Announcing YugabyteDB 2.14: Higher Performance and Security
July 22, 2022
Our team continues to deliver new innovations, so we are excited to announce our latest stable release—YugabyteDB 2.14, which delivers higher performance, security and YugabyteDB Anywhere enhancements.
YugabyteDB is quickly becoming the cloud native relational database for the world’s most demanding enterprises, driving data-driven innovation in the face of growth, uncertainty, and change.
Highlights of the latest release include automatic certificate lifecycle management with HashiCorp Vault, support for customer NTP (Network Time Protocol) server, and significant performance enhancements, like bulk data import. In addition, several fixes and updates are included to further enhance YugabyteDB Anywhere.
As our latest stable release, YugabyteDB 2.14 delivers updates across three different buckets:
- Brand new features
- Support for innovations announced as part of our preview release, YugabyteDB 2.15
- Stable, generally available features announced earlier
Read on to get all the details of what’s new across these three areas.
Automate Certificate Lifecycle Management For YugabyteDB Using HashiCorp Vault
Certificates are at the nexus of modern, secure communication. One of the challenges many enterprises face today is keeping track of various certificates and ensuring those associated with critical, multi-cloud applications are current and valid.
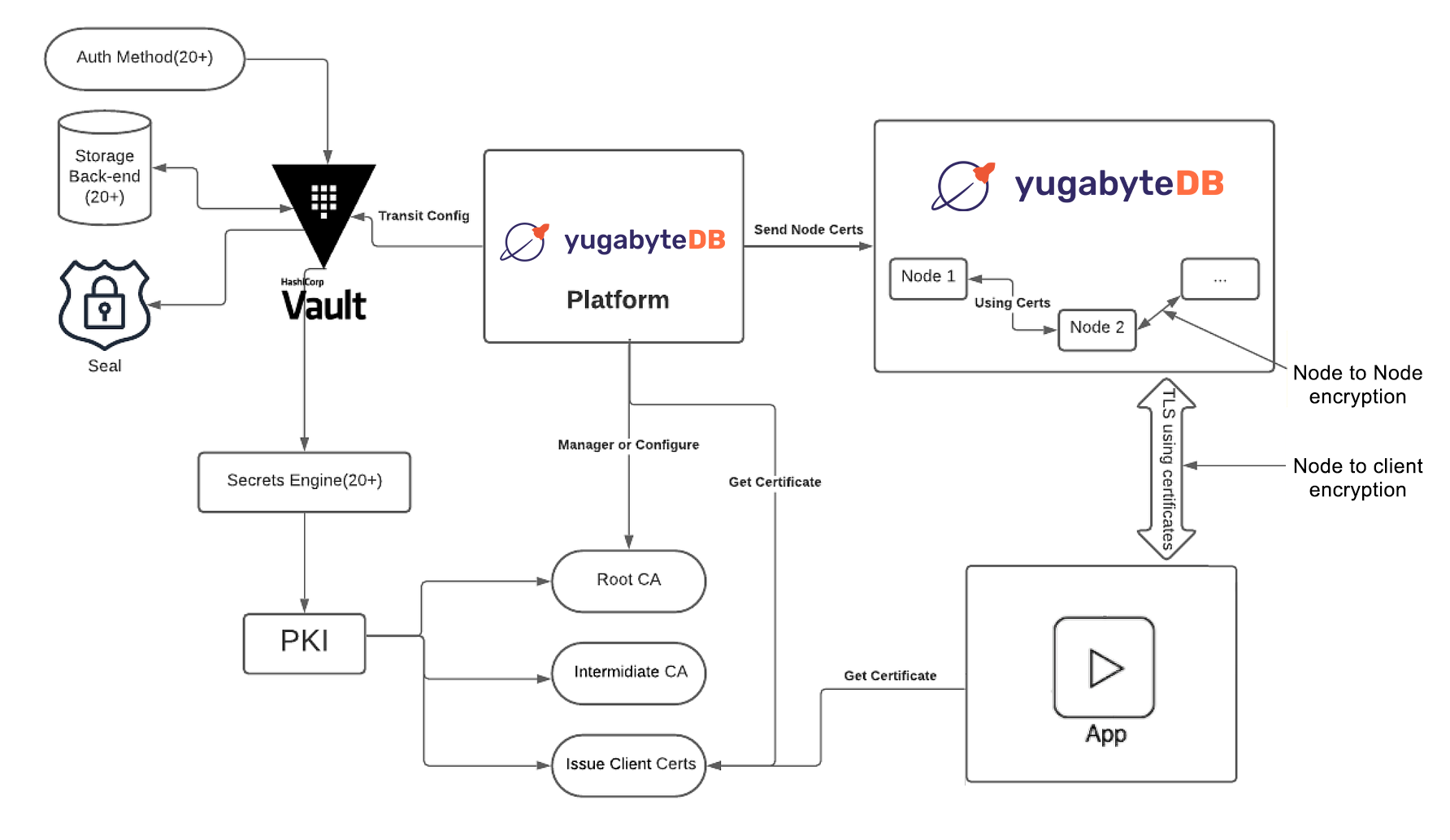
All Yugabyte products use TLS 1.2 for communicating with clusters and digital certificates to verify the identity of clusters. Data in transit is encrypted using TLS and digital certificates to ensure a secure connection to your cluster and to prevent man-in-the-middle (MITM) attacks, impersonation attacks, and eavesdropping.
YugabyteDB Anywhere protects data in transit by using the following:
- Server-to-server encryption for intra-node communication between YB-Master and YB-TServer nodes.
- Client-to-server encryption for communication between clients and nodes when using CLIs, tools, and APIs for YSQL and YCQL
YugabyteDB Anywhere can create a new self-signed certificate, use an existing self-signed certificate, or upload a third-party certificate from external providers. In addition, the platform allows you to add an encryption-in-transit configuration using HashiCorp Vault with a public key infrastructure (PKI) secret engine. Refer to this configuration to enable TLS for different clusters and YugabyteDB instances. You can apply this configuration to node-to-node encryption, client-to-node encryption, or both.
Yugabyte and HashiCorp offer a common blueprint for simplifying certificate management and controlling standardized workflows in multi-cloud environments adaptable to the needs of any enterprise. With our cloud-first and platform-agnostic approach, HashiCorp Vault and YugabyteDB Anywhere make it easy to programmatically manage secrets across cloud providers and platforms.
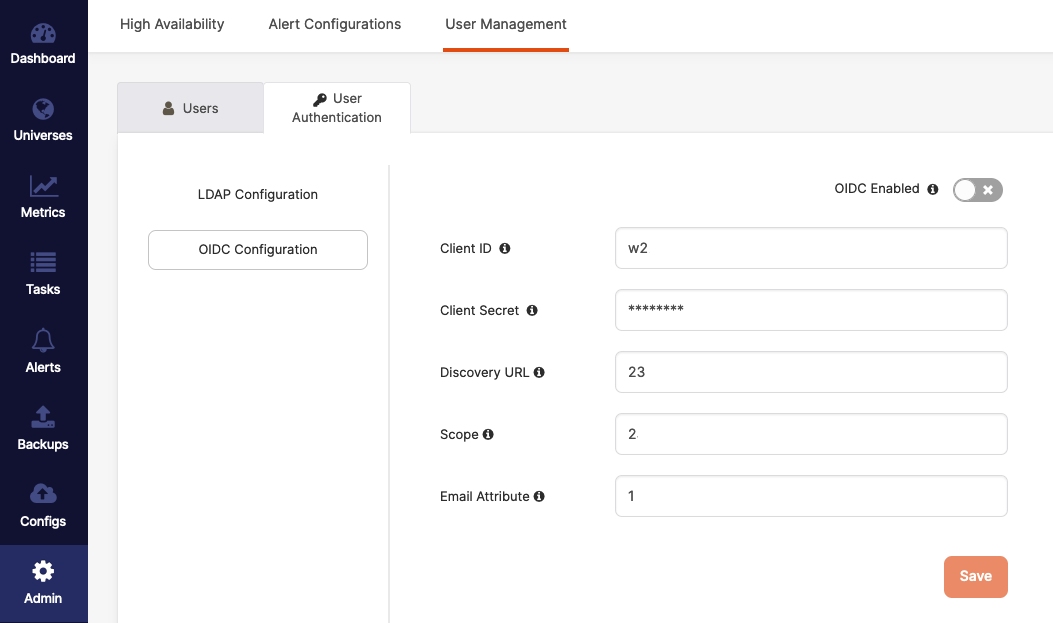
Enable YugabyteDB Anywhere SSO Authentication Via OIDC
OpenID Connect (OIDC) is an authentication protocol that allows client applications to confirm a user’s identity via authentication by an authorization server. You can now use OIDC with YugabyteDB Anywhere to enable single sign-on (SSO) authentication.
Support For Custom NTP (Network Time Protocol) Server
Clock synchronization is a critical requirement for many distributed systems. For YugabyteDB to preserve data consistency, the clock drift and clock skew across different nodes must be bounded. This can be achieved by running clock synchronization software, such as NTP or chrony.
YugabyteDB Anywhere now supports specifying a custom NTP server when creating a Provider or a Universe. Refer to this documentation for details on setting up time synchronization. You can customize the Network Time Protocol server as follows:
- Use the provider’s NTP server to enable cluster nodes to connect to the AWS internal time servers. For more information, consult the AWS documentation, such as Keeping time with Amazon time sync service.
- Manually add NTP Servers to provide your own NTP servers and allow the cluster nodes to connect to those NTP servers.
- Don’t set up NTP to prevent YugabyteDB Anywhere from performing any NTP configuration on the cluster nodes. Ensure that NTP is correctly configured on your machine image for data consistency.
Faster Bulk Data Import Into YugabyteDB
Sometimes databases need to import large quantities of data in a single or a minimal number of steps, commonly referred to as a bulk data import. In a bulk update the data source is typically one or more large files, and the process can often be painfully slow. As a result, it’s important to minimize load time as best as possible.
YugabyteDB 2.14 introduces numerous enhancements to our stable build from our last preview release to dramatically reduce import time and improve overall performance. These updates include all of the following:
- Flush write batches asynchronously
YSQL writes are accumulated in the buffer and flushed to the DocDB once the buffer is full. This allows for multiple buffers to be prepared and responses to be received asynchronously, resulting in an additional degree of parallelism during copy. Below are a couple of tuning parameters. Optimal values for these parameters are based on the instance type, and most scenarios should not require manual intervention. However, advanced users can tune them to get a better degree of parallelism and resource usage during copy operations.- ysql_session_max_batch_size – Sets the maximum batch size for writes that YSQL can buffer before flushing to tablet servers
- ysql_max_in_flight_ops – Maximum number of in-flight operations allowed from YSQL to tablet servers
- Accelerate inserts by skipping lookup of keys being inserted
During bulk load (for example, inserts by Copy command), YugabyteDB now skips the lookup of the key being inserted to speed up the operation. This is similar to the upsert mode that is supported for YCQL. - Optimize memory allocation/deallocation in bulk insert/copy using Protobuf’s arena
Enhanced memory usage compared to before when running a bulk insert or copy command in the PostgreSQL backend would consume about 15 percent of CPU time on memory allocation/deallocation. - Eliminate serialization to the WAL format
When writing data to the RocksDB layer, optimizations were made to eliminate unnecessary steps and wasted work for serializing to the WAL format. - Leverage batches to improve performance
YugabyteDB 2.14 batches the data and chooses an optimal batch size to increase the bulk data import performance. This is because importing a large data set as a single batch can be problematic. - Disable transactional writes during bulk data loading for indexes
Added yb_disable_transactional_writes session improves the latency performance of bulk data loading for index tables, such as when a COPY command is used that goes into the insert write path. - Use new COPY tuning parameters
In addition to all of the above optimizations, YugabyteDB 2.14 adds the following COPY tuning parameters to achieve faster ingestion:SKIP The number of rows to be skipped while importing a file. Default: ‘0’. REPLACE | IGNORE Determines what action to take if an input row as the same unique key values as an existing row in the database table. - Specify REPLACE if you want the input row to replace the existing row in the table. This will be default.
- Specify IGNORE if you want to discard the input row.
DISABLE_FK_CHECK Disables foreign key constraint checks, default is ‘false’ - Monitor status with COPY Progress reporting
Whenever COPY is running, the pg_stat_progress_copy view will contain one row for each backend currently running a COPY command. The below query describes the information that will be reported.yugabyte=# SELECT relid::regclass, command, status, type, bytes_processed, bytes_total, tuples_processed, tuples_excluded FROM pg_stat_progress_copy; relid | command | status | type | bytes_processed | bytes_total | tuples_processed | tuples_excluded ----------+-----------+--------+------+-----------------+-------------+------------------+----------------- copy_tab | COPY FROM | PASS | FILE | 152 | 152 | 12 | 0 (1 row)
Point-in-Time Recovery (PITR) For YSQL is GA
The most efficient way to set up a backup strategy for YugabyteDB is by creating a distributed snapshot schedule based on your retention requirements. A snapshot created as part of the schedule can be used to restore to the moment of its creation. It can also restore to as long as it is kept in-cluster to a point in time representing the latest known working state of the database, using PITR.
PITR in YugabyteDB enables recovery from a user or software error, while minimizing recovery point objective (RPO), recovery time objective (RTO), and the overall impact on the cluster. It works by restoring to the latest known working state of a database, as opposed to a time of snapshot creation.
PITR is particularly useful in the following scenarios:
- DDL errors, such as an accidental table removal
- DML errors, such as the execution of an incorrect update statement against one of the tables
Given these common scenarios, you typically know when the data was corrupted and want to restore to the closest possible uncorrupted state.
With PITR, you can achieve this by providing a restore timestamp. You can also specify the time with precision of up to 1 microsecond. This is far more precision than is possible with regular snapshots, typically taken hourly or daily.
While PITR is primarily based on distributed snapshots, there are two additional requirements that need to be satisfied in order to restore to a specific point in time:
1. Snapshots need to be created as a part of a schedule.
2. Snapshots need to be kept in-cluster. You can still copy them to an external storage, but removing them from the in-cluster storage will prevent you from using PITR.
With YugbyateDB, PITR for YSQL is now generally available.
Automatic Tablet Splitting is GA
Automatic tablet splitting enables you to reshard data in a cluster automatically while online, as well as transparently, when a specified size threshold has been reached.
By default, tablet splitting is not enabled. So, to enable automatic tablet splitting, use the yb-master –enable_automatic_tablet_splitting flag and specify the associated flags to configure when tablets should split.
YSQL Query Optimizer Enhancements
YugaybteDB 2.14 adds several pushdown and scanning improvements for enhanced query performance to our stable release. Updates include changes to the framework for expression pushdowns, new pushdowns for RowComparisonExpression filters, and enables DocDB to process lookups on a subset of the range key.
Smart Scan With Predicate Pushdown
As is often the case with large queries, the predicate filters out most of the rows read. Yet, all the data from the table needs to be read, transferred across the storage network, and copied into memory.
Many more rows are read into memory than required to complete the requested SQL operation. This generates a large number of data transfers, which consumes bandwidth and impacts application throughput and response time.
YugabyteDB 2.14 adds a framework to pushdown predicates to the DocDB storage layer. With this predicate filtering for table scans only the rows requested are returned to the query layer, rather than all rows in a table. YugabyteDB now supports remote filtering of conditions.
For instance, SELECT … WHERE v = 1, if there is no index on v, then this needs to be filtered during execution. This allows filtering on the remote node to minimize data movement and network traffic. The predicate pushdown also occurs in case of DMLs like UPDATE and DELETE.
The beauty of open source software is that the tests are also open. If you want to get an idea of the predicates that can be pushed down, why not grep for Remote Filter on the regression tests, like this?:
curl -s https://raw.githubusercontent.com/yugabyte/yugabyte-db/master/src/postgres/src/test/regress/expected/yb_select_pushdown.out \ | grep "Remote Filter"
Currently, equality, inequality, null test, boolean expressions, CASE WHEN THEN END, and some functions are safe to push down.
New Hybrid Scan Combining Both Discrete and Range Filters
YugabyteDB Query Optimizer uses ScanChoices iterator to iterate over tuples allowed by a given query filter in the DocDB layer. Currently, there are two types of ScanChoices based on the following filter types.
1. Discrete filters (DiscreteScanChoices): These filters of the form `x` IN (a, b, c) AND `y` IN (d,e,f) where a,b,c,d,e,f are all discrete values and `x`, `y` are table columns. In this example, a DiscreteScanChoices would iterate over the space (a,b,c) x (d,e,f).
2. Range filters (RangeBasedScanChoices): These are the filters that express ranges of values such as a <= x <= b where x is a table column and a, b are discrete values. In this example, the RangeBasedScanChoices would iterate over the space (a,….,b).
A shortcoming of having different ScanChoices implementations for different filter types is that it cannot support a mixture of the two filter types. If we consider a filter of the form x IN (a,b,c,d,e,f) AND p <= y <= q, then we are forced to choose between using DiscreteScanChoices and only being able to process the filter for x, or the alternative where we can only process the filter on y.
YugabyteDB 2.14 introduces a new iterator, HybridScanChoices, which supports both types of filters. It treats both filter types as part of a larger class of filters that are conceptualized as lists of ranges, as opposed to lists of values or singular ranges. It converts a filter of the form r1 IN (a,b,c,d) to r1 IN ([a,a], [b,b], [c,c], [d,d]). A range filter of the form a <= r1 <= b is converted into r1 IN ([a,b]).
This unifies the way that filters are interpreted at the DocDB iteration level and allows for much more efficient queries. The feature is enabled by default, but it can also be disabled by setting the runtime GFlag, disable_hybrid_scan, to true.
Get Started and Learn More
We are thrilled to deliver these enterprise-grade features in the latest stable version of our flagship product – YugabyteDB 2.14. As a reminder to anyone confused about our versioning (since we launched YugabyteDB 2.15 last month), our even releases are our latest stable builds and our odd releases are preview releases with cutting-edge enhancements.
In this case, our preview release was ready a bit earlier than the next stable release.
Learn more and try it out:
- YugabyteDB 2.14 is available to download NOW! Installing the release just takes a few minutes.
- Join the YugabyteDB Slack Community for interactions with the broader YugabyteDB community and real-time discussions with our engineering teams.
Register for our 4th annual Distributed SQL Summit, taking place in September.


