Scaling Relational Spring Microservices Without Load Balancers
April 9, 2020
This article was originally posted on JAXenter.com.
Modern cloud native applications demand relational databases to be highly available while being able to scale to millions of requests (RPS) and thousands of transactions per second (TPS) on demand. This is becoming essential to meet the seamless experience demanded by business applications and their users. High availability and scalability in NoSQL databases like Apache Cassandra and MongoDB are well understood, but have been challenging problems to solve in relational databases. There are many use cases that require scale while being able to benefit from relational database features like ACID transactions, SQL joins, and SQL constraints; billing systems, order management systems, and shopping carts are a few examples.
In this blog, we are going to review how cloud native application development can be simplified by moving from traditional RDBMS scaling techniques (such as vertical scaling using load balancers) to more modern distributed SQL databases such as YugabyteDB which allow horizontal scaling with cluster-aware JDBC drivers.
Microservices architecture needs DB scalability
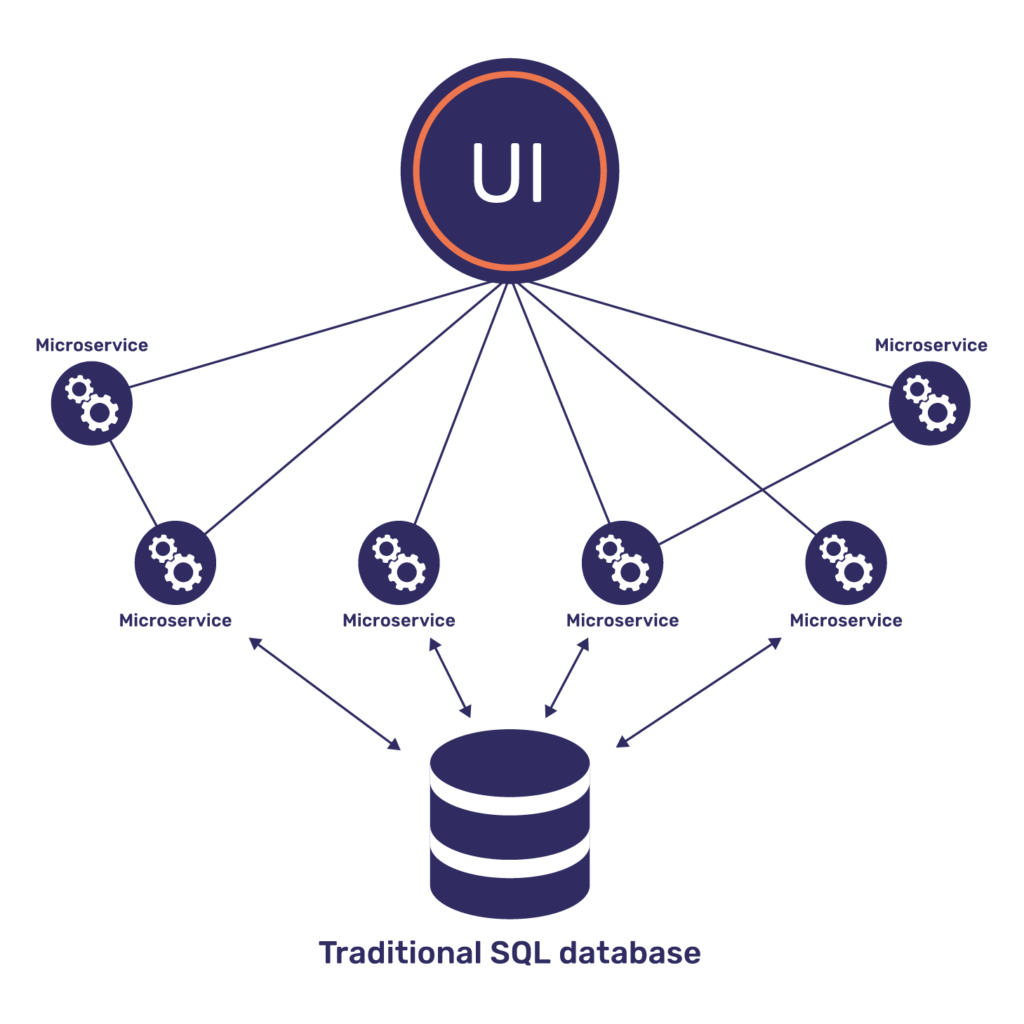
As a part of modernizing the software stack, large monolithic applications are being broken down into multiple microservices. In many cases, some microservices require high scalability from the underlying data stores, while in other cases multiple microservices could be served by a single data store. In either of these cases, the following shortcomings on the DB tier quickly surface:
- Connection exhaustion: Opening database connections from microservices becomes an expensive operation, which gets compounded by the large number of such microservices connecting to a database. This results in exhausting the number of connections the DB tier can handle.
- Higher latencies: As the number of DB queries from scalable microservices increases, the response times become slower because the DB no longer has sufficient resources to handle the query volume.
- Query limiting: When there are large spikes in requests from the application, the DB tier could get completely overloaded resulting in business discontinuity. This is mitigated by implementing query limiting, where requests are outright rejected beyond a certain threshold.
All of the above issues require scaling the RDBMS tier.
Scaling the RDBMS tier – traditional techniques
Scaling reads using Read Replica – needs maintaining load balancers
Read replicas are commonly used for offloading the query load from master in a read-heavy environment and they are nothing but a read-only copy of the master dataset. In this technique, the master node asynchronously replicates updates to keep the replica in sync whenever the master dataset gets updated.
With this approach, applications need to keep track of the list of all the available database servers, and the app also needs context on when to read/write to master (consistency required) and when to read from replicas (scaling reads with staleness). When the master fails, a replica will get promoted to take its spot. Applications need to be aware of this change.
Load balancers are often deployed in front of replicas so that applications need not manage the list of available servers and also to help distribute the SQL query load evenly among the available replicas, as shown in the diagram below.
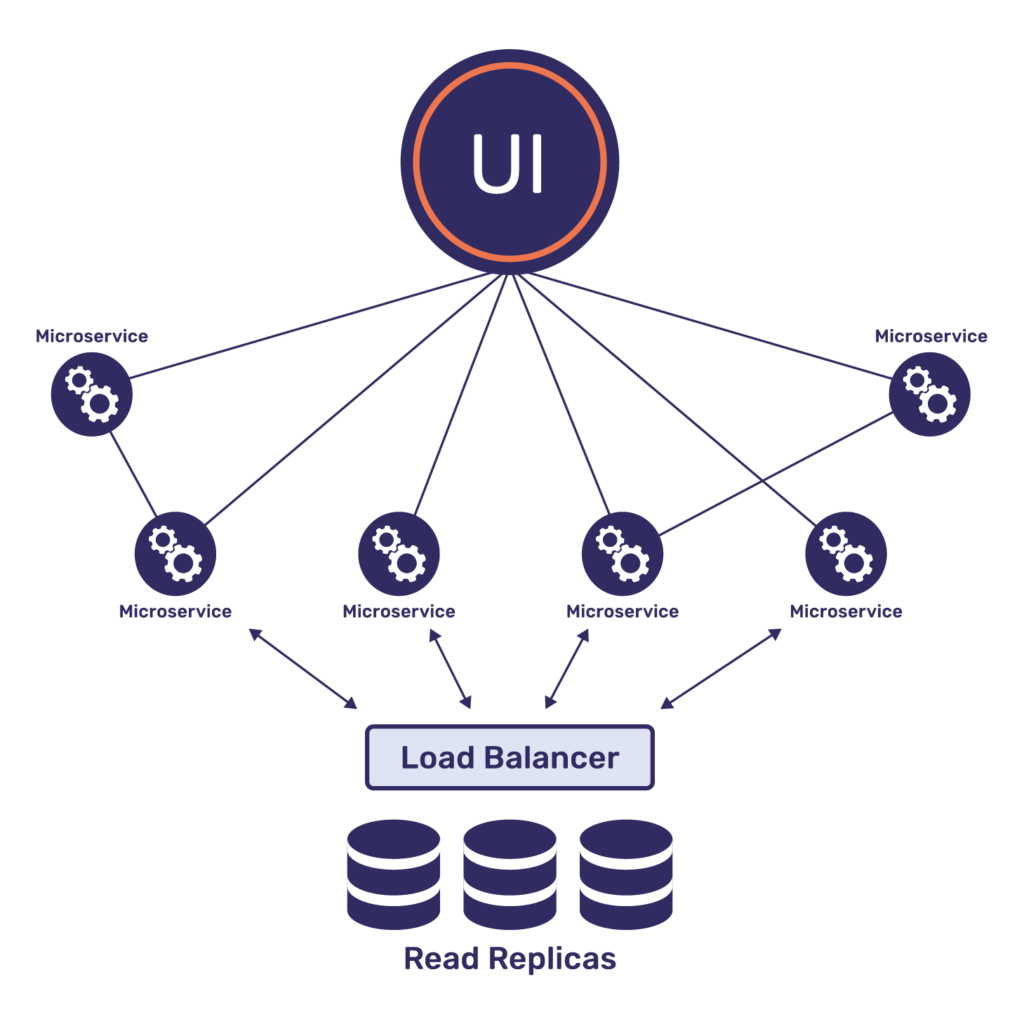
However, load balancers themselves come with the overhead of maintaining the server IPs. A load balancer’s A-record set needs to keep in sync with database servers whenever we scale up or scale down the replicas. This introduces additional complexity for DevOps teams to manage when scaling with read replicas.
Scaling writes vertically – only works up to a ceiling
In a traditional RDBMS, only the single database master can take writes. This implies that the only way to scale write throughput seamlessly is by vertically scaling up the master node. Vertical scaling involves throwing more hardware resources (CPU, memory, disk) at your database system so that apps can have an instant performance increase and can scale TPS without having to do any code changes.
The popularity of this technique has made public cloud providers offer more beefier machines over the years, AWS i3 series and x1 series machines come to mind. Using beefier machines can scale the workload, but only up to a certain point after which the application hits a ceiling. This blog post, which compares the write scalability of Amazon Aurora and YugabyteDB, a distributed SQL database, illustrates the point about hitting a write ceiling. Additionally, beefier machines are expensive to run, increasing the total cost of ownership.
Scaling relational workloads with Distributed SQL
There has been a shift in the SQL database world – distributed SQL databases are bringing together cloud native capabilities such as horizontal scalability, continuous availability, and multi-region deployments into the RDBMS workloads.
Seamlessly scale reads and writes – add nodes to cluster
Distributed SQL databases like YugabyteDB can linearly scale both writes and reads by simply adding more nodes to the cluster. Microservices that scale dynamically will significantly benefit from distributed SQL databases. The latest benchmarks on AWS have shown YugabyteDB can easily scale to more than 10x the maximum throughput possible with Amazon Aurora.
Cluster-aware JDBC drivers – scale without load balancers
For microservices to make use of distributed SQL features, JDBC drivers that we currently use in our applications have to be extended to benefit from the linear scalability of a distributed SQL database without the need for load balancers. YugabyteDB previously announced the availability (in beta) of a cluster-aware JDBC driver. Given that YugabyteDB is PostgreSQL compatible, it extends the standard PostgreSQL JDBC driver to provide cluster topology awareness to JDBC clients.
Clients will automatically discover the cluster topology and open connections to the available data node, and cluster aware drivers provides a seamless way for clients to get notified when you scale up or scale down a cluster, as shown in the below diagram.
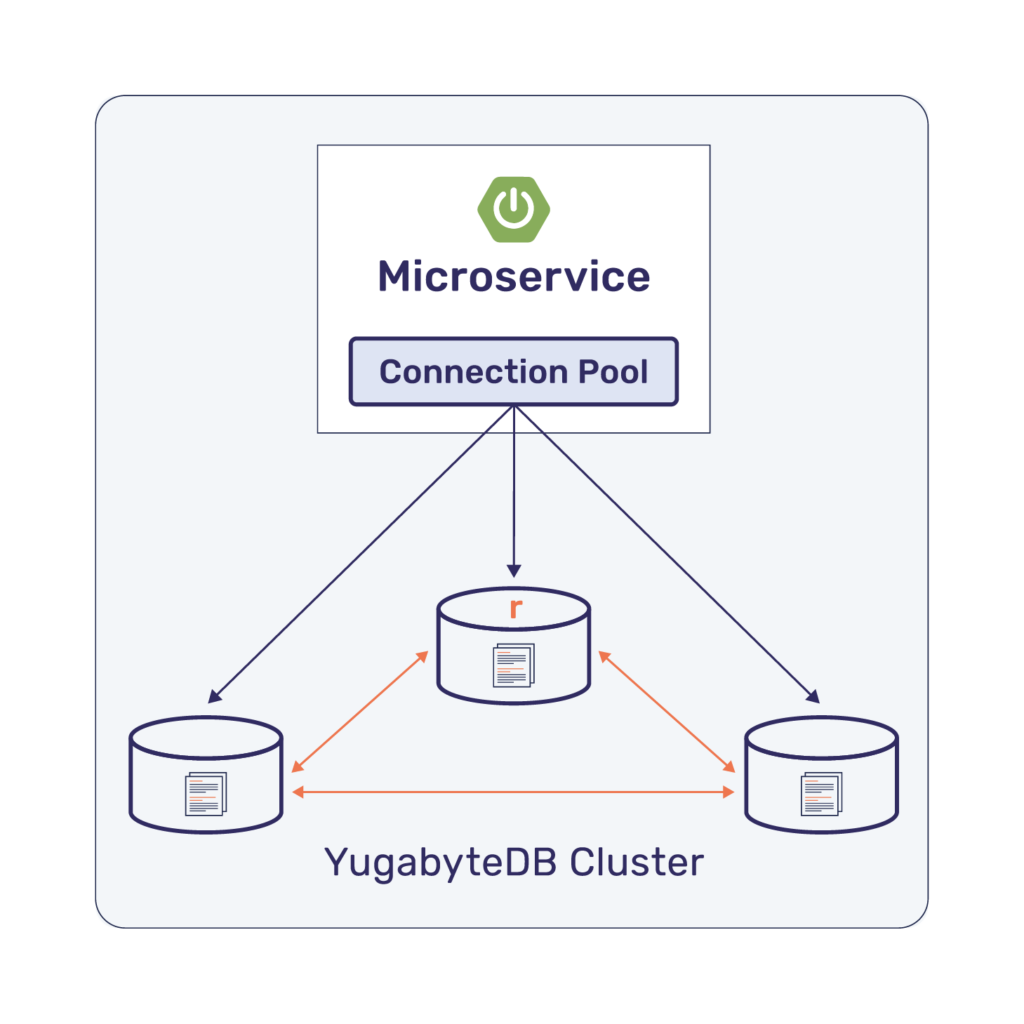 For this example, we are using cart-microservice from the yugastore-java application, which is a cloud native implementation of an e-commerce app. The cart microservice is built using Spring Boot, Spring Data JPA, and the PostgreSQL JDBC driver for connecting to distributed SQL. With minimal code changes, we’ll refactor this Spring microservice to use the YugabyteDB JDBC driver that will enable cluster awareness by default.
