YugabyteDB and Hasura Make it Easier to Build Complex, Global Applications
June 23, 2021
Building innovative applications that improve user experience and exceed expectations is hard. As users, we demand a lot. We demand that your applications always be available – who knows, we may want to order a new set of tires at 3:30 am on a Wednesday. We demand that your applications be fast wherever we are – doesn’t matter if it’s Phnom Penh or Philadelphia. And we definitely expect you to give us a good experience – your application should know what we want to do next and help us get there.
At Yugabyte, we recognize the challenges that developers and ops teams deal with in building innovative apps and services that deliver on user expectations. That’s why we have partnered with Hasura to build an integration between YugabyteDB Managed (formerly Yugabyte Cloud) and Hasura Cloud. Now you can deploy a highly available, massively scalable, geo-distributed database to Yugabyte Managed from Hasura Cloud with a single click.
We want to make building complex, global applications easier. This integration will do that for developers.
Hasura gives you instant GraphQL APIs
Hasura gives you an instant GraphQL API for all your data. It is open source and available as a fully hosted service, Hasura Cloud. All you have to do is connect your database to Hasura, and it will automatically generate a GraphQL API from it for you. You can also create new tables and fields inside the Hasura console. So you don’t have to bounce back and forth between your database client and Hasura if you need to add new tables or fields.
So whether you have an existing application database or are starting from scratch with no database Hasura makes it fast and easy to deploy and run GraphQL applications.
Developers love Hasura too. Both the standard GraphQL engine and Hasura’s GraphQL engine are open source (Hey! YugabyteDB is open source too!). Both are popular projects. Yet, in 3 years less time, Hasura’s repo has been starred over 5,000 more times – 17.7 thousand for the standard engine to 22.9 for Hasura’s.
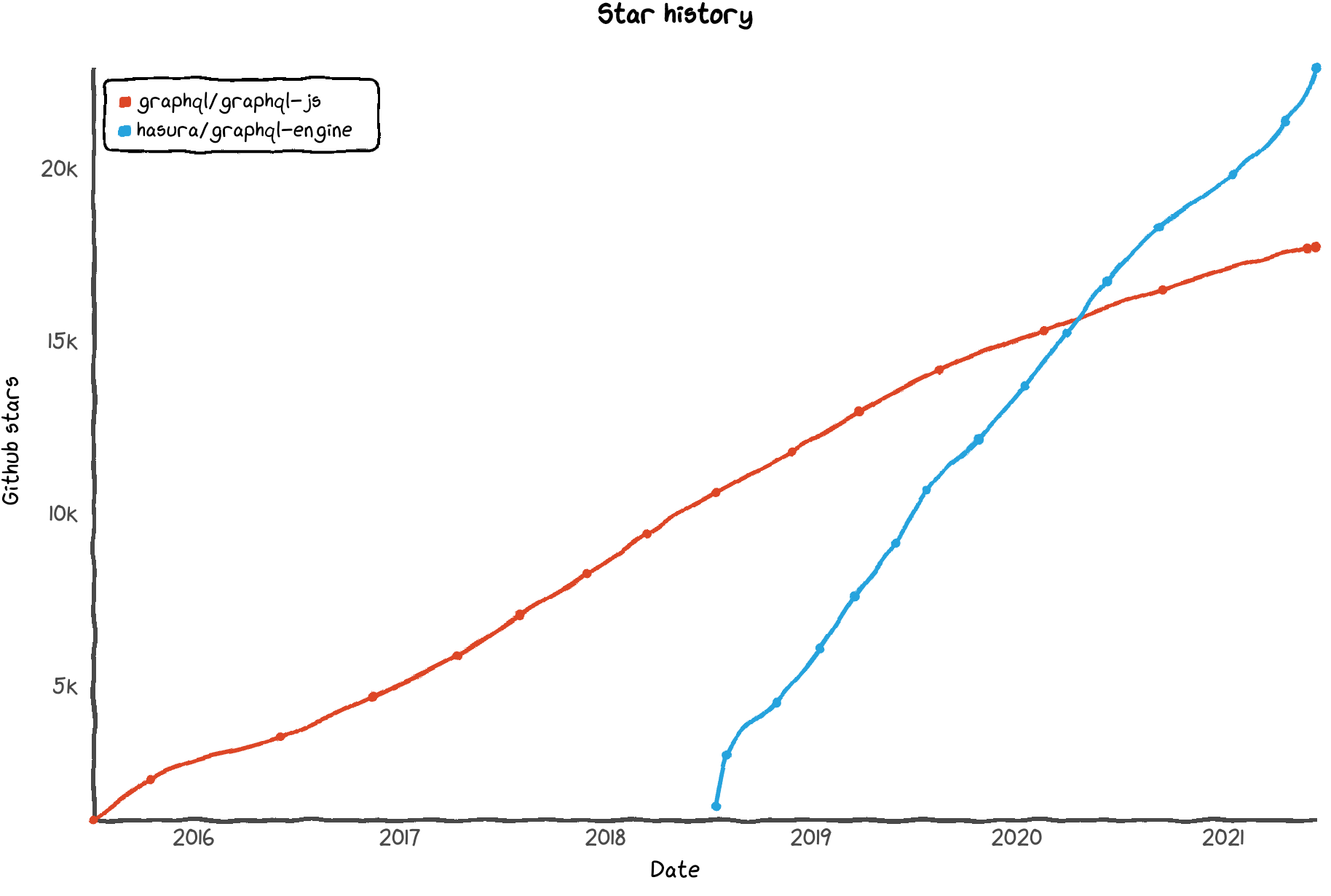
Graph created with Star History. See it here.
