YugabyteDB Moves Beyond PostgreSQL 11
May 22, 2024
Like many companies in the world of distributed SQL, at Yugabyte we initially tried to build our own SQL engine from scratch. We figured we could make YugabyteDB Postgres-compatible by implementing one feature at a time. How hard could it be?
As the early engineers on the project researched PostgreSQL, they discovered that even a seemingly simple psql “\d <relation>” (describe relation) command invokes a number of complex queries underneath the covers (source), and it soon became clear how much effort it is to build a Postgres-compatible system from the ground up. Postgres has a lot of functionality! From all the database basics, to partitioned tables, user-defined types, access control, advanced query planning and optimization, and much more.
So, several of the original developers created a prototype integrating the Postgres query layer with YugabyteDB’s existing distributed database for storage, and from then on, they knew this was the right path to take—building distributed Postgres, using the actual Postgres code for maximum compatibility with existing apps.

Here we begin a series of posts describing our efforts to upgrade YugabyteDB from Postgres 11 to Postgres 15. In this post, we’ll give an overview of the project and the problems we’re solving in order to deliver a newer version of Postgres to our users.
Why is YugabyteDB Still on Postgres 11?
When we first created YugabyteDB, we built it on top of what was then a shiny new Postgres 11. But the years have flown by, and here we are, since November 2023 on a version of PostgreSQL no longer supported by the core Postgres development team. What happened?
It turns out that once we released our Postgres-compatible distributed database, the last thing on the minds of most of our users was getting upgrades to each new Postgres release. Why is that? Two big reasons:
- Many of the features in Postgres 12+ aren’t must-have features for our users. Our users have demanding distributed Postgres workloads, and their needs are met with the already-rich feature set in Postgres 11, coupled with our fault-tolerant distributed storage and transaction layer. For example: Postgres 12+ added features like improvements to partitioning and parallelized vacuuming that aren’t strictly necessary because they have storage-layer analogs in YugabyteDB. On the other hand, there are some features that would be nice to have, but haven’t yet risen to the must-have level. These nice-to-haves include regexp functions, multirange datatypes, generated columns, and accessing JSON data with subscripts.
- Our users ask for lots of other features and improvements. When we respond to their feedback, we sometimes pull in features, security fixes, and other improvements from Postgres 12+ (examples: partial SQL/JSON path language, jsonpath datetime() method, pg_backend_memory_contexts system view, log postgres memory contexts). In other cases, we introduce our own features, security patches, and other improvements. We’ve made many such YugabyteDB-specific changes, for example in the areas of improved performance, observability, scalable connection management, and cross-geo replication.
So, our users on Postgres 11 aren’t just fully supported by Yugabyte, they’re also getting upgrades all the time.
But something we haven’t yet talked about publicly, and something a lot of people want to hear about is, what’s going on with YugabyteDB upgrading to a newer version of Postgres?! After all, some of those new Postgres features are pretty cool. And that’s what we’re here to tell you about today.
The short answer is: we’ve been working on updating our Postgres version for quite some time, it’s coming, and we’re sticking to our principles and ensuring it’s a highly reliable, scalable, available, and secure system for your distributed Postgres needs.
But why can’t we just upgrade our Postgres 11 code to Postgres ‘latest’ and publish a release?
Well, if you work in software development you already understand the complexity involved with any large software upgrade. Even with small projects, there are many things to do, such as testing, documentation, and planning, but with this particular upgrade, there’s even more.
To understand why, let’s first take a look at how YugabyteDB works, and then discuss Postgres-version-refresh-related challenges.
How Does YugabyteDB Work?
