore specific databases selectively.
- Restricted to only restoring to a YugabyteDB cluster with an identical replication factor.
- Inability to restore to a YugabyteDB cluster in a different region.
- Backup data being stored in the same account as production data.
Conclusion: Embracing Innovation for Resilient Data Management
The world of data management is continuously changing, and innovation is the only way to keep pace. The ability to recover a 15 TB YugabyteDB database from an Amazon S3 backup in 30 minutes is a testament to the role that technology plays in ensuring the survival and persistence of data. For comparison, a backup of a 4TB PostgreSQL database to object storage takes 95 hours and restore takes about 10 hours. (See <Disaster Recovery with Very Large Postgres Databases at 16:15)
The need for robust backup and recovery solutions will only grow as businesses continue to evolve. YugabyteDB enables organizations to enhance database management, focusing on critical safety and recoverability. With every minute crucial, yb-controller offers fast data recovery, helping businesses maintain operations during challenges.