GraphQL is incredibly popular because it makes application development easier
We all built and used REST APIs for years. They make data retrieval simple. They have flaws though, and GraphQL addresses a lot of these flaws. It makes application development easier.
You only have one endpoint
In REST, for every handler function – for example, Create, Read, Update, and Delete functions – there is an endpoint. So for every table you are exposing through your API, you could have 4 endpoints (or more if you want to expose other handlers).
In GraphQL, you have one endpoint. You pass it a GraphQL query – think SQL but kinda written like JSON – and it routes it to the appropriate handlers. You create, read, update, and delete from this one endpoint. That means no more errors from guessing the wrong endpoints and no more errors in production due to mismatched endpoint names between environments. Those concerns are off your plate with GraphQL. You have an endpoint, and you send all your queries to it.
Queries are easier to write in GraphQL
Let’s say you have two tables, a Customer table and an Address table, with the Address table having the Customer Id as a foreign key.
If you wanted to query a customer and all their addresses, it would require two calls in REST, one to the Customer read endpoint and one to the Address read endpoint. Then you’d join the data yourself in-code.
GraphQL supports this in a single query. You nest your query – put your Address query inside of your Customer query – and it will return a nested result – customer addresses will be returned as part of each customer record. This makes it easier to build join queries, even more so the more tables you’re joining across.
GraphQL transfers less data
With REST, when you call a read endpoint, you get all the fields back in the payload. You can’t limit it to just the fields you need. With GraphQL, you can specify exactly which fields you want back in a query. So payloads in GraphQL can be more specific and smaller than REST. Queries that join data across tables are another example of where GraphQL uses less data than REST.
This may not be an everyday concern for a lot of developers, but when you are building massively scalable applications with users spanning the planet, bandwidth isn’t always a guarantee. Optimizing your application’s data transfer is a necessity for global applications.
YugabyteDB + Hasura: making it easier than ever to build highly available, massively scalable, geo-distributed applications
Pairing YugabyteDB’s high-performance distributed SQL database with Hasura’s instant GraphQL gives you a fast and easy platform to build complex, global applications. You get all the benefits of GraphQL without any of the toil of writing a bunch of handler methods, connected to a highly available, massively scalable, geo-distributed database.
This used to be really difficult, but with the new integration between Yugabyte Cloud and Hasura Cloud, it’s single-click.
Sign up for Yugabyte Cloud
Whether you’re building an MVP or operating at massive scale, Yugabyte Cloud can make sure your application databases are always available and fast. Yugabyte Cloud scales with your product. You can add and remove nodes at will. So you’re never over-provisioned. Best of all, Yugabyte Cloud is easy to build with. It’s a drop-in replacement for Postgres.
Sign up for the Yugabyte Cloud Beta. It’s PostgreSQL reimagined for a cloud-native world.
Other Yugabyte + Hasura Resources
You can see an example of deploying a Hasura app on YugabyteDB in our blog post, Deploy a Real-Time Polling App with Hasura Cloud and Yugabyte Cloud Distributed SQL.
Also, I’ll be hosting a webinar on July 13th along with Nikhil Chandrappa, a software engineer here at Yugabyte, where Nikhil will walk you through implementing a GraphQL application using Yugabyte Cloud and Hasura Cloud. Register here: Building Always-On, Scalable Applications with Yugabyte Cloud and Hasura Cloud.


