YugabyteDB Anywhere Incremental Backups 101
December 19, 2024
YugabyteDB Anywhere is a self-managed YugabyteDB deployment that allows you to manage your data location, network and security, and server and storage, while Yugabyte takes care of database operations.
This blog examines how you can easily, effectively, and securely create incremental backups for YugabyteDB Anywhere based on a full backup. This reduces the time and storage required for backups, allowing them to run more frequently and help you meet your Restore Point Objectives (RPO).
Performing Backups in YugabyteDB Anywhere
An incremental backup only includes the data that has changed since the previous backup. A differential backup contains all the data that has changed since the last full backup.
YugabyteDB Anywhere backups are based on filesystem differences, rather than specific changes at the table level/data level inside SQL.
A typical backup set might require a full backup once a week, but incremental backups are made more frequently, for example, every hour. Incremental backups can only be made if a full backup is available.
Each backup (whether full or incremental) contains:
- A YSQL dump of the schema.
- An export of the snapshot taken at the beginning of the backup.
- A copy of SST files from the Tablet Leader nodes for each table.
These are copied to the storage location (in this case Azure Blob Storage) and stored inside an abstract directory structure consisting of object files and .md (metadata) files.
YSQL dump of the schema
The YSQL dump of the schema is a dump of all keyspaces, or specified keyspaces, configured when the backup was first created. This includes all data definition language (DDL) required to reconstruct the database, but not the actual data. This is the same in full and incremental backups.
Export of the snapshot
This is the snapshot taken at the beginning of the backup. It contains a list of all active sorted sequence table (SST) files and the nodes they are stored on. This allows the original files to be replaced. This is the same in full and incremental backups, however, incremental backups will use this to determine the files that have changed since the last backup. This will be the list of files below (in the copy of SST files). A full backup will copy all files that are referenced in the snapshot.
A copy of SST files from the Tablet Leader nodes for each table
The data stored in the tables is backed up by copying the SST files from each tablet leader. This allows backup to be balanced across the whole cluster, reducing the impact on online users and preventing disk contention on busy tablets. In general, a full backup will contain many times more files than an incremental backup. However, there are some scenarios where the incremental backups will vary significantly, even on a relatively idle database. This is covered below.
Incremental Backups in Action
So, how do Incremental backups work, and what is their dependency on previous full and incremental backups?
Let’s take a hypothetical system that has 10 tables with 1 tablet per table:
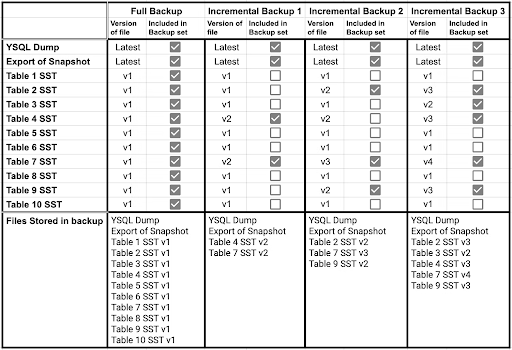
The full backup set contains all the files that were part of the database when the backup was done. However, each incremental only includes what has changed since the previous backup, regardless of whether the previous one was a full or incremental backup.
Note: This is a simplified view of the files and versioning. We will explore other files included in the backup in a future blog on the autonomy of a backup.
What Happens When You Restore?
Using the above example, if you do a restore of incremental backup 2, the complete set of files required for the restore set would be constructed from incremental backup 2 and the previous backups, as shown below.
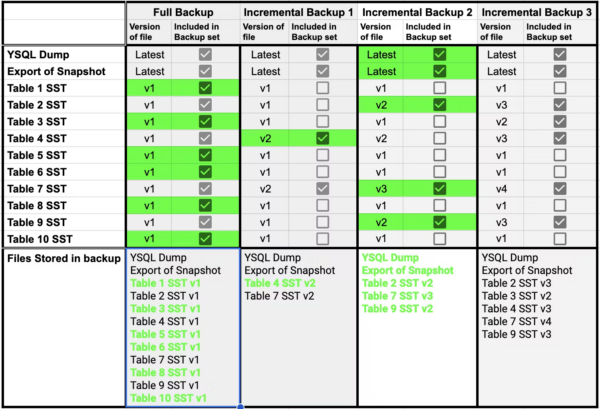
The complete list of required files (as listed in incremental backup 2’s snapshot export) is provided from three backup sets:
- Full backup,
- Incremental backup 1
- Incremental backup 2
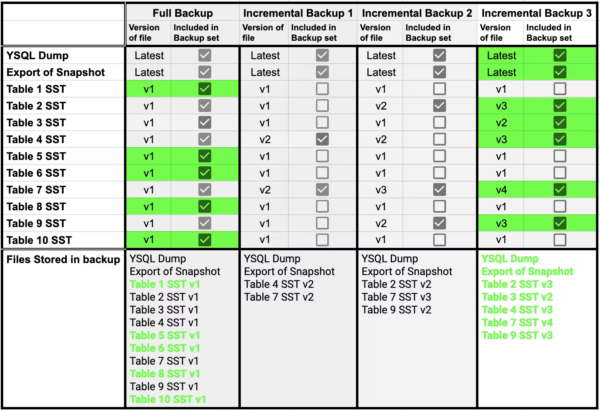
If incremental backup 3 was restored, it would only require files from the full backup set and incremental backup Set 3, as shown below:
Why Do Incremental Backup Sizes Vary?