Because YugabyteDB integrates PostgreSQL code, the easiest way to understand YugabyteDB’s architecture is by first understanding PostgreSQL architecture. Here’s a simplified diagram of a PostgreSQL system:
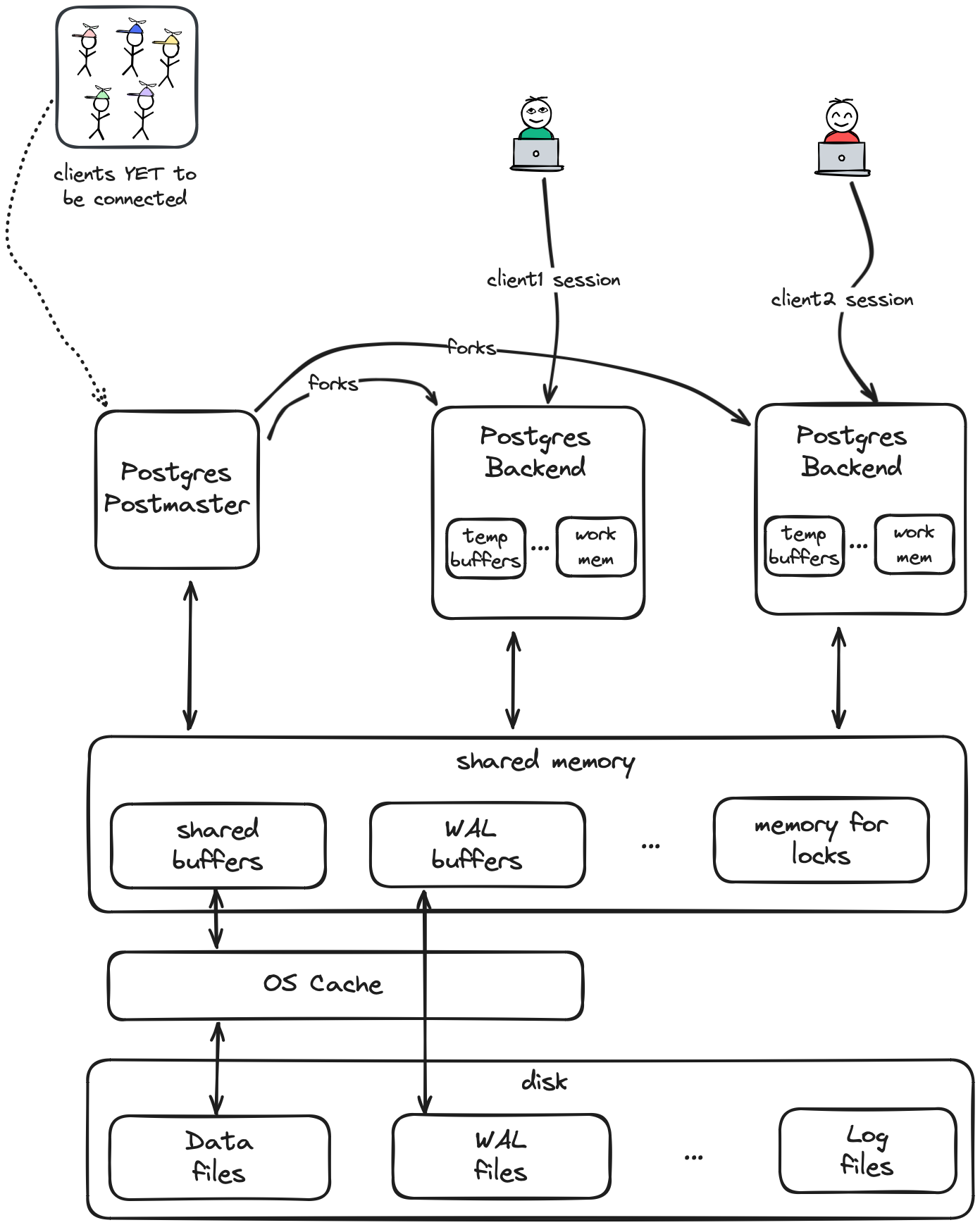
When you start Postgres, you’re starting the Postgres postmaster process, which listens for new client connections. When a client connects, the postmaster forks itself into a Postgres backend process to coordinate that client’s requests. That backend then does query parsing, rewriting, planning, optimization, data retrieval and modification, and other processing, before returning results to the client.
As a single-machine database, Postgres typically uses the local fixed disk or SSD for storage, and coordinates among processes using shared memory. Your data is ultimately stored and indexed on disk in various formats such as b-tree, GIN, and GiST.
When we set out to make YugabyteDB Postgres-compatible, we took a fork of Postgres, and modified all of the operations that use shared memory or storage to instead talk to our LSM- and Raft-based distributed storage and transaction layer. YugabyteDB clusters are multi-node for fault tolerance and scalability. On a tablet server or “tserver” (user-data-containing) node, here’s a simplified diagram of what YugabyteDB looks like:
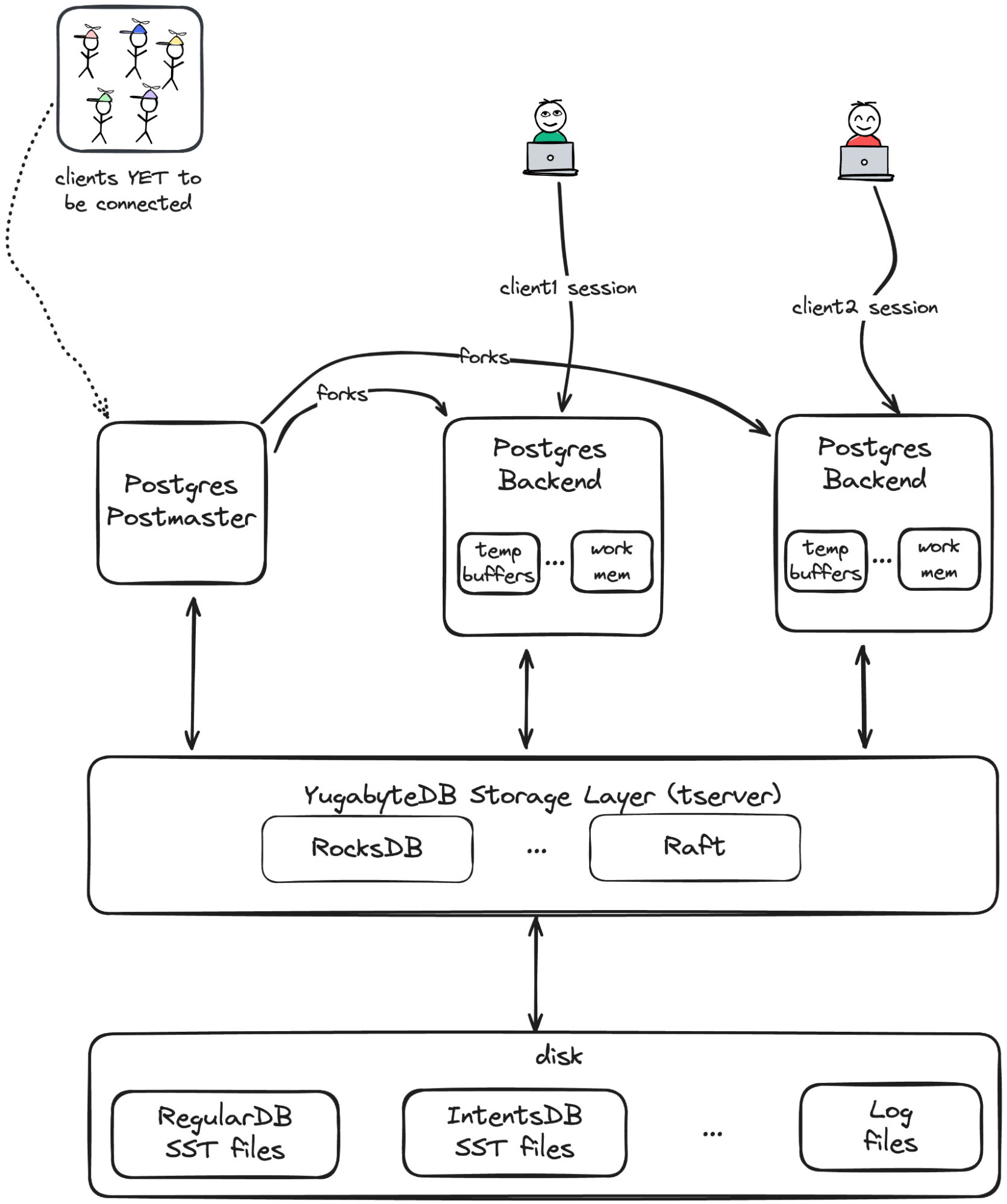
As you can see, each YugabyteDB tserver node has a postmaster, and one Postgres backend per client session, just like Postgres!