For this example, we are using cart-microservice from the yugastore-java application, which is a cloud native implementation of an e-commerce app. The cart microservice is built using Spring Boot, Spring Data JPA, and the PostgreSQL JDBC driver for connecting to distributed SQL. With minimal code changes, we’ll refactor this Spring microservice to use the YugabyteDB JDBC driver that will enable cluster awareness by default.
The first step is to update dependencies of the microservice to use the YugabyteDB JDBC driver instead of the PostgreSQL JDBC Driver:
<dependency> <groupId>com.yugabyte</groupId> <artifactId>jdbc-yugabytedb</artifactId> <version>42.2.7-yb-3</version> </dependency>
With Spring boot applications, auto reconfiguration will instantiate PostgreSQL DataSource by default since we are using PostgreSQL dialect. We need to override this default behavior to create a cluster-aware data source; add a bean configuration to instantiate DataSource of type:
com.yugabyte.ysql.YBClusterAwareDataSource:
@Bean
public DataSource getDataSource() {
return new YBClusterAwareDataSource(jdbcUrl);
}
Now we are ready to run the app.
Step 1: Start the YugabyteDB cluster
You can do so using the following command:
./bin/yb-ctl destroy && ./bin/yb-ctl --rf 3 create --tserver_flags="cql_nodelist_refresh_interval_secs=10" --master_flags="tserver_unresponsive_timeout_ms=10000"
This will start a 3-node local cluster with replication factor (RF) 3. The flag cql_nodelist_refresh_interval_secs configures how often the drivers will get notified of cluster topology changes and the following flag tserver_unresponsive_timeout_ms is for the master to mark a node as dead after it stops responding (heartbeats) for 10 seconds.
Note: Detailed installation instructions for YugabyteDB on a local workstation.
Step 2: Build and start the cart-microservice
You can run the following commands from the cart-microservice project directory:
./mvnw clean package -DskipTests java -jar target/cart-microservice-0.0.1-SNAPSHOT.jar
You will see the client making connections to all the available nodes in the cluster on localhost:
INFO 18800 --- [main] c.y.y.YBConnectionLoadBalancingPolicy : Initializing connection pool for YSQL host /127.0.0.2 (host up). INFO 18800 --- [main] c.y.y.YBConnectionLoadBalancingPolicy : Initializing connection pool for YSQL host /127.0.0.3 (host up). INFO 18800 --- [main] c.y.y.YBConnectionLoadBalancingPolicy : Initializing connection pool for YSQL host /127.0.0.1 (host up).
Step 3: Scale out the cluster by adding a node
Let us now add a node in order to scale up the cluster from 3 to 4 nodes.
./bin/yb-ctl add_node
Step 4: The service automatically “discovers” the new node
You will see the client opening a connection to newly added T-server that joined the cluster:
INFO 18800 --- [ter1-worker-137] c.y.y.YBConnectionLoadBalancingPolicy : Initializing connection pool for YSQL host /127.0.0.4 (host up).
Step 5: Scale down – service should auto-discover
Let us now scale the cluster back down to 3 nodes.
./bin/yb-ctl remove_node 4
You will see the data node leaving the cluster getting logged in the cluster-aware client:
INFO 18800 --- [ter1-worker-166] c.y.y.YBConnectionLoadBalancingPolicy : Removing connection pool for YSQL host: 127.0.0.4/127.0.0.4 (host down).
Summary
As enterprises continue to modernize legacy applications, throughput and latency demands from backend relational databases will continue to grow. We at YugabyteDB believe that cloud native applications will tremendously benefit from the linear scalability, extreme resilience and geo-distribution capabilities of distributed SQL databases. And as we add more topology-related intelligence such as cluster awareness, multi-region awareness, and data locality into the realm of JDBC drivers, building scalable, fault-tolerant backends for modern microservices will become easier than ever before.