The size of incremental backups run from YugabyteDB Anywhere can vary greatly depending on what has occurred in the universe. A YugabyteDB Anywhere incremental backup is determined at a file level per node of the cluster. Aside from normal traffic load, on a seemingly idle universe, several events can affect the size of the incremental backup, including:
- Compaction
- Tablet Raft Leader changes (node restart, rolling restart, universe pause, or network partition)
- Tablet Splits
What Happens When the Associated Full Backup is Deleted?
All incremental backups are linked to a full backup, so deleting the full backup will also delete all incremental backups based on it. Each new full backup has all subsequent incremental backups associated with it until the next full backup has been successfully completed.
Is the Full Backup’s Retention/Expiry Date Affected by Incremental Backups?
The full backup’s expiry date is extended when a successful incremental backup occurs. This means that the expiry date of the full backup resets to the expiry date from the start date/time of the last successful incremental backup.
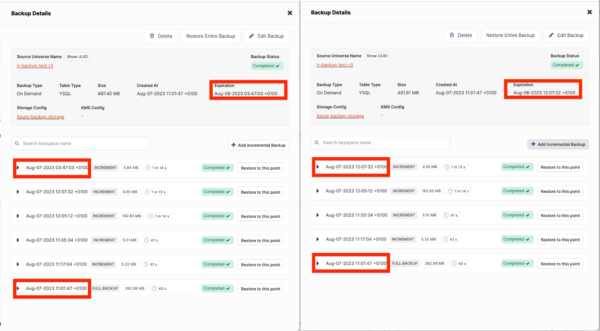
For example, a scheduled full backup configured for a 1-day frequency, a 1-day retention period, and incremental backups scheduled for every hour, would initially have an expiry date of 1 day from the start of the full backup (starting at Aug-07-2023 11:01:47 and expiring at Aug-08-2023 11:01:47). The two last incremental backups increased the expiration. The incremental backup ran on Aug-07-2023 12:07:32 and extended the expiry to Aug-08-2023 12:07:32. The next incremental backup ran on Aug-07-2023 03:47:03 (PM) and further extended the expiry to Aug-08-2023 03:47:03 (PM). The screenshots below show this.
How Does This Impact Storage?
The backup storage configuration is managed in YugabyteDB Anywhere under the backup storage tab. In this case, when using Azure Blob Storage (docs here), a backup is moved to the configured Azure Blob Store every time a backup is run successfully.
The Azure Blob Store is structured as follows:
[Blob Store] - [Universe #1] - - [Backup Set #1] - - - [Data Base or All Databases] - - - [backup.md] - - - - [table identifier] - - - - [table identifier] - - - - [...] - - - - [table identifier] - - - - - [tablet for table] - - - - - [tablet for table] - - - - - [...] - - - - - [tablet for table] - - - - - - [obj] - - - - - - MD - - - - - - - [parts] - - - - - - - - 0 - - - success - - [Backup Set #2] - - - [...] - - - success - [Universe #2] - - [Backup Set #1] - - - [Data Base or All Databases] - - - [backup.md] - - - - [table identifier] - - - - - [tablet for table] - - - - - - [obj] - - - - - - MD - - - - - - - [parts] - - - - - - - - 0
*Key:
[Directory] is a directory,
MD is a file named MD (in this specific case, it is a metadata file)
Conclusion
YugabyteDB Anywhere’s incremental backups provide a lightweight alternative to a full backup. This means you can run backups more frequently, with less impact on disk and network resources. The smaller durable storage footprint reduces storage costs (compared to the cost of only running full backups) and allows you to meet tighter Recovery Point Objectives (RPO) and Recovery Time Objectives (RTO).
Don’t miss our upcoming blog which deep dives into the structure of the storage backup, including what is required for a full disaster recovery.
Find Out More
Want to know more about YugabyteDB Anywhere backups? Check out the following useful links:


