The Future of Databases – Distributed SQL Summit Asia 2021
May 11, 2021
At this year’s Distributed SQL Summit Asia 2021, Dhaval Jagani from Infosys presented the talk, “The Future of Databases.” In this post you can find a summary of the talk, some of the presentation highlights, as well as links to this talk and others from the event.
New Data Trends and Demands
Dhaval kicked things off by exploring the data trends he’s spotted from his vantage at Infosys, which has almost 1,500 clients in over 46 countries.
- Organizations are continuing to demand highly available and resilient applications
- The enablement of event-driven architectures
- The need for a 360 degree view of business entities
- Ability to generate insights with AI and machine learning
All of the above while data storage and throughput demands will continue to go up, while latencies must remain low.
Highly Available and Resilient Distributed Databases
Dhaval’s argument is that distributed databases are the ideal solution for these ongoing demands on applications that require highly available and resilient applications. He believes that because of the distributed nature of this new class of databases, which by default store multiple copies of data, it also means that node failures can be effectively managed without causing downtime…because no single node holds all the data.
Distributed Databases Enabling Event Driven Architectures
Next, Dhaval explored how distributed databases can help identify business events by acting as publishers and push events to queuing or messaging systems to help provide the underpinnings of an event-driven architecture.
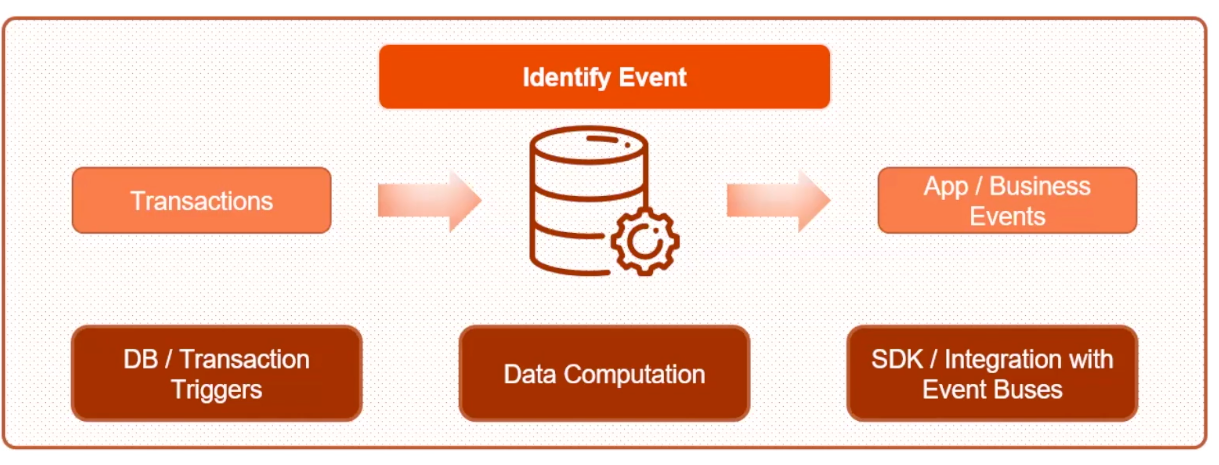
Achieving a 360 Degree View with Distributed Databases
Every organization wants to achieve a 360 degree view of their customers or other business entities. Unfortunately, this often means having to analyze data that might be in relational, NoSQL, graph, and document data stores. Distributed databases that support multiple APIs and data models are the systems of choice that can get organizations closer to this 360 degree view.
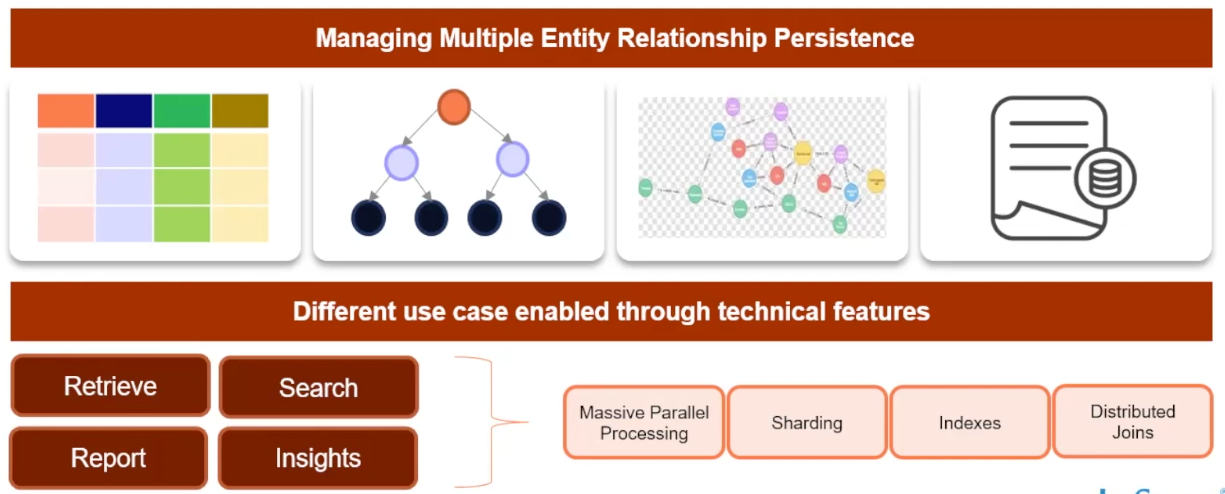
Over the long haul, Dhaval believes that SQL is here to stay. Because SQL is flexible enough to support a variety of use cases like search, OLTP, time-series, and reporting coupled with the massive parallel processing, automatic sharding, secondary indexes, and distributed JOINs that distributed SQL databases provide…the future will continue to be one dominated by SQL, or more specifically, distributed SQL.
A Transforming Database Landscape
In the final portion of his talk, Dhaval described how he is observing organizations starting to move away from the idea of polyglot persistence, encompassing a variety of purpose built databases, to “data platforms.” With these data platforms, database sprawl is reduced, multiple use cases and workloads can be supported with fewer databases and more functionality than before the province of the application has been moved to the “data platform.”
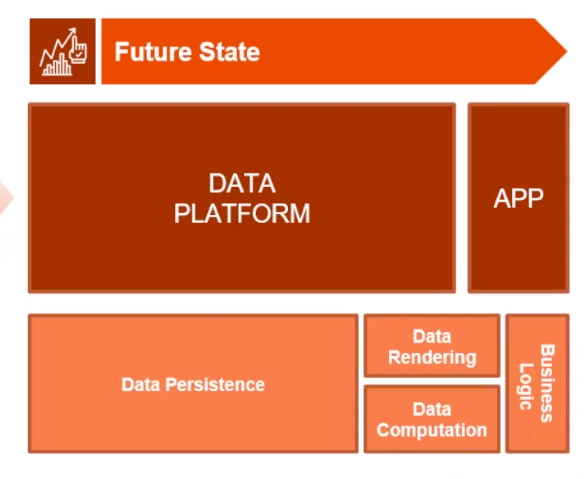
To this end, Dhaval described a variety of data services and products that Infosys offers to help their clients move their data infrastructure to a “data platform” in order to achieve their technical business aims.
What’s Next?
To view this talk, plus all twenty-four of the talks from this year’s Distributed SQL Summit Asia event make sure to check out our video showcase for the event on our Vimeo channel.
Ready to start a conversation about how Distributed SQL can help accelerate your journey to cloud? Join us on YugabyteDB Community Slack to get the conversation started.


