YugabyteDB 1.1 New Feature: Document Data Modeling with the JSON Data Type
September 26, 2018
Welcome to another post in our ongoing series that highlights new features from the latest 1.1 release announced last week. Today we are going to look at document data modeling using the native JSON data type available in YugabyteDB’s Cassandra compatible YCQL API. Note that this data type is specific to YugabyteDB and is not part of the standard Cassandra Query Language (CQL).
With YugabyteDB’s native JSON support, developers can now benefit from the structured query language of Cassandra and the document data modeling of MongoDB in a single database.
Document Data Models & JSON Data Type
Documents are the most common way for storing, retrieving, and managing semi-structured data. Unlike the traditional relational data model, the document data model is not restricted to a rigid schema of rows and columns. The schema can be changed easily thus helping application developers write business logic faster than ever before. Instead of columns with names and data types that are used in a relational model, a document contains a description of the data type and the value for that description. Each document can have the same or different structure. Even nested document structures are possible where one or more sub-documents are embedded inside a larger document.
Databases commonly support document data management through the use of a JSON data type. JSON.org defines JSON (JavaScript Object Notation) to be a lightweight data-interchange format. It’s easy for humans to read and write. it’s easy for machines to parse and generate. JSON has four simple data types:
- string
- number
- boolean
- null (or empty)
In addition, it has two core complex data types:
- Collection of name-value pairs which is realized as an object, hash table, dictionary or something similar depending on the language.
- Ordered list of values which is realized as an array, vector, list or sequence depending on the language.
The Benefits of Document Data Modeling
Document data models are best fit for use cases requiring a flexible schema and fast data access. E.g. nested documents enable applications to store related pieces of information in the same database record in a denormalized manner. As a result, applications can issue fewer queries and updates to complete common operations. Also, the nested document approach maps well to the object-oriented application design as shown below:
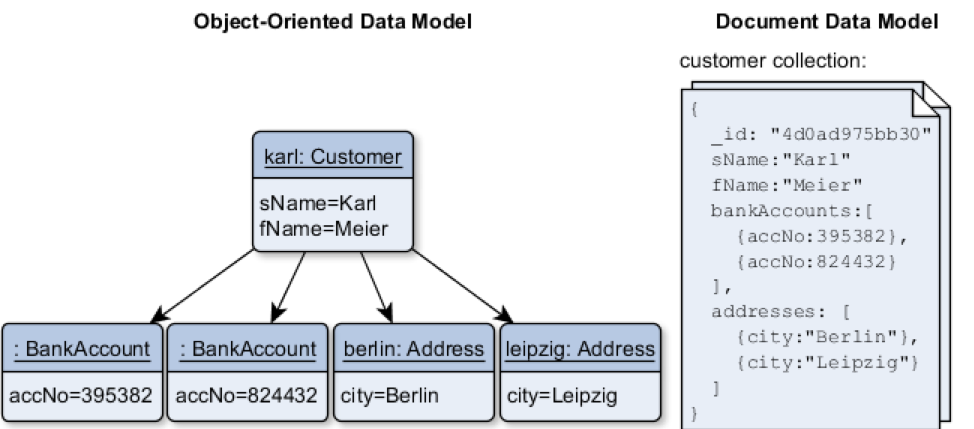
Source: Philipp Hauer
Examples of applications that are best served with a document data model:
- Event tracking and IoT apps where the data payload associated with each event which might have a different set of attributes, often introduced on the fly.
- User profile related use-cases where new attributes are added over a period of time as the app evolves
- Ecommerce use cases where different products have varying data
- Gaming apps that deal with a changing set of attributes for a player based on the state of the user
- Databases used with message buses like Kafka that integrate multiple data sources requiring a mix of schemas
Along with the above use cases, JSON data types help interoperability across the various layers of the application stack. The data types and structures described above in the context of JSON documents are universally supported by modern programming languages. This makes the JSON data format work well across different programming languages. A simple example of a scenario where this is useful is to compose any web application, where the following languages are used:
- Javascript, Objective C, Java, etc. for the frontend UI (browsers, iPhones, Android, etc.)
- Javascript frameworks like Express/NodeJS, Java frameworks like Spring/Play, etc. for the application server and REST API layer
- A database for storage and retrieval of data using JSON data type
Document Data Modeling in YugabyteDB
There are a number of different serialization formats for JSON data, one of the popular formats being JSONB to efficiently model document data. And just in case you were wondering, JSONB stands for JSON Better.
YugabyteDB’s Cassandra compatible YCQL API supports the JSONB data type to parse, store and query JSON documents natively. This data type is similar in query language syntax and functionality to the one supported by PostgreSQL. JSONB serialization allows for easy search and retrieval of attributes inside the document. This is achieved by storing all the JSON attributes in a sorted order, which allows for efficient binary search of keys. Similarly arrays are stored such that random access for a particular array index into the serialized JSON document is possible. DocDB, YugabyteDB’s underlying storage engine, is document-oriented in itself which makes storing the data of the JSON data type lot more simple than otherwise possible.
Let us take the example of an ecommerce app of an online bookstore. The database for such a bookstore needs to store details of various books, some of which may have custom attributes. Below is an example of a JSON document that captures the details of a particular book, Macbeth written by William Shakespeare.
{
"name":"Macbeth",
"author":{
"first_name":"William",
"last_name":"Shakespeare"
},
"year":1623,
"editors":[
"John",
"Elizabeth",
"Jeff"
]
}
Create a Table
The books table for this bookstore can be modeled as shown below. We assume that the id of each book is an int, but this could be a string or a uuid.
cqlsh> CREATE KEYSPACE store; cqlsh> CREATE TABLE store.books ( id int PRIMARY KEY, details jsonb );
Insert Data
Next we insert some sample data for a few books into this store. You can copy and paste the following commands into the cqlsh shell for YugabyteDB to insert the data. Note that you would need a cqlsh that has the enhancement to work with YugabyteDB JSON documents, you can download it using the documentation here.
INSERT INTO store.books (id, details) VALUES (1,
'{ "name" : "Macbeth",
"author" : {"first_name": "William", "last_name": "Shakespeare"},
"year" : 1623,
"editors": ["John", "Elizabeth", "Jeff"] }'
);
INSERT INTO store.books (id, details) VALUES (2,
'{ "name" : "Hamlet",
"author" : {"first_name": "William", "last_name": "Shakespeare"},
"year" : 1603,
"editors": ["Lysa", "Mark", "Robert"] }'
);
INSERT INTO store.books (id, details) VALUES (3,
'{ "name" : "Oliver Twist",
"author" : {"first_name": "Charles", "last_name": "Dickens"},
"year" : 1838,
"genre" : "novel",
"editors": ["Mark", "Tony", "Britney"] }'
);
INSERT INTO store.books (id, details) VALUES (4,
'{ "name" : "Great Expectations",
"author" : {"first_name": "Charles", "last_name": "Dickens"},
"year" : 1950,
"genre" : "novel",
"editors": ["Robert", "John", "Melisa"] }'
);
INSERT INTO store.books (id, details) VALUES (5,
'{ "name" : "A Brief History of Time",
"author" : {"first_name": "Stephen", "last_name": "Hawking"},
"year" : 1988,
"genre" : "science",
"editors": ["Melisa", "Mark", "John"] }'
);
Note the following interesting points about the book details above:
- The
yearattribute for each of the books is interpreted as an integer. - The first two books do not have a
genreattribute, which the others do. - The
authorattribute is a map. - The
editorsattribute is an array.
Retrieve a Subset of Attributes
Running the following default select query will return all attributes of each book.
cqlsh> SELECT * FROM store.books;
But a number of times we may want to query just a subset of attributes from YugabyteDB database. Below is an example of a query that retrieves just the id and name for all the books.
cqlsh> SELECT id, details->>'name' as book_title FROM store.books; id | book_title ----+------------------------- 5 | A Brief History of Time 1 | Macbeth 4 | Great Expectations 2 | Hamlet 3 | Oliver Twist
Query by Attribute Values – String
The name attribute is a string in the book details JSON document. Let us query all the details of book named Hamlet.
cqlsh> SELECT * FROM store.books WHERE details->>'name'='Hamlet';
id | details
----+---------------------------------------------------------------
2 | {"author":{"first_name":"William","last_name":"Shakespeare"},
"editors":["Lysa","Mark","Robert"],
"name":"Hamlet","year":1603}Note that we can query by attributes that exist only in some of the documents. For example, we can query for all books that have a genre of novel. Recall from before that all books do not have a genre attribute defined.
cqlsh> SELECT id, details->>'name' as title,
details->>'genre' as genre
FROM store.books
WHERE details->>'genre'='novel';
id | title | genre
----+--------------------+-------
4 | Great Expectations | novel
3 | Oliver Twist | novel
Query by Attribute Values – Integer
The year attribute is an integer in the book details JSON document. Let us query the id and name of books written after 1900.
cqlsh> SELECT id, details->>'name' as title, details->>'year'
FROM store.books
WHERE CAST(details->>'year' AS integer) > 1900;
id | title | expr
----+-------------------------+------
5 | A Brief History of Time | 1988
4 | Great Expectations | 1950Query by Attribute Values – Map
The author attribute is a map, which in turn consists of the attributes first_name and last_name. Let us fetch the ids and titles of all books written by the author William Shakespeare.
cqlsh> SELECT id, details->>'name' as title,
details->>'author' as author
FROM store.books
WHERE details->'author'->>'first_name' = 'William' AND
details->'author'->>'last_name' = 'Shakespeare';
id | title | author
----+---------+----------------------------------------------------
1 | Macbeth | {"first_name":"William","last_name":"Shakespeare"}
2 | Hamlet | {"first_name":"William","last_name":"Shakespeare"}Query by Attribute Values – Array
The editors attribute is an array consisting of the first names of the editors of each of the books. We can query for the book titles where Mark is the first entry in the editors list as follows.
cqlsh> SELECT id, details->>'name' as title,
details->>'editors' as editors FROM store.books
WHERE details->'editors'->>0 = 'Mark';
id | title | editors
----+--------------+---------------------------
3 | Oliver Twist | ["Mark","Tony","Britney"]Comparison with Apache Cassandra’s JSON Support
Apache Cassandra’s JSON support can be misleading for many developers. CQL allows SELECT and INSERT statements to include the JSON keyword. The SELECT output will now be available in the JSON format and the INSERT inputs can now be specified in the JSON format. However, this “JSON” support is simply an ease-of-use abstraction in the CQL layer that the underlying database engine is unaware of. Since there is no native JSON data type in CQL, the schema doesn’t have any knowledge of the JSON provided by the user. This means the schema definition doesn’t change nor does the schema enforcement. Cassandra developers needing native JSON support previously had no choice but to add a new document database such as MongoDB or Couchbase into their data tier.
What’s Next?
- Install YugabyteDB and explore how to work with JSON documents.
- Get more details on the JSONB data type.
- Read the YugabyteDB 1.1 announcement blog
- Check out the technical deep dive into YugabyteDB 1.1