Why did we architect YugabyteDB this way? A deep dive into the YugabyteDB architecture and how we got here is its own separate topic. But for a very brief intro, Postgres has some challenges, and we believe our architecture best matches what our users want and need, which is, Postgres at the client interface, with an LSM- and Raft-based distributed storage and transaction layer backing it up. This way they get the best of both worlds:
- Postgres provides access to libraries, drivers, tools, and frameworks built for Postgres, as well as runtime compatibility with the Postgres catalog, error codes, and execution semantics; while
- The LSM- and Raft-based distributed storage and transaction layer provides fault tolerance and horizontal scalability
All of this means that to implement YugabyteDB, we’ve had to do a ton of deep technical work at many levels. We’ve carefully modified Postgres to be distributed, while making sure that we maintain or improve upon its reliability, scalability, availability, and security.
In terms of Postgres code vs. YugabyteDB code, this means there’s a greater fraction of Postgres code (vs. YugabyteDB code) as it gets closer to the client, and increasing amounts of YugabyteDB customization as it gets closer to the storage layer. By the time you get to the tserver, it’s all YugabyteDB code. (But note that YugabyteDB is able to call into Postgres libraries from the tserver process for performance reasons.)
“The Merge”
Now that you understand our high level architecture, and how Yugabyte engineers have spent the past five years combining the Postgres codebase with careful Yugabyte-specific changes and optimizations, it’s time to talk about “the merge.”
While Yugabyte has been improving YugabyteDB, the PostgreSQL Global Development Group released five more versions of PostgreSQL: 12, 13, 14, 15, and 16, and they’re now working on version 17.
All the Postgres code we forked and modified for YugabyteDB has been fair game for them to improve on their side. And improve it they have! But this means that all those Yugabyte-specific changes, interleaved with Postgres changes, need to be carefully examined, sometimes rewritten, and tested thoroughly. That’s part of what those of us on the Postgres 15 team at Yugabyte are hard at work doing right now.
But there’s more. Changes in Postgres aren’t all we have to deal with. Most of the core DB team at Yugabyte is still iterating on and improving the main YugabyteDB code, which is still based on Postgres 11. This is the flip side of the support we continue to deliver—it means even more code changes for the Yugabyte Postgres 15 team to deal with. We have to carefully merge in and test each new change from the YugabyteDB main line into our Postgres 15 branch. As we get closer to releasing a version of YugabyteDB based on Postgres 15, more of the core development team has begun to help us with these ports, which accelerates our progress.
Catching Up, and then Keeping Up
“Why all this Postgres 15 talk? Postgres 15 is already in the past! Why not 16 or even 17?”
Something that might not be obvious is that we want this Postgres version refresh too! Up until a year or so ago when we started working on the refresh in earnest, we had to make the tough call to hold off on the refresh and focus on other features. There’s so much potential in the distributed database space! But finally, we knew it was time, and we set our attention on the refresh. We decided to set the following goals:
- Update to a newer version of PostgreSQL
- Introduce an online upgrade across major Postgres versions, with no downtime, for installations of any scale, with the ability to do online rollback for maximum safety
- An efficient process for integrating Postgres major version upgrades, and a reusable framework for future online upgrades
This is the first time we’re doing a major PG version refresh, so we’ve had to build everything. We started work on the merge before Postgres 15 was released. Right now, it’s coming along nicely, so we’d rather drive the Postgres 15 refresh to completion and get it in our users’ hands as soon as we can, versus taking additional time to integrate Postgres 16 or 17. When we’re done with the Postgres 15 refresh, we’ll start working on the next version. Next time, it will be easier—we won’t need to redo our process for merging, or redesign the live upgrade/rollback.
Would You Like to Know More?
Everyone is doing their part. If you head over to our GitHub repository, you can build the code in our pg15 branch. It passes quite a number of our tests, though obviously not all, or we’d have already released it. Soon, we’ll release a preview binary that you can download and try out.
Also, please sign up for our YugabyteDB Friday Tech Talk (YFTT), “Sneak peek into PostgreSQL 15 compatible YugabyteDB,” on May 24th. Hope to see you there!


