Snowflake CDC: Publishing Data Using Amazon S3 and YugabyteDB
July 12, 2022
In this blog, we explore how to stream data from YugabyteDB’s Change Data Capture (CDC) feature to Snowflake through Amazon S3.
We’ll use YugabyteDB’s CDC SDK server, an open source project that provides a streaming platform for CDC. We’ll also use Snowpipe to automate data loading to files as soon as they are available in a S3 bucket.
Before you begin
Before getting started, make sure you have access to the following:
- Data modify access to YugabyteDB
- Write access to an AWS S3 bucket with the below permissions:
- (“s3:ListBucket”, “s3:GetBucketLocation”, “s3:PutObject”,”s3:GetObject”, “s3:GetObjectVersion”, “s3:DeleteObject”, “s3:DeleteObjectVersion”)
- Read and write access to a Snowflake cluster
Snowflake CDC overall architecture
Here’s a quick snapshot of the architecture we’ll be building:
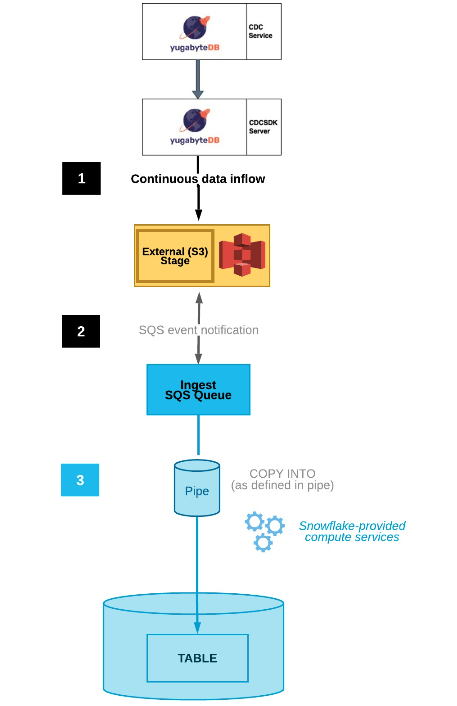
Snowflake CDC setup
For starters, configure the CDCSDK server to work with the S3 sink. Below is a sample configuration:
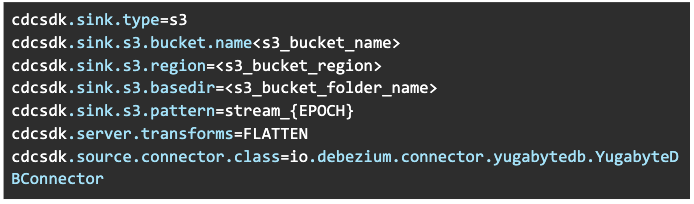
Please make sure you have the following Amazon IAM permissions:
- “s3:PutObject”,
- “s3:GetObject”,
- “s3:GetObjectVersion”,
- “s3:DeleteObject”,
- “s3:DeleteObjectVersion”
- “s3:ListBucket”,
- “s3:GetBucketLocation
Finally, get the CDC data to Snowflake by automating it through Snowpipe with these steps.
Example of a working setup
We’ll push the CDC events for the below table “orders”. That means we’ll use the command having three columns: “order_id”, “item”, and “quantity” to create the table.

The created table’s description will then be displayed as shown below:

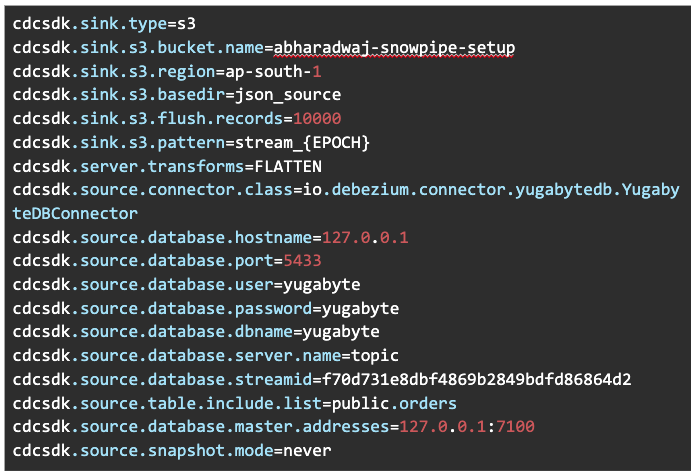
Below is the CDCSK server we used. Please note we will stream the records to the S3 location (s3://abharadwaj-snowpipe-setup/json_source/). We have also configured the CDCSK server to create and push one file to S3 per 10,000 records (cdcsdk.sink.s3.flush.records).
You’ll see we have created a CDC stream with the StreamId: “f70d731e8dbf4869b2849bdfd86864d2”. Please refer to our documentation to create a CDC stream.
From here, we’ll push 10,000 rows into the YB table “orders” using the below command:

This will also push a file to the configured S3 location, as shown below:

In this example, we have configured a table called: “ORDERS_RECORDS” in Snowflake. Upon querying the table, we see there are indeed 10,000 records:

Below we show what a particular record looks like. In this instance, we show the record associated with order_id = 878 using the following Snowflake query:

Additionally, please note all the column data is stored as a single JSON record in the Snowflake table.
Conclusion
In this short post, we set up a pipeline to stream CDC data from YugabyteDB to Snowflake. We saw how all the column data was stored as a single record (i.e., JSON format) in the Snowflake collection.
Learn more about YugabyteDB CDC by checking out our Change Data Capture (CDC) documentation. Got questions? Ask them in the YugabyteDB Community Slack channel.


